People are using SQL Azure in their applications in two general scenarios: near data and far data.
These terms refer to how far away the code that’s calling into SQL
Server is from the data. If it’s creating the connection over what might
be a local network (or even closer with named pipes or shared memory),
that’s a near-data scenario. If the code opening the connection is
anywhere else, that’s a far-data scenario.
1. Far-data scenarios
The most common far-data
scenario is when you’re running your application, perhaps a web
application, in an on-premises data center, but you’re hosting the data
in SQL Azure. You can see this relationship in figure 1.
This is a good choice if you’re slowly migrating to the cloud, or if
you want to leverage the amazing high availability and scale SQL Azure
has to offer without spending $250,000 yourself.
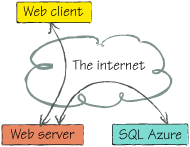
In
a far-data scenario, the client doesn’t have to be a web browser over
the internet. It might be a desktop WPF application in the same building
as the web server, or any other number of scenarios. The one real
drawback to far data is the processing time and latency of not being
right next to the data. In data-intensive applications this would be a
critical flaw, whereas in other contexts it’s no big deal.
Far data works well when the
data in the far server doesn’t need to be accessed in real time. Perhaps
you’re offloading your data to the cloud as long-term storage, and the
real processing happens onsite. Or perhaps you’re trying to place the
data where it can easily be accessed by many different types of clients,
including mobile public devices, web clients, desktop clients, and the
like.
2. Near-data scenarios
A near-data scenario would be
doing calculations on the SQL Server directly, or executing a report on
the server directly. The code using the data runs close to the data.
This is why the SQL team added the ability to run managed code (with CLR
support) into the on-premises version of SQL Server. This feature isn’t
yet available in SQL Azure. Figure 2 shows what a near-data scenario looks like.
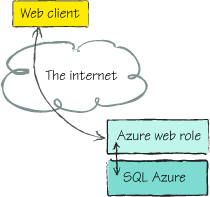
One way to convert a far-data
application to a near-data one is to move the part of the application
accessing the code as close to the data server as possible. With SQL
Azure, this means creating a services tier and running that in a role in
Azure. Your clients can still be web browsers, mobile devices, and PCs,
but they will call into this data service to get the data. This data
service will then call into SQL Server. This encapsulates the use of SQL
Azure, and helps you provide an extra layer of logic and security in
the mix.
3. SQL Azure versus Azure Tables
SQL Azure and the Azure Table service have some significant differences .
These differences help make it a little easier to pick between SQL
Azure and Azure Tables, and the deciding factor usually comes down to
whether you already have a database to migrate or not.
If you do have a local
database, and you want to keep using it, use SQL Azure. If moving it to
the cloud would require you to refactor some of the schema to support
partitioning or sharding, you might want to consider some options.
If size is the issue, that
would be the first sign that you might want to consider Azure Tables.
Just make sure the support Tables has for transactions and queries meets
your needs. The size limit surely will be sufficient, at 100 TB.
If you’re staying with SQL
(versus migrating to Azure Tables) and are going to upgrade your
database schema to be able to shard or partition, take a moment to think
about also upgrading it to support multitenant scenarios. If you have
several copies of your database, one for each customer that uses the
system, now would be a good time to add the support needed to run those
different customers on one database, but still in an isolated manner.
If you’re building a new
system that doesn’t need sophisticated transactions, or a complex
authorization model, then using Azure Tables is probably best. People
tend to fall into two groups when they think of Tables. They’re either
from “ye olde country” and think of Tables as a simple data-storage
facility that’ll only be used for large lookup tables and flat data, or
they’re able to see the amazing power that a flexible schema model and
distributed scale can give them. Looking at Tables without the old
blinders on is challenging. We’ve been beaten over the head with
relational databases for decades, and it’s hard to consider something
that deviates from that expected model. The Windows Azure platform does a
good job of providing a platform that we’re familiar and comfortable
with, while at the same time giving us access to the new paradigms that
make the cloud so compelling and powerful.
The final consideration is
cost. You can store a lot of data in Azure Tables for a lot less money
than you can in SQL Azure. SQL Azure gives you a lot more features to
use (joins, relationships, and so on), but it does cost more.
