You
used both the StorageClient library and the REST API to insert new
entities into the Products table. In this section, we’ll look at how you
can both improve performance and perform transactional changes by
batching up data.
The following code
inserts multiple entities into the Products table using the
StorageClient library:
var shirtContext = new ProductContext();
for (int i = 0; i < 10; i++)
{
shirtContext.AddObject("Products",
new Product
{
PartitionKey = "Shirts",
RowKey = i.ToString(),
Name = "Shirt" + i.ToString(),
Description = "A Shirt"
});
}
shirtContext.SaveChanges();
The preceding code will create 10 new shirts and
add each new shirt to a list of objects that are to be tracked; it does
this by calling the AddObject method on the shirtContext object. Following the Unit of Work pattern,
the context object won’t send any changes to the Table service until the
SaveChanges method is called. It
will then iterate through the list of tracked objects and insert them
into the Products table.
By default, the SaveChanges
call will insert the entities into the table one by one rather than
batching the inserts into a single call. Figure 1 shows the HTTP traffic for the preceding call, captured by
using Wireshark (a packet-sniffing tool).
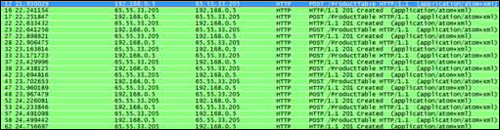
As you can see from figure 1,
to insert 10 shirts, the application must perform 10 HTTP POST requests to the Table service. This
method can cause performance problems if you’re inserting a large number
of entities and your application is outside of Windows Azure or your
web or worker role isn’t affinitized to the same data center as your
storage account.
Warning
Due to latency, inserting 10
shirts using the preceding code took 4 seconds between our local machine
and the live Table service. When running the same code as a web role in
the Windows Azure data center, it took milliseconds.
Although minimizing latency
will give large performance benefits, you can gain larger performance
improvements by batching up inserts into single calls using entity group
transactions.
Note
Due to the flexible
nature of the Windows Azure platform, you can host your storage account
and your web and worker roles in different data centers. As you can see
from the previous example, this flexibility comes at a price: latency.
For the best performance, always affinitize your web roles, worker
roles, and storage service to the same data center to minimize latency.
1. Entity group
transactions
Entity group transactions are a
type of batch insert where the whole batch is treated as a transaction,
and the whole thing either succeeds or is rolled back entirely. First,
let’s look at how batch inserts are done.
Passing SaveChangesOptions.Batch as a parameter into the SaveChanges method calls will batch up all changes into a single HTTP POST:
shirtContext.SaveChanges(SaveOptions.Batch);
Batching up the data like
this reduced our insert of 10 shirts (from the local machine to the live
service) from 4 seconds to 1 second.
The SaveOption
parameter can also be passed in with the call to the SaveChanges method to specify what happens if the inserts
aren’t entirely successful:
SaveOptions.None—
By default, when no SaveOption is passed, or when SaveOptions.None
is passed, as part of the SaveChanges
method, and a tracked entity fails to be inserted, the context object
will stop attempting to save any further entities. Any entities that
were saved successfully won’t be rolled back and will remain in the
table.
SaveOptions.ContinueOnError— If this option is passed as part of the SaveChanges call, and an entity fails to save, the context
object will continue to save all other entities.
SaveOptions.Batch— If this option is passed as part of the SaveChanges call, all entities will be processed as a
batch in the scope of a single transaction—known as an entity group
transaction. If any of the entities being inserted as part of the batch
fails to be inserted, the whole batch will be rolled back.
These are the rules for using
entity group transactions:
A
maximum of 100 operations can be performed in a single batch.
The
batch may not exceed 4 MB in size.
All
entities in the batch must have the same partition key.
You
can only perform a single operation against an entity in a batch.
In this book, we won’t
discuss the REST implementation of entity group transactions due to the
complexity of the implementation. But it’s worth noting that if you
decide to use the REST implementation, the Table service only implements
a subset of the available functionality. As of the PDC 2009 release,
the Table service only supports single changesets (a changeset being a
set of inserts, updates, or deletes) within a batch.
Entity group transactions
are executed using an isolation method known as snapshot isolation.
This is a standard method of isolation used in relational databases
such as SQL Server or Oracle; it’s also known as multiversion
concurrency control (MVCC). A snapshot of the data is taken at the
beginning of a transaction, and it’s used for the duration of the
transaction. This means that all operations within the transaction will
use the same set of isolated data that can’t be interfered with by other
concurrent processes. Because the data is isolated from all other
processes, there’s no need for locking on the table,
meaning that operations can’t be blocked by other processes. On
committing the transaction, if any modified data has been changed by
another process since the snapshot began, the whole transaction must be
rolled back and retried.
2. Retries
In order to handle the MVCC
model, your code must be able to perform retries. The ability to handle
retries is built into the StorageClient library and can be configured
using the following code:
shirtContext.RetryPolicy =
RetryPolicies.Retry(5, TimeSpan.FromSeconds(1));
The preceding retry policy will reattempt the SaveChanges operation up to five times, retrying every second.
If you don’t wish to set a retry policy, you can always set the policy
as NoRetry:
shirtContext.RetryPolicy = RetryPolicies.NoRetry;
If you need more
complicated retry polices with randomized back-off timings, or if you
wish to define your own policy, this can also be achieved by setting an
appropriate retry policy. Unfortunately, if you’re using the REST API
directly, you’ll need to roll your own retry logic.
In order to make use of the
standard retry logic, you’ll need to use the SaveChangesWithRetries
method rather than the SaveChanges method, as follows:
shirtContext.SaveChangesWithRetries();
|
Although retry policies are
vital when using entity group transactions, they can also be useful when
querying data. Your web and worker roles are based in the cloud and can
be shut down and restarted at any time by the Fabric Controller (such
as in a case of a hardware failure), so to provide a more professional
application, it may be advisable to use retry policies when querying
data.
|
So far we’ve covered the
modification of data in quite a lot of detail. But entity group
transactions can also be useful for querying data. With that in mind,
it’s worth breaking away from data updates and focusing on how to
retrieve data via the REST API.
