2. Crawler Scheduling
SharePoint's crawlers can
be scheduled to perform full and incremental crawls at different
intervals and for different periods. This is done separately for each
content source, allowing for static content to be isolated from
recurring crawls and dynamic or frequently updated content to be
constantly refreshed. The scheduling configuration is done on the Edit
Content Source page of each content source at the end of the page.
It is recommended that
SharePoint content have a relatively aggressive incremental crawl
schedule while taking into consideration actual update frequency and
possible hardware limitations. Other content sources should have their
respective usage considered before scheduling incremental crawls.
It is wise to schedule a
full crawl on a regular basis to ensure database consistency. However,
this regular schedule will depend largely on the time it takes to
perform a full crawl. Some organizations with large repositories may
choose to avoid full crawls after their initial index is populated.
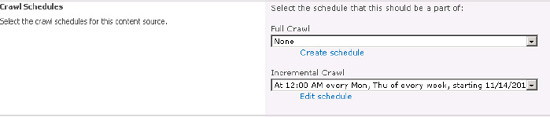
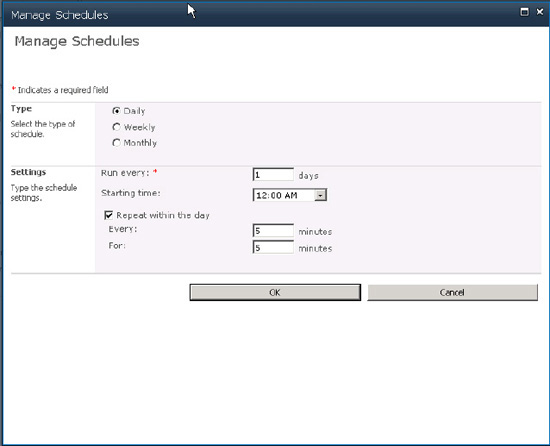
Figures 2 and 3
show the part of the Edit/Add Content Sources page where a full crawl
or incremental crawl can be scheduled and the Manage Schedules page
(accessed through the "Create schedule" and "Edit schedule" links) with
the options for scheduling those crawls.
2.1. Full vs. Incremental Crawls
SharePoint 2010 has
two types of crawl mechanisms, full and incremental. Incremental crawls
perform more efficiently and can keep the index up to date in near real
time (Figure 4).
However, at least one full crawl of a content source is always required
and there may be other occasions when a full crawl is required.
During a full crawl, the
crawler queries the content source and requests all the content for the
first time. It then saves that data in the index and crawl database with
date stamps and item IDs. Every time a full crawl is launched, this
process is begun from scratch and old data is abandoned.
A full crawl is required when
A new content source is added—any new content source requires a full crawl initially.
A new file type is added—new file types cannot be picked up on an incremental crawl.
A new managed property is mapped from a crawled property.
Managed property mappings are changed or a new crawled property is added to an existing managed property.
New crawl rules are added, changed, or removed—crawl rule modification requires a full crawl to take effect.
The index becomes corrupted or performs irregularly—this should almost never happen but should not be ruled out.
During an incremental
crawl, the crawler looks at the crawl database to determine what has
been crawled or not crawled, and then requests updated information from
the source depending on the content source type. In this way, the
crawler can collect only documents that have been added or updated since
the last crawl or remove documents from the index that have been
removed from the content source.
If a situation exists
where an incremental crawl is inappropriate or not possible, SharePoint
will start a full crawl instead. In this way, the search index will not
allow for the crawler to stop crawling on schedule and will not launch a
crawl that will corrupt the index.