Staging Attachments
Up to this point,
we have programmed the stager to generate files for channel cover pages
and postings. Let’s proceed to stage links to resources, images, and
other attachments within these pages. Here’s the game plan:
We will first scan through each channel cover page and posting for a list of all attachments.
We will add the URL of any attachments found to an ArrayList.
Once
we have collected a list of attachments for each channel cover page or
posting, we will proceed to download and stage them using the same
technique for downloading and generating static files that we used
earlier.
Collecting a List of Attachments to Download
The first step in the
process is to scan all channel cover pages and postings for attachments.
Earlier, we declared an ArrayList class variable, m_AttachmentUrls, which contains a list of attachment URLs to be downloaded and staged.
[STAThread]
static void Main(string[] args)
{
m_AttachmentUrls = new ArrayList();
. . . code continues . . .
}
Scanning Pages for Attachments
Since we are already scanning postings in the ProcessPageAndGetAttachments() method, let’s enhance it to look for attachments.
Information about attachments is embedded within HTML tags. It can be found in:
The href attribute of the <base>, <a>, and <link> tags.
The src attribute of the <script>, <xml>, <img>, <embed>, <frame>, and <iframe> tags.
The background attribute of the <body>, <td>, <th>, <table>, and <layer> tags.
For each tag, we
will look for the attribute that contains the attachment and extract its
URL. For example, if the content contains an image tag:
<img border=0 src="/nr/rdonlyres/0/tree.gif">
We will grab the entire <img> tag and extract the value of the src attribute, which contains the URL of the attachment. The helper function that searches for attachments is called FindAttachment() (defined later). Add calls to FindAttachment() to the ProcessPageAndGetAttachments() method as shown below.
private static void ProcessPageAndGetAttachments(string encodingName,
ref byte[] buffer)
{
. . . code continues . . .
// Replace special characters to make it easier to find
content = content.Replace("\t"," ").Replace("\n"," ").Replace("\r", " ");
// Get attachments
// Start searching for attachments!
FindAttachment(ref content, "base", "href");
FindAttachment(ref content, "a", "href");
FindAttachment(ref content, "link", "href");
FindAttachment(ref content, "script", "src");
FindAttachment(ref content, "xml", "src");
FindAttachment(ref content, "img", "src");
FindAttachment(ref content, "frame", "src");
FindAttachment(ref content, "iframe", "src");
FindAttachment(ref content, "embed", "src");
FindAttachment(ref content, "body", "background");
FindAttachment(ref content, "td", "background");
FindAttachment(ref content, "th", "background");
FindAttachment(ref content, "table", "background");
FindAttachment(ref content, "layer", "background");
}
Of course, depending on
the tags used by authors, the list above may not be exhaustive. Feel
free to add more tags and attributes to the list.
The FindAttachment() method accepts three input parameters:
input: The HTML of the page being scanned
tagName: The tag to look for (e.g. <img>)
attribute: The attribute that stores the attachment’s URL (e.g. src)
It looks for all instances of the tag in the content. For example, when it finds an <img> tag, it extracts the URL from its src attribute using the ExtractUrlFromTag() method (defined later).
If a URL has been successfully extracted, it is added to the list of URLs using the AddToUrlList() helper function (also defined later).
<base> tags are handled separately. Earlier, we discussed how <base> tags are injected into all postings by the RobotMetaTag. The browser interprets all relative links by pre-pending the value in its href attribute to them. If FindAttachment() sees a <base> tag, it calls the SetBaseUrl() routine, which stores the extracted URL in the m_LocalBaseUrl variable for use later when downloading relative links.
Add the FindAttachment() method to the class:
private static void FindAttachment(ref string input, string tagName,
string attribute)
{
// Pattern that extracts all tags with the specified tagName
string pattern = @"<\s*" + tagName + @"\b[^>]*>";
// The regular expression that finds all the tags
Regex findTags = new Regex(pattern, RegexOptions.IgnoreCase);
foreach (Match tag in findTags.Matches(input))
{
// Extract the URL from each tag based on the specified attribute
string url = ExtractUrlFromTag(tag.Value, attribute);
// We have successfully extracted a URL
if (url != "")
{
// Handle <base> tags
if (tagName == "base")
{
// Set the base path for pages that have it defined.
SetBaseUrl(url);
}
else
{
// Add the URL to the array list
AddToUrlList(url);
}
}
}
}
When the FindAttachment() method encounters a tag it’s looking for, it calls the ExtractUrlFromTag()
method to pull out the attachment’s URL. Once it finds the attribute
within the tag, it checks to see if the URL is stored between double
quotes or single quotes and extracts it. Should the method be unable to
find the attribute (perhaps the attribute can’t be found), it returns an
empty string.
// Get the URLs from a specific property of the current html tag
static string ExtractUrlFromTag(string tagValue, string attribute)
{
// e.g. of input: <img src="http://www.tropicalgreen.net/myimage.jpg">
string url = "";
// Pattern to match the attribute
string pattern = attribute + @"\s*=\s*(\""|')*[^(\""|')>]*";
// After extraction, the input string will be:
// src = "http://www.tropicalgreen.net/myimage.jpg"
Regex findAttribute = new Regex(pattern, RegexOptions.IgnoreCase);
Match att = findAttribute.Match(tagValue);
if (att.Success)
{
url = att.Value;
// Get the position of the "=" character
int equal = url.IndexOf("=");
// Get only the URL
url = url.Substring(equal + 1);
// Trim spaces
url = url.Trim();
// Remove the opening double quotes or single quote
if (url.StartsWith("\"") || url.StartsWith("'"))
{
url = url.Substring(1);
}
// Remove the closing double quotes or single quote
if (url.EndsWith("\"") || url.EndsWith("'"))
{
url = url.Substring(0, url.Length-1);
}
}
return url;
}
The SetBaseUrl() routine handles <base> tags. <base> tags are typically embedded between <head> tags. Here’s an example of a <base> tag:
<base href="http://tropicalgreen/TropicalGreen/Templates/Plant.aspx?
NRMODE=Published&NRORIGINALURL=%2fPlantCatalog%2fAloeVera%2ehtm&NRNODEGUID=%7b
569D1CCA-9A9D-4C43-B0C3-DB1AACD98684%7d&NRCACHEHINT=NoModifyGuest">
Notice that the URL of the template file is stored in its href attribute. Browsers add this href value to all relative links found within the page. In the SetBaseUrl() method, we will extract the value of the href attribute of the <base> tag and store it in the m_LocalBaseUrl variable. Later on, we will use this value to construct the actual URLs of relative attachments found on the page.
private static void SetBaseUrl(string url)
{
if (url.IndexOf("?") > -1)
{
url = url.Substring(0,url.IndexOf("?"));
}
if (!url.EndsWith("/"))
{
object o = cmsContext.Searches.GetByUrl(url);
if (o != null)
{
if (o is Channel)
{
url += "/";
}
}
}
url = url.Substring(0,url.LastIndexOf("/")+1);
if (url.StartsWith("http://"))
{
url = url.Remove(0,7); // remove "http://"
url = url.Remove(0,(url+"/").IndexOf("/"));
}
m_LocalBaseUrl = url;
}
Storing Information about the Attachments to a List
Once an attachment is
found, we record its URL and format type to an ArrayList. Before we do
so, we prepare the URL and run several checks to see if it’s valid. We
will do all that in the AddToUrlList() method.
First, bookmarks are removed. Examples of bookmarks include “Back To Top”-type hyperlinks that typically look like this: <a href="somepage.htm#Top">.
Since bookmarks are place markers that point to locations within the
page itself, we can shave them off the URL and still be able to download
the page. Add the AddToUrlList() method to the class:
private static void AddToUrlList(string url)
{
// Remove internal bookmarks from the URL
string origUrl = url;
if (url.IndexOf("#") >= 0)
{
url = url.Substring(0, url.IndexOf("#"));
}
}
All relative URLs have to be
converted to absolute URLs so that they can be downloaded and staged.
We use the value stored in the <base> tag, if one has been found.
private static void AddToUrlList(string url)
{
. . . code continues . . .
// Convert Relative URLs to Absolute URLs
if (!url.StartsWith("/"))
{
url = m_LocalBaseUrl + url;
}
}
Next, we remove host
information from the URL. This makes it easier for us to process the
rest of the URL later, especially when attempting to check to see if the
attachment is a channel item.
private static void AddToUrlList(string url)
{
. . . code continues . . .
// Remove host information from the URL
if (url.StartsWith(m_SourceHost))
{
url = url.Remove(0, m_SourceHost.Length);
}
}
We will only add URLs that are valid. Valid URLs:
Will not contain single or double quotes.
Will not link to other ports (such as http://localhost:81/somepage.htm) or other domains. Since we have removed host information earlier on (which leaves us with URLs such as :80/ or :80/somepage.htm), we simply look for the presence of a colon to check for URLs that have a port number.
Will
not contain querystring parameters. We will enforce that by ensuring
that the URL does not contain a question mark. The reason for not
processing pages with querystrings is because they are likely to be
dynamic pages (*.aspx or *.asp) and static snapshots of these pages aren’t able to process querystring parameters.
private static void AddToUrlList(string url)
{
. . . code continues . . .
// Check URLs to see if they are valid
bool isValidUrl = true;
string reason = "";
if ((url.IndexOf("'") >= 0 || url.IndexOf("\"") >= 0)
|| url.IndexOf(":") >= 0 || url.IndexOf("?") >= 0)
{
// URL is invalid
isValidUrl = false;
reason = "Ignoring invalid url or url from external domain";
}
}
We will also check to see if the URL belongs to a posting or channel cover page that will be staged by the CollectChannel()
method defined earlier. We could leave out this check and have the
stager generate these pages as many times as they appear, but remember
that the smaller the number of files staged, the faster the process!
Notice that we used a helper function, EnhancedGetByUrl(). It basically does the same job as the Searches.GetByUrl() method, but includes several improvements as we shall see later.
private static void AddToUrlList(string url)
{
. . . code continues . . .
// Check to see if the URL refers to a channel item that
// will be staged
if (isValidUrl)
{
ChannelItem ci = EnhancedGetByUrl(url) as ChannelItem;
if (ci != null)
{
if (ci.Path.ToLower().StartsWith(m_StartChannel.ToLower()))
{
isValidUrl = false;
reason = "";
}
}
}
}
As
part of keeping the number of attachments in the list as small as
possible, before adding the attachment’s URL to our list, we will check
if the URL has been recorded before. If it has, we won’t add it again.
Finally, the URL has been
adjusted, verified, and is ready to be added to the list. This is the
easy part. Simply add the URL and the format of the attachment to the
ArrayList. If the URL has been rejected, we will record it in the log
file together with the reason for not staging it.
private static void AddToUrlList(string url)
{
. . . code continues . . .
if (isValidUrl)
{
url = url.Replace("&","&");
if (!m_AttachmentUrls.Contains(url))
{
m_AttachmentUrls.Add(url);
}
}
else
{
if (reason != "")
{
WriteToLog(reason + " : " + origUrl);
}
}
}
Enhancing the Searches.GetByUrl() Method
When the “Map Channel
Names to Host Headers” option is turned on, the top-level channel name
becomes a host header. For example, if the channel directly beneath the
root channel is named tropicalgreen, the URL of the channel becomes http://tropicalgreen, instead of http://localhost/tropicalgreen. This feature allows a single MCMS server to host multiple websites, each with a different host header name.
|
To check whether the
“Map Channel Names to Host Headers” option is set to “Yes” or “No”,
open the MCMS Server Configuration Application and check the value of
this option in the General tab.
|
|
Note that the “Map Channel Names to Host Headers” feature is not available in MCMS Standard Edition.
|
However, the Searches.GetByUrl() method does not work reliably for sites where channel names are mapped to host header names. When the Searches.GetByUrl() method is fed the URL of, say, the top-level channel, http://tropicalgreen, we would expect it to return an instance of the tropicalgreen channel. The trouble is it returns a null object instead. This is because an issue with the Searches.GetByUrl() method causes it to expect the input URL to be http://localhost/tropicalgreen regardless of whether the “Map Channel Names to Host Headers” option is set to “Yes” or “No”. We will create the EnhancedGetByUrl() method to get around this problem.
The EnhancedGetByUrl()
method first checks to see if the “Map Channel Names to Host Headers”
option is set to “Yes” or “No”. It does so by looking at the published
URL of the root channel. When “Map Channel Names to Host Headers” has
been set to “Yes”, the root channel’s URL will be http://Channels. Otherwise, it will simply be /Channels/.
If the “Map Channel Names to Host Headers” option is set to “Yes”, we will convert the input URL to a path and use the Searches.GetByPath() method to retrieve an instance of the channel item. For example, if the URL is http://tropicalgreen/plantcatalog, the routine converts it to the channel’s path: /Channels/tropicalgreen/plantcatalog. Add the following code to the class:
static ChannelItem EnhancedGetByUrl(string url)
{
if (IsMapChannelToHostHeaderEnabled())
{
// Remove "http://" from the URL and remove any trailing forward slashes
string hostName = m_SourceHost.ToLower().Replace("http://","").Trim(new
Char[] {'/'});
// Convert the URL to a path
string Path = HttpUtility.UrlDecode(url);
Path = Path.Replace("http://","/Channels/");
if (!Path.StartsWith("/Channels/"))
{
Path = "/Channels/"+hostName+Path;
}
if (Path.EndsWith(".htm"))
{
Path = Path.Substring(0,Path.Length - 4);
}
if (Path.EndsWith("/"))
{
Path = Path.Substring(0,Path.Length - 1);
}
return (ChannelItem)(cmsContext.Searches.GetByPath(Path));
}
else
{
return cmsContext.Searches.GetByUrl(url);
}
}
static bool IsMapChannelToHostHeaderEnabled()
{
return (cmsContext.RootChannel.UrlModePublished == "http://Channels/");
}
Downloading the Attachments
Once
we have collected a list of attachments for each channel cover page or
posting, we are ready to generate static copies of them. To do so, we
will call a helper function DownloadAttachments() at two points in the CollectChannel() method:
Add the calls to the DownloadAttachments() method as shown in the highlighted portions of the code below:
static void CollectChannel(Channel channel)
{
// Download the channel itself
WriteToLog("Info: Downloading Channel: " + channel.Path);
Download(GetUrlWithHost(channel.Url), channel.Path.Replace(
m_StartChannel,"/"),
m_DefaultFileName, EnumBinary.ContentPage);
// Download all attachments in the cover page or channel rendering script
DownloadAttachments();
// Download all the postings within the channel
foreach (Posting p in channel.Postings)
{
WriteToLog("Info: Downloading Posting: " + p.Path);
Download(GetUrlWithHost(p.Url), channel.Path.Replace(m_StartChannel,"/"),
p.Name, EnumBinary.ContentPage);
// Download all attachments in the posting
DownloadAttachments();
}
foreach (Channel c in channel.Channels)
{
CollectChannel(c);
}
}
The DownloadAttachments() method loops through each element of the m_AttachmentUrls array and extracts the attachment’s path and file name from its URL. The Download() method that we defined earlier is called to stage each attachment as a static file.
private static void DownloadAttachments()
{
for (int i = 0; i < m_AttachmentUrls.Count; i++)
{
string path = m_AttachmentUrls[i].ToString();
string[] arrPath = path.Split('/');
string fileName = arrPath[arrPath.Length - 1];
path = "";
for (int j = 0; j < arrPath.Length - 1; j++)
{
path += arrPath[j] + "/";
}
Download(GetUrlWithHost(m_AttachmentUrls[i].ToString()), path, fileName,
EnumBinary.ContentBinary);
}
m_AttachmentUrls.Clear();
}
The
paths of all attachments and images will follow that of the original
page. As long as you do maintain the hierarchy of the staged folders,
for instance staging from http://SourceServer/tropicalgreen/ to http://DestinationServer/tropicagreen/, the URLs within each page will not need to be updated.
Running the DotNetSiteStager
The DotNetSiteStager
application is complete! Run the application to stage static versions of
your site. We ran the stager on the Tropical Green website and here’s a
snapshot of the folders and files that were staged:
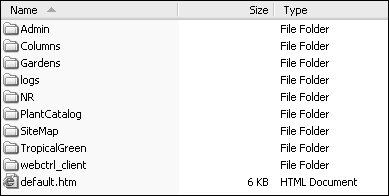
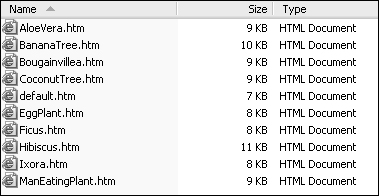
Within each folder are static versions of postings and attachments. For example, the PlantCatalog folder contains HTML snapshots of each plant posting:
The static pages generated by DotNetSiteStager include the Web Author Console. How can I remove it?
DotNetSiteStager takes a
snapshot of each page as seen by the ‘Stage As’ user. If the Web Author
Console is included in each generated page, this most probably means
that the ‘Stage As’ user has been given authoring rights. To prevent the
Web Author Console from being included in the staged files, use an
account that has only subscriber rights to the channels staged. In
addition, staging pages with the Console may result in HTTP 500 errors
as additional HTTP header information is required to download and
generate them correctly.
Suggested Improvements
There are various enhancements that could be made to the DotNetSiteStager application. Here are a few suggestions:
Staging links
found within attachments. For example, if an HTML attachment contains
links to cascading stylesheets or linked script files, the stager could
be intelligent enough to pick these up and stage them too.
Handle
client-side redirection. This is required to ensure that links to
elements that do a server-side redirect (such as channel rendering
scripts, HTTP modules, controls, and template code) are simulated with
client-side HTTP redirection using meta tags.
Remove
ViewState information in the staged pages, if there is any. ViewState
information preserves the state of a page across postbacks. As static
pages do not perform postbacks, we can safely remove it. To do so, you
could use a regular expression to remove the <input name="__viewstate"> tag from each generated page.
The
entire .NET stager tool could be coded to work via a web service. In
this way, you could invoke the staging of static pages from a remote
computer.
A more
sophisticated and complete version of DotNetSiteStager that, among other
things, handles client-side redirection and the staging of attachments
linked from resources (not channel items) can be found on GotDotNet, The
Microsoft .NET Framework Community, at the following address:
http://www.gotdotnet.com/Community/UserSamples/Details.aspx?SampleGuid=153B8D20-EE51-4105-AAEF-519A7B841FCC
