Unless you have plenty of cash, you’re going to
experience some pain if you try to share files across machines. No
matter what hat one of us puts on (author, presenter, architect,
developer, or computer scientist), we’re embarrassed by the following
statement: sharing files across machines is incredibly hard. It is; it
shouldn’t be, but it is. Decoding the genome and making robots climb
stairs, that should be hard, but sharing files shouldn’t be.
We wanted to provide a
service where users could upload podcasts that would be converted from
MP3 to WMA. To support the predicted demand, we decided to load balance
the website across two servers. Because users can upload or download a
podcast from any server, a shared storage solution is required.
Figure 1 shows a logical representation of two load balanced web
servers accessing a podcast from a shared storage mechanism.
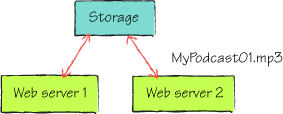
To be honest, you don’t need to
be the greatest architect in the world to draw the solution shown in figure 1. It’s pretty logical, common sense stuff. Two
web servers access a common storage area.
Now you’re thinking, “Why
did they just say it’s common sense, when before they said it was hard?
Get me another book that says it’s easy.” Well, before you start
reaching for Mavis
Beacon Teaches Windows Azure,
check out the following questions. As you think about the possible
answers, you might begin to see why this is a little harder than it
seems to be at first.
Do you have enough
space to store all the files you need?
How do you add more storage capacity?
If a disk crashes, where
does your data go?
Is the storage block
load balanced?
What
if you lose your connection to the block? Is it redundant?
At what point do you max out
your disk, in terms of reading and writing?
How do you evenly
distribute load across all disks?
The good news is that
pretty much all of these problems have been answered and solved already.
You can even implement these solutions in your traditional noncloud
environments today (well, the lead time is probably longer than a day).
The bad news is that the cheap, simple solutions are typically not
scalable or fault tolerant. The solutions that are scalable and durable
are usually expensive. In the Windows Azure BLOB storage service, all
that changes.
Before we look at how easy it is
to store and access files (in a scalable, durable fashion) across
multiple servers in Windows Azure, let’s look at some of the options
outside Windows Azure.
1. Traditional
approaches to BLOB management
Over the next few sections
we’ll look at how you might provide a file storage facility in
traditional ASP.NET web server farms, using our podcasting example.
We’ll specifically look at using the following storage options:
SQL Server
Network share
Distributed File System (DFS)
Network-attached storage (NAS)
Direct-attached storage (DAS)
Storage area network (SAN)
Let’s start with one with the
typical developer solutions to the problem: the database.
SQL Server
Because web servers
typically have access to a shared SQL Server database, you could store
your podcasts in a table. Although this is a common approach used in
many solutions, it’s probably not the best use of your expensive
database server. It’s like racing a truck in a Grand Prix; there are
cheaper, simpler, higher performing, and more appropriate solutions for
storing files.
Unless you’re using a
high-availability technology (such as clustering, mirroring, or
replication), your database server is likely to be a single point of
failure in the system. In figure 1, SQL Server would be represented by the
Storage block (accessed over a typical network connection).
Network Share
Another common approach to
providing a shared filesystem across web servers is to use a shared
network drive that can be accessed by all instances of the website. This
low-cost solution is more lightweight than a database, but it still
introduces a single point of failure. This cheapo solution offers
no redundancy and provides no ability to scale out. In figure 1, an application server with a network share would
also be represented by the storage block.
Now that we’ve looked at some
of the lower-end solutions, let’s take a look at some of the typical
high-scale solutions that are used, starting with Distributed File
Systems.
Distributed File System
(DFS)
Windows Server 2003/2008
provides a technology known as DFS that allows you to create a
peer-to-peer (P2P) filesystem on your network. UNIX/Linux environments
have similar tools. If you use DFS to store podcasts, when a new podcast
is uploaded, a copy of the file is replicated to all other
participating servers. Although this approach requires no new hardware,
it’s complicated to manage and adds extra performance overhead to all
servers involved.
Figure 2
shows a DFS solution with a P2P network between two web servers.
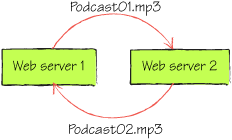
Whenever a file is uploaded
to a web server, it’s automatically replicated to all other servers in
the farms. Using replication ensures that there are no single points of
failure in this solution and that the data is held on multiple machines.
In figure 2, Podcast01.mp3 is uploaded to web server 1 and then
replicated to web server 2; when Podcast02.mp3 is uploaded to web
server 2, it’s then replicated to web server 1.
In figure 3,
the web servers don’t hold the files locally, but use a replicated file
store held in application servers. In this figure, Podcast01.mp3 was
uploaded to app server 1 via web server 1. The file was replicated to
app server 2, and then served up to the client from app server 2 via web
server 1.
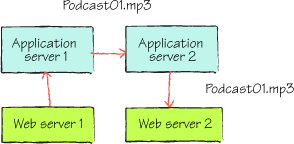
With file replication, any
time a file is uploaded to a server there’s a small delay between the
file being uploaded and it being replicated across all servers. It’s
therefore possible that the web user could be load balanced onto a
server where the file isn’t available (because it hasn’t been replicated
across to that server yet). Although this issue can be alleviated by
using sticky sessions, sticky sessions won’t help if the original server
keels over. Also, using sticky sessions means that incoming requests
won’t be evenly distributed across all web servers.
Now that we’ve looked at some
of the hook-some-machines-together solutions, we’ll look at some of the
dedicated disk array–type solutions that are typically used in the
market.
|
A sticky session occurs when a
load balancer forwards all incoming requests from the same client to
the same server for the period of the session.
|
Network-Attached
Storage (NAS)
A network-attached storage device is a disk array that you can plug into your
network and that can be accessed via a network share. NAS devices are
responsible for managing the device hardware, the filesystem, and
serving files, and can provide varying levels of redundancy, depending
on the device and the number of disks in the array.
Although NAS devices
reduce load from client operating systems by taking responsibility for
file management, they can’t scale beyond their own hardware. NAS devices
can range from being pretty cheap to very expensive, depending on the
levels of scalability, performance, and redundancy that you require from
the device. In figure 1,
the NAS device would be represented by the storage block (connected via
the Ethernet).
NAS devices are used to provide
capabilities similar to those of a file server, rather than being used
as a disk management system in a high-performance application solution.
Direct-Attached Storage
(DAS)
A direct-attached storage device is a disk array that you can plug
directly into the back of your server and that can be accessed natively
by the server. DAS devices are responsible for managing the device
hardware and can provide varying levels of redundancy, depending on the
device and the number of disks in the array.
Because DAS devices
are directly connected to a server, they’re treated like a local disk;
the server is responsible for the management of the filesystem. DAS
devices can support large amounts of data (100 TB or so), can be
clustered (there’s no single point of failure), and are usually
high-performance systems. As such, DAS devices are a common choice for
high-performance applications. The cost of the device can range from
being pretty cheap to very expensive, depending on the levels of
scalability, performance, and redundancy that you require.
Although DAS devices are
great, they’re limited by the physical hardware. When you reach the
physical limits of the hardware (which is quite substantial), you’ll be
able to scale no further.
In figure 1
the DAS device would be represented by the storage block, connected
directly to the servers.
Storage Area Network
(SAN)
Like DAS devices, SANs are
also separate hardware disk arrays; they don’t have their own operating
system, so file management is performed by the client operating system.
SAN devices are represented on
the client operating system as virtual local hard disks that are
accessed over a fiber channel. Because you need your web servers to access
shared data, the SAN would need to support a shared filesystem. In figure 1, the SAN device would be the storage block, attached
to the web servers via fiber channels.
SANs are usually quite
expensive, require specialized knowledge, and are rarely used outside
the enterprise domain. To give you a clue about how expensive they are,
Dell doesn’t even list the price on its website. As for installing and
managing SANs, that’s purely in the domain of the long-haired
sandal-wearing bearded types. We mere mortals have no chance of making
those things work. SAN devices support replication and are highly
scalable (they scale much higher than do DAS devices), fault tolerant,
high performing, and incredibly expensive. Due to their performance,
price, and scalability, this is the solution of choice in the enterprise
space. The rest of us can only dream.
Hopefully we’ve
justified our earlier premise that implementing a file storage solution
today isn’t as easy as it first looks. All the available choices (beyond
a certain size) require extensive IT knowledge, skills, and management,
not to mention large amounts of cash or a tradeoff between capacity,
redundancy, ability to scale, or performance.
This is the state of affairs
with regard to the issues with storing files in traditional on-premises
solutions. Let’s now look at the Windows Azure BLOB storage service and
how it tackles these issues.
