1. Diagnostics in the cloud
At some point you might need to debug your code, or
you’ll want to judge how healthy your application is while it’s running
in the cloud. We don’t know about you, but the more experienced we get
with writing code, the more we know that our code is less than perfect.
We’ve drastically reduced the amount of debugging we need to do by using
test-driven development (TDD), but we still need to fire up the
debugger once in a while.
Debugging locally with the SDK
is easy, but once you move to the cloud you can’t debug at all; instead,
you need to log the behavior of the system. For logging, you can use
either the infrastructure that Azure provides, or you can use your own
logging framework. Logging, like in traditional environments, is going
to be your primary mechanism for collecting information about what’s
happening with your application.
1.1. Using Azure Diagnostics to find what’s wrong
Logs are handy. They help you
find where the problem is, and can act as the flight data recorder for
your system. They come in handy when your system has completely burned
down, fallen over, and sunk into the swamp. They also come in handy when
the worst hasn’t happened, and you just want to know a little bit more
about the behavior of the system as it’s running. You can use logs to
analyze how your system is performing, and to understand better how it’s
behaving. This information can be critical when you’re trying to
determine when to scale the system, or how to improve the efficiency of
your code.
The drawback with logging is
that hindsight is 20/20. It’s obvious, after the crash, that you
should’ve enabled logging or that you should’ve logged a particular
segment of code. As you write your application, it’s important to
consider instrumentation as an aspect of your design.
Logging is much more than
just remote debugging, 1980s-style. It’s about gathering a broad set of
data at runtime that you can use for a variety of purposes; debugging is
one of those purposes.
1.2. Challenges with troubleshooting in the cloud
When
you’re trying to diagnose a traditional on-premises system, you have
easy access to the machine and the log sources on it. You can usually
connect to the machine with a remote desktop and get your hands on it.
You can parse through log files, both those created by Windows and those
created by your application. You can monitor the health of the system
by using Performance Monitor, and tap into any source of information on
the server. During troubleshooting, it’s common to leverage several
tools on the server itself to slice and dice the mountain of data to
figure out what’s gone wrong.
You simply can’t do this in the
cloud. You can’t log in to the server directly, and you have no way of
running remote analysis tools. But the bigger challenge in the cloud is
the dynamic nature of your infrastructure. On-premises, you have access
to a static pool of servers. You know which server was doing what at all
times. In the cloud, you don’t have this ability. Workloads can be
moved around; servers can be created and destroyed at will. And you
aren’t trying to diagnose the application on one server, but across a
multitude of servers, collating and connecting information from all the
different sources. The number of servers used in cloud applications can
swamp most diagnostic analysis tools. The shear amount of data available
can cause bottlenecks in your system.
For example, a typical web
user, as they browse your website and decide to check out, can be
bounced from instance to instance because of the load balancer. How do
you truly find out the load on your system or the cause for the slow
response while they were checking out of your site? You need access to
all the data that’s available on terrestrial servers and you need the
data collated for you.
You also need close control over the diagnostic data producers. You need an easy way to dial the level of information from debug to critical.
While you’re testing your systems, you need all the data, and you need
to know that the additional load it places on the system is acceptable.
During production, you want to know only about the most critical issues,
and you want to minimize the impact of these issues on system
performance.
For all these reasons, the
Windows Azure Diagnostics platform sits on top of what is already
available in Windows. The diagnostics team at Microsoft has extended and
plugged in to the existing platform, making it easy for you to learn,
and easy to find the information you need.
2. Diagnostics in the cloud is just like normal (almost)
With the challenges of
diagnostics at cloud-scale, it’s amazing that the solution is so simple
and elegant. Microsoft chose to keep everything that you’re used to in
its place. Every API, tool, log, and data source is the same way it was,
which keeps the data sources known and well documented. The diagnostics
team provides a small process called MonAgentHost.exe that’s started on
your instances.
The MonAgentHost
process is started automatically, and it acts as your agent on the box.
It knows how to tap into all the sources, and it knows how to merge the
data and move it to the correct locations so you can analyze it. You can
configure the process on the fly without having to restart the host
it’s running on. This is critical. You don’t want
to have to take down a web role instance just to dial up the amount of
diagnostic information you’re collecting. You can control data
collection across all your instances with a simple API. All the moving
parts of the process are shown in figure 1.
Your role instance must be running in full-trust mode to be able to run
the diagnostic agent. If your role instance is running in partial
trust, it won’t be able to start.
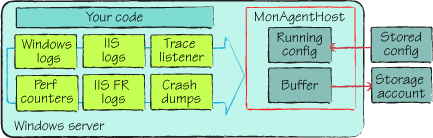
As the developer, you’re always in control of what’s being collected and when it’s collected. You can communicate with MonAgentHost
by submitting a configuration change to the process. When you submit
the change, the process reloads and starts executing your new commands.
2.1. Managing event sources
The local diagnostic agent
can find and access any of the normal Windows diagnostic sources; then
it moves and collates the data into Windows Azure storage. The agent can
even handle full memory dumps in the case of an unhandled exception in
one of your processes.
You must configure the agent
to have access to a cloud storage account. The agent will place all your
data in this account. Depending on the source of the data, it’ll either
place the information in BLOB storage (if the source is a traditional
log file), or it’ll put the information in a table.
Some information is stored
in a table because of the nature of the data collection activity.
Consider when you’re collecting data from Performance Monitor. This data
is usually stored in a special file with the extension .blg.
Although this file could be created and stored in BLOB storage, you
would have the hurdle of merging several of these files to make any
sense of the data (and the information isn’t easily viewed in Notepad).
You generally want to query that data. For example, you might want to
find out what the CPU and memory pressure on the server were for a given
time, when a particular request failed to process.
Table 1
shows what the most common sources of diagnostic information are, and
where the agent stores the data after it’s collected. We’ll discuss how
to configure the sources, logs, and the (tantalizingly named) arbitrary
files in later sections.
Table 1. Diagnostic data sources
| Data source | Default | Destination | Configuration |
|---|
| Arbitrary files | Disabled | BLOB | DirectoryConfiguration class |
| Crash dumps | Disabled | BLOB | CrashDumps class |
| Trace logs | Enabled | Azure table | web.config trace listener |
| Diagnostic infrastructure logs | Enabled | Azure table | web.config trace listener |
| IIS failed request logs | Disabled | BLOB | web.config traceFailedRequests |
| IIS logs | Enabled | BLOB | web.config trace listener |
| Performance counters | Disabled | Azure table | PerformanceCounterConfiguration class |
| Windows event logs | Disabled | Azure table | WindowsEventLogsBufferConfiguration class |
The
agent doesn’t just take the files and upload them to storage. The agent
can also configure the underlying sources to meet your needs. You can
use the agent to start collecting performance data, and then turn the
source off when you don’t need it anymore. You do all this through
configuration.
2.2. It’s not just for diagnostics
We’ve been focusing pretty
heavily on the debugging or diagnostic nature of the Windows Azure
Diagnostics platform. Diagnostics is the primary goal of the platform,
but you should think of it as a pump of information about what your
application is doing. Now that you no longer have to manage
infrastructure, you can focus your attention on managing the application
much more than you have in the past.
Consider some of
the business possibilities you might need to provide for, think about how the diagnostic tools can
make some of these scenarios possible.
There are the obvious
scenarios of troubleshooting performance and finding out how to tune the
system. The common process is that you drive a load on the system and
monitor all the characteristics of the system to find out how it
responds. This is a good way to find the limits of your code, and to
perform A/B tests on your changes. During an A/B test, you test two
possible options to see which leads to the better outcome.
Other scenarios aren’t
technical in nature at all. Perhaps your system is a multitenant system
and you need to find out how much work each customer does. In a medical
imaging system, you’d want to know how many images are being analyzed
and charge a flat fee per image. You could use the diagnostic system to
safely log a new image event, and then once a day move that to Azure storage to feed into your billing system.
Maybe in this same
scenario you need a rock-solid audit that tells you exactly who’s
accessed each medical record so you can comply with industry and
government regulations. The diagnostic system provides a clean way to
handle these scenarios.
An even more common scenario
might be that you want an analysis of the visitors to your application
and their behaviors while they’re using your site. Some advanced e-commerce
platforms know how their customers shop. With the mountains of data
collected over the years, they can predict that 80 percent of customers
in a certain scenario will complete the purchase. Armed with this data,
they can respond to a user’s behavior and provide a way to increase the
likelihood that they’ll make a purchase. Perhaps this is a timely
invitation to a one-on-one chat with a trained customer service person
to help them through the process. The diagnostics engine can help your
application monitor the key aspects of the user and the checkout
process, providing feedback to the e-commerce system to improve
business. This is the twenty-first-century version of a salesperson in a
store asking if they can help you find anything.
To achieve all of these feats of science with the diagnostic agent, you need to learn how to configure and use it properly.
