The first question usually asked about SQL Azure is:
"Is SQL Azure really SQL Server 2008, or is it something else?" The
answer is a little of both. Retail editions of SQL Server 2008 include
Web, Workgroup, Standard, Enterprise, and Datacenter. SQL Azure is
another edition of SQL Server 2008, and shares many of the same features
as the other editions.
Development on SQL Azure
is nearly identical to developing on SQL Server, with most commands and
objects either fully or partially supported. However, because SQL Azure
is a service, there are significant differences in how SQL Azure and on
premises SQL Server are managed. At the time of writing, additional
components such as SQL Server Reporting Services (SSRS) and SQL Server Analysis Services (SSAS)
are not supported on SQL Azure, although on premises installations of
SSRS and SSAS can consume data from SQL Azure databases. SQL Azure
Reporting was announced at PDC '10, and is expected to be available in
2011.
Replication is not
available in SQL Azure (don't panic, our SQL Azure databases are
maintained behind the scenes in multiple copies, with automatic
failover). Service Broker is another SQL Server feature currently not
supported by SQL Azure. Depending on the needs of the application, a
queue and worker role may be able to replace the Service Broker.
Microsoft promises to introduce additional SQL Azure services soon, so
we may one day see these missing features in the cloud.
SQL Azure can be used
individually or in conjunction with other Azure services. In either
case, local applications can connect directly to SQL Azure. When used in
conjunction with Windows Azure services, local applications can also
access data stored in SQL Azure via web services.
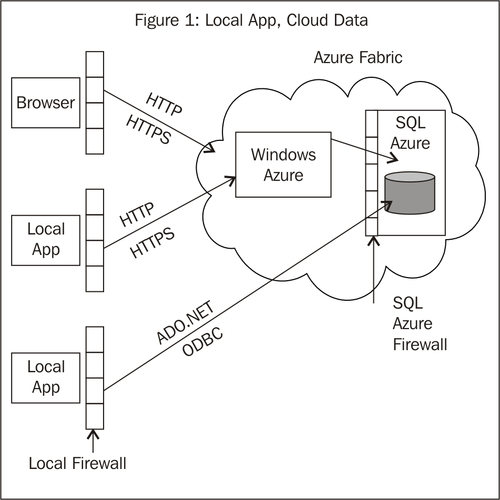
Perhaps the most common method
for accessing data in SQL Azure is to use a Windows Azure Web Role or
Worker Role. Using a Web Role is similar to an ASP.NET website backed by
SQL Server.
Microsoft touts five key benefits in using SQL Azure:
We'll use these five benefits as the outline for our overview of SQL Azure.
Manageability
The biggest differences
in managing SQL Azure and an on premise SQL Server is that we no longer
have to purchase or maintain physical hardware. By design, Microsoft has
separated the physical administration tasks from the logical
administration tasks, and assumes responsibility for the physical
management of SQL Azure. As Microsoft describes it (http://msdn.microsoft.com/en-us/library/ee336241.aspx):
[t]his approach helps SQL
Azure provide a large-scale multi-tenant database service that offers
enterprise-class availability, scalability, security, and self-healing.
Microsoft has also removed
the ability to control physical resources of SQL Azure. For example,
there is no option to change either the hard drive or file group in
which a database resides. This makes sense, as the file system is not
accessible to us. Likewise, the backup and restore options are also not
available. Likewise, there is no option to attach a database in SQL
Azure.
As Azure has its own methods of
load balancing and resource governing, the new Resource Governor is
blocked, as are any T-SQL or DDL statements that modify or access the
physical resources.
On the downside, a couple of
very powerful tools we've come to rely upon are not available. Neither
SQL trace flags nor the Database Tuning Advisor are available to us,
which will make debugging and performance tuning more complicated.
Managing SQL Azure
SQL Azure databases are
managed through the SQL Azure portal, which is part of the same portal
as other Azure services, if we're using any. We use the portal to create
or delete databases, and to manage database level security, but we use
other tools to manage the contents of each database.
Similarities
Each SQL Azure account is provided a single instance of SQL Azure, which can contain multiple databases.
As in SQL Server 2008, we
administer our databases, as well as the roles and user accounts. All
connections to SQL Azure run through port 1433, same as SQL Server. If
an on premise client application needs to connect directly to SQL Azure,
firewalls on both ends need to have port 1433 opened. By default,
external connections to a SQL Azure instance are blocked for security
reasons. In order for our applications or management tools to connect to
SQL Azure, we must whitelist certain IP ranges using the SQL Azure
portal.
Differences
Most system-stored procedures are not supported (http://msdn.microsoft.com/en-us/library/ee336237.aspx), no system tables are supported, and SQL Azure has limited support for system views (http://msdn.microsoft.com/en-us/library/ee336238.aspx).
Databases are sold in two
editions a Web Edition, which has a maximum size of 5 GB, and a Business
Edition, which has a maximum size of 50 GB. As we can expect, pricing
is a tiered structure based on database size; the current pricing can be
found at http://www.microsoft.com/windowsazure/pricing/.
Security administration such as creating users and allowing access to
databases is handled in the SQL Azure portal. As Microsoft handles the
entire infrastructure, patches and service packs are no longer a part of
our lives; nor are log files filling up drive space, as logs are not
counted as part of the space calculation. However, it is possible a
service pack upgrade could break some production code, and this is one
of the criticisms levelled at SQL Azure by career database
administrators (DBAs). Several noted DBAs discuss their concerns (http://www.sqlmag.com/article/services/considering-sql-azure.aspx), notably:
The lack of a
backup option prevents restoring the database to a previous time. If
someone accidentally deletes a table, there is no way to retrieve it.
Some of the more useful system stored procedures are not available, which can make troubleshooting more complicated.
The data are stored on
hardware in a network that is physically out of the DBA's control. DBAs
are tasked with keeping data safe and secure, and often that involves
direct administration of the physical servers and working closely with
network managers. With SQL Azure, uptime and security are the
responsibility of a faceless group of people, and DBAs are reluctant to
make guarantees about anything they cannot control.
Although there is not a true
backup option, SQL Azure supports a database copy functionality, not
surprisingly named SQL Azure Database Copy. The database can be copied
to the same Azure server, or a different Azure server, and the copy can
be scheduled. Documentation about the database copy functionality can be
found at http://msdn.microsoft.com/en-us/library/ff951624.aspx.
The SQL Azure team addressed the issue of patching SQL Azure in a blog post at http://blogs.msdn.com/b/sqlazure/archive/2010/04/30/10004818.aspx.
As SQL Azure keeps three redundant copies of our data on three separate
instances, and only a single instance would be patched at one time,
failover and redundancy are still in place during an update.
SQL Server Management Studio
2008 R2 supports direct connections to SQL Azure, but because
connections to SQL Azure are solely on port 1433, the SQL Browser is not
available.
High availability
Another feature of SQL
Server missing in SQL Azure is replication. Without the options for
backup/restore or replication, how can our data be highly available? Two
concepts that we hear most often with regards to SQL Azure are
"built-in data protection" and "self healing".
Built-in data protection:
The built-in data protection involves our data being replicated
immediately and automatically across several physical machines. This
replication is part of the SQL Azure platform, and we needn't set it up,
neither do we have any control over it. Note that this is not the same
replication as SQL Server Replication, but is a different mechanism for
duplicating our data.
Self healing:
SQL Azure is self healing in that if a physical machine should become
unavailable, there is automatic failover to another machine containing
all of our data. As this failover machine is also in the Azure Fabric,
the failover process is invisible to clients and no reconfiguration is
necessary should a secondary machine come online.
Having high availability
does not mean we can be reckless with resource utilization, and we
cannot assume a connection will always remain open. In order to be fair
to all tenants of SQL Azure, a SQL Azure connection may be closed for a
number of reasons, including the following:
Excessive resource utilization
Long-running queries
Long-running transactions
Connections being left idle for a longer duration
Server failures and the resulting failover
As developers, we cannot assume our connection will always be open, and we'll need to compensate accordingly.
Another way that our data are highly available is due to the scalability aspects of SQL Azure.
Scalability
Should our
applications become an overnight sensation, we can add additional
storage capacity via the SQL Azure portal. Database capacity can be
increased on the fly, up to the subscription limits. For example, a Web
Edition database comes in two sizes 1 GB and a 5 GB. For a new site, a
database of the size 1 GB is more than sufficient and it also has less
cost per month compared to the 5 GB database. As demands grow, we can
upgrade to the 5 GB database, by simply using the ALTER DATABASE command to increase the maximum database size.
The load balancing aspects of the Azure Fabric help ensure client requests are answered and met in a timely fashion.
Relational data model
Windows Azure tables and
blobs are useful, but they'll only get us so far with a complex
data-driven application. For one of these, we need to rely on a
relational database provider; SQL Azure is a true RDBMS in the cloud.
Familiar development model
SQL Azure is based on SQL
Server need we say more? Actually, yes, a lot more.To start with, SQL
Azure supports T-SQL and returns a tabular data stream, the same as SQL
Server; so, in many cases, only the connection string needs to be
changed (after the database is deployed, of course). We can connect our
applications to SQL Azure using familiar drivers, including
System.Data.SqlClient, SQL Server 2008 and 2008 R2 ODBC Drivers, and SQL
Server 2008 PHP driver (OLEDB is not supported, which is a
consideration when using SSIS). Tools we can connect with include SQL
Server 2008 R2 Management Studio, SQLCMD, Visual Studio 2010, and a
number of third-party tools. To transfer data to SQL Azure, we can use
SQL Server Integration Services (SSIS), BCP.exe,
System.Data.SqlClient.SqlBulkCopy, or INSERT statements.
If we don't want to
utilize direct connections to the database, we can instead use ADO.NET,
ASP.NET, or ADO.NET Data Services in our applications to access data in
SQL Azure.
Important to realize in this
discussion is the term "familiar", rather than "identical". Because SQL
Azure is a managed service, some management features have had
functionality reduced or have been removed completely. T-SQL is the
query language used by SQL Azure, but there are three levels of support
for T-SQL commands complete, partial, and unsupported. Further details
on T-SQL support can be found at http://msdn.microsoft.com/en-us/library/ee336250.aspx.
As we discuss similarities and differences, the discussion of
differences is going to seem to outweigh the similarities. We don't need
an in-depth discussion on similarities, as these should be familiar
concepts and tools. Keep in mind the discussion is comparing SQL Azure
and SQL Server 2008.
What's the same in SQL Azure?
One of Microsoft's goals in
creating SQL Azure was to provide an environment for experienced SQL
Server developers to utilize their skills. Here, we review where SQL
Azure is similar to what we already know about it.
Data types
Nearly all data types are supported, including XML and geography. For a table of supported data types, visit http://msdn.microsoft.com/en-us/library/ee336233.aspx.
The addition of the geographic and geometric data type around the MIX10
timeline raised hopes that the .NET CLR will be supported, as these
data types rely on the CLR.
Database objects
As we'd expect, database tables are the same, including table variables and local temporary tables. Supported table features include:
SQL Azure also fully supports views, stored procedures, and user-defined functions.
Fully supported T-SQL commands
For a complete overview of supported T-SQL commands, refer to the MSDN documentation at http://msdn.microsoft.com/en-us/library/ee336270.aspx. Some of the most common T-SQL commands supported by SQL Azure are mentioned next, but this is not the complete list.
|
Select clause/@local_variable
|
From
|
|
Begin_Transaction
|
Group By
|
|
Begin…End
|
Having
|
|
Cast
|
Order By
|
|
Convert
|
Top
|
|
Ceiling
|
Try...Catch
|
|
Coalesce
|
Where
|
|
Delete
|
Commit/Rollback/Save Transaction
|
|
Declare Cursor
|
While
|
|
Delete
| |
|
Truncate Table
| |
|
If...Else
| |
Partially supported T-SQL commands
Partial support for T-SQL
commands indicates that the SQL Azure syntax does not support all the
arguments or options that the SQL Server 2008 syntax does. For instance, CREATE TABLE in SQL Server 2008 has a parameter to choose the filegroup (usually ON PRIMARY);
because filegroups are not selectable in SQL Azure, the filegroup
argument is not supported. There are additional options not supported by
the SQL Azure version of CREATE TABLE, and the official MSDN documentation should be consulted if there are questions about the support for a particular command.
The following table
summarizes some of the more common T-SQL commands with partial support
in SQL Azure. For the complete list of partially supported T-SQL
commands, read the MSDN article at http://msdn.microsoft.com/en-us/library/ee336267.aspx.
|
Create/Alter Function
|
Grant/Deny/Revoke Database Permissions
|
|
Create/Alter/Drop Index
|
Execute
|
|
Create/Alter/Drop Table
|
Create/Alter User
|
|
Create/Alter/Drop Trigger
|
Alter Login
|
|
Create/Alter View
|
Enable/Disable Trigger
|
SQL Server built-in functions
As with T-SQL
commands, the intrinsic functions of SQL Server 2008 have varying
degrees of support in SQL Azure. For full details regarding SQL Azure
support of SQL Server 2008 intrinsic functions, consult the official
MSDN documentation at http://msdn.microsoft.com/en-us/library/ee336248.aspx.
|
Function type
|
Support
|
Examples of supported statements
|
|---|
|
Aggregate
|
Full
|
AVG, COUNT, MAX, MIN, SUM
|
|
Ranking
|
Full
|
DENSE_RANK, NTILE, RANK, ROW_NUMBER
|
|
Configuration
|
Partial
|
@@LOCK_TIMEOUT, @@SERVERNAME, @@SPID
|
|
Cursor
|
Full
|
@@CURSOR_ROWS, @@FETCH_STATUS, CURSOR_STATUS
|
|
Date and Time
|
Full
|
DATEADD, DATEDIFF, DATEPART, GETDATE, DAY, MONTH, YEAR
|
|
Mathematical
|
Full
|
ABS, CEILING, FLOOR, LOG, ROUND, SQUARE
|
|
Metadata
|
Partial
|
COL_LENGTH, COL_NAME, INDEX_COL, OBJECT_NAME
|
|
Security
|
Partial
|
CURRENT_USER, SESSION_USER, USER_NAME
|
|
String
|
Full
|
CHAR, LEFT, LEN, LTRIM, RIGHT, RTRIM
|
|
System
|
Partial
|
APP_NAME, CASE, CAST, CONVERT, COALESCE, @@IDENTITIY, ISDATE, ISNULL, @@ROWCOUNT
|
|
Text/Image
|
Partial
|
PATINDEX
|
|
ODBC String
|
Full
|
BIT_LENGTH, CONCAT
|
|
ODBC Numeric
|
Full
|
TRUNCATE
|
|
ODBC Date/Time
|
Full
|
CURRENT_DATE, CURRENT_TIME, DAYNAME, HOUR, MINUTE, QUARTER
|
Multiple active result sets
First introduced with ADO.NET 2.0 and SQL Server 2005, multiple active result sets (MARS)
is the ability for multiple commands to be executed against a single
connection, and to maintain multiple open recordsets. MARS can improve
application performance by not limiting applications to a single command
or result set.
What's different in SQL Azure?
It might seem
there are more differences than similarities between SQL Server 2008 and
SQL Azure, but features that are the same don't merit much discussion.
In many cases, differences between SQL Azure and SQL Server 2008 are due
to SQL Azure being a managed service, and much of the administration
has been abstracted away from us.
One of the first differences is
that we cannot choose the file placement of the database files (neither
data nor log). We have no way to manage filegroups, so those options
are also not available to us.
Another difference at the
server level is how we set collation. Collation cannot be set at the
server or database level; instead, collation can only be set at the
column or expression level. The default collation for SQL Azure is SQL_LATIN1_GENERAL_CP1_CI_AS, which is a fairly general collation for US-based applications. The following is the deciphered collation:
If a feature was deprecated in
SQL Server 2008, SQL Azure does not support that feature. One such
feature is SQL Server trace flags, which were used for debugging
performance issues. SQL Azure does not support SQL trace flags.
In a major departure from SQL Server 2008, SQL Azure does not support the Common Language Runtime (CLR).
We also can't access server configuration options, as some don't exist
and others are the responsibility of Microsoft. Additionally, SQL Azure
does not support any of the SQL Server 2008 system tables.
At the database level, SQL
Azure does not support database mirroring. There is no need for this, as
our data are replicated across multiple physical servers.
Number of databases
When we establish a SQL Azure
account, a SQL Azure instance is provisioned for us. Each SQL Azure
instance can contain up to 150 databases, including the master database.
Additional databases will require a separate SQL Azure instance.
Database objects
There is one
difference regarding tables. Database tables must have a clustered index
created before we can insert data. It is possible to create a table
without a clustered index, but no inserts can be made until such an
index is added. Global temporary tables are not supported in SQL Azure.
Service Broker, SQL Browser, and DTC
The SQL Server Service Broker
handles request queuing and asynchronous messaging in a local
installation of SQL Server. In SQL Azure, some of this functionality is
redundant with the Azure Fabric, and hence there is no Service Broker in
SQL Azure.
The SQL Browser
is also not available in SQL Azure. The only port we can access SQL
Azure through is 1433, and the SQL Browser relies on dynamic ports.
Finally, SQL Azure does not support either distributed queries or transactions, and there is no Distributed Transaction Coordinator (DTC). All transactions must be local.
T-SQL commands
SQL Azure does not support the USE
command for changing databases. If we're running a long set of commands
and need to switch databases, we can't in SQL Azure. Instead, we must
create a connection to each database, and execute the commands against
the desired connection.
Also, 4-identifier referencing (<database_name>.<schema>.<table_name>.<column>) is not supported.
The majority of the
unsupported T-SQL commands are system administration commands, which
don't apply to us. Notably, most of the DBCC commands are not supported,
nor are most of the ALTER commands
related to databases and servers. The table that follows is a partial
list of some common T-SQL commands that are unsupported; for the
complete list of unsupported commands, consult the MSDN documentation at http://msdn.microsoft.com/en-us/library/ee336253.aspx.
|
ALTER DATABASE
|
GRANT/REVOKE/DENY Server Permissions
|
|
BACKUP
|
KILL
|
|
BULK INSERT
|
OPENROWSET
|
|
CREATE/ALTER/DROP LOGIN
|
RESTORE
|
|
DBCC CHECKDB
|
SELECT INTO Clause
|
|
DBCC DBREINDEX
|
SET ANSI_NULLS
|
|
DBCC INDEXDEFRAG
|
SET ANSI PADDING_OFF
|
|
DBCC SHRINKDATABASE
|
WRITETEXT
|
System functions
A number of system
functions are also not supported by SQL Azure as they could compromise
information abstracted from us. Again, the following table is a partial
list; the complete list of unsupported system functions is in the MSDN
documentation at http://msdn.microsoft.com/en-us/library/ee336253.aspx.
|
fn_get_audit_file
|
sys.login_token
|
|
fn_get_sql
|
sys.user_token
|
|
sys.fn_validate_plan_guide
|
sys.numbered_procedure_parameters
|
Data synchronization
We do not have the option of replication or transaction log shipping in
SQL Azure, but there is a data synchronization service currently in CTP.
Utilizing the Microsoft Sync Framework, we can perform one-way or
bidirectional synchronization between a number of SQL Azure databases,
set up in a hub-and-spoke arrangement (rather than a true replication).
When we set up synchronization, we choose a hub database to be our
master database, and then pair with our member databases.
Synchronization can be the entire database, or limited to a selected
group of tables. Synchronization can be on demand or scheduled. Foreign
key constraints are not enforced in the member databases so that data
can be inserted in any order. If a
foreign key relationship is necessary for our application, the member
databases would not be suitable for using as a back-end database.
On the first
synchronization, the database schema will be created for us in the
member databases, and data will be completely synchronized. After the
initial synchronization, only modified data will be synchronized.
Unfortunately, schema changes will not be synchronized after the initial
synchronization we'll have to remove the synchronization, modify our
database, then modify the hub database, re-establish the synchronization
pairings, and start the process all over again. Member databases will
be reallocated as if we were performing an initial synchronization.
An introduction to the data sync service can be found at http://blogs.msdn.com/b/sqlazure/archive/2010/07/06/10035099.aspx.
Because this service is in CTP at the time of writing, we recommend
reviewing additional information that may have been published later for
the most up-to-date information.
