A single SharePoint 2010 farm can provide multiple
instances of search service applications. Each service instance can
support multiple component instances in a topology that can be designed
for performance, for resiliency, or to isolate information.
The default topology of a new
search service application will have a single instance of each
component, all components on one application server, and all databases
on one database server. The four components are as follows.
Administration interface
Crawl component (the crawler)
Database set, broken into three databases: administration, crawl, and property
Index partition
This topology can be
changed using the Modify Topology link located on the Farm-Wide Search
Administration page or from the Search Service Administration page. The
SharePoint Search topology cannot be changed in stand-alone
installations.
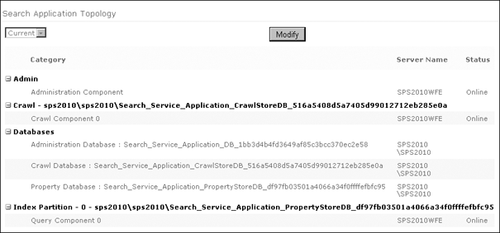
The Search Application
Topology Web Part presents the initial topology in the lower portion of
the Search Administration page, shown in Figure 1.
1. Scaling Considerations
The reason that the
SharePoint 2010 product team broke out the search components was to
provide robust scaling for the different aspects of the crawl and
indexing process. Different implementations will find bottlenecks being
created at different points in the overall indexing process, so by
enabling the scaling of the different components, you can create a
topology that fits your needs.
For example, if you need to reduce crawl times and increase index freshness, then consider performing the following actions.
If the crawl component is overwhelmed, add more crawl component servers.
If the crawl database is I/O bound on the SQL server, add crawl databases on same SQL server.
If the SQL server bottleneck is memory or CPU, add SQL servers with additional crawl databases.
To reduce query latency, consider the following remedies.
If full-text
query latency is high, partition the index into smaller partitions. Each
partition can contain ~10M items. You will generally need enough memory
to fit 33 percent of the index in RAM to meet sub-second latency
responses.
If query latency is high because of the number of queries, add query components to mirror index partitions.
If property query latency is high because the property database is I/O bound, add property databases to the same SQL server.
If
property query latency is high because of a memory or CPU bottleneck on
SQL server, add property databases to additional SQL servers.
Note:
You can use the
SharePoint Backend Query Latency report provided by SharePoint 2010 to
help determine where scaling out is needed to improve query latency.
To increase availability for query process, consider these suggestions.
Deploy multiple query components with multiple index partitions.
Deploy multiple mirrored query components and property store databases.
Use clustered or mirrored database servers to host search databases.
To increase availability
for crawling process, add crawl databases supported by multiple crawl
components with redundant crawl servers. Normally, two crawl components
can support a crawl database.
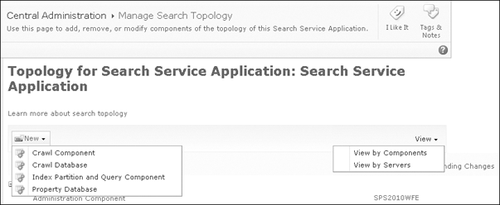
2. Modifying the Topology
To make any change to the
topology, click the Modify button at the top of the page to open the
topology management page partially shown in Figure 2.
The view of components on this page can be organized by components or
by server hosting the components. From the New menu, select the
component that you want to create and add to the search application.
Changes to the
topology are defined in the appropriate dialog boxes: New, Properties,
or Delete. However, changes are not implemented until the Apply Topology
Changes button is clicked. Clicking this button starts the SharePoint
timer job, which accomplishes the actions required. You can make
multiple changes to the search topology and then apply them all at once
by clicking the Apply Topology Changes button. Because many changes can
impact performance during their application, you might want to choose to
define the changes in the management pages but use Windows PowerShell
scripts to schedule their implementation.
To create a new component,
click the New link in the upper-left corner of the page and select the
appropriate component from the drop-down list. To edit the properties or
delete a component, use the context menu of the component. There must
be at least one instance of each component, so the Delete command will
not be available in some instances. Also, for the query component, there
is an extra menu item, Add Mirror, as shown in Figure 3.

3. Crawl Databases
Crawl databases
contain configurations and instructions required by the crawl component,
tables used during crawls to queue items to be crawled, and log
information used in crawl logs. Since a new crawl component must be
associated with an existing or pending database, you should create the
new database first.
The database can be hosted
on a SQL server other than the default server. See the scaling
considerations above to determine placement of the databases. Microsoft
strongly recommends Windows authentication over the SQL authentication
option. If you have mirrored SQL servers, you can associate the database
with a failover database server. As discussed earlier, if you select
the Dedicate This Crawl Store To Hosts As Specified In Host Distribution
Rules option, the database will not participate in the automatic host
distribution process. As long as there is more than one crawl database,
any crawl database can be specified in a Host Distribution Rule.
Note:
Crawl databases that have had crawl components associated with them cannot be deleted until the crawl components have been associated with another database.
4. Crawl Components
Use the New menu to create a
new crawl component. The configuration is very simple. Crawl component
names are zero-based and generated as they are built, not while they are
pending. Select a member of the farm as the server to host this crawl
component. Only servers with a complete installation will be listed.
Select the Associated Crawl Database. If this database already has a
crawl component associated with it, then you are adding a crawl
component for resiliency. Since all of the crawl instructions including
state are stored in a SQL database, one crawl component can easily pick
up where another left off. If you are adding one or more crawl
components to a new database, then you are spreading the crawl workload
for performance.
Finally, you must specify
the location on the server file system where the index files will be
created and stored before they are propagated to the query servers.
Unlike previous versions, the space requirements for this location are
relatively small and constant, because the entire index is not stored on
the crawl component server.
Note:
You should exclude all index locations from antivirus scans.
To redistribute existing
content to the new database, you must use the Auto Host Distribution
tool, which is available by clicking the If You Would Like The System To
Analyze Your Current Distribution And Make Recommendations For
Redistribution, Click Here link on the Host Name view of the crawl logs.
The tool will give an estimate of the time required to redistribute the
content. Crawls will be paused during this activity, and the
redistribution status will be displayed on the Host Distribution Rules
page. On the Search Administration dashboard, you will see that the
crawl status is Paused For: Refactoring. Crawl activity will resume
automatically after the content is redistributed.
If you remove the crawl
components from a database and delete the database, the content will
automatically be redistributed to other existing databases. Crawls will
be paused during this activity as well.
5. Property Databases
New property databases are created to improve query performance. They can also be mirrored on SQL servers for resiliency. When creating
a new property database, you not only get to select the SQL server
instance, but you also can use your own naming convention or accept the
recommended name. Again, either Windows or SQL authentication will work;
Windows authentication is recommended. If you have SQL mirroring
established, you may enter the name of the failover database server.
The name generated for the original property database for our demo farm was the name of the search
service application appended with “PropertyStoreDB Appended With The
Database GUID:
Search_Service_Application_PropertyStoreDB_df97fb03501a4066a34f0ffffefbfc95.”
The generated name of the second database was SearchPropertyDB1. The
naming convention for the Crawl Database followed a similar convention.
11.7.6. Index Partitions and Query Components
You can split the index into
smaller partitions to speed up full-text queries. Each partition can
contain approximately 10 million items, but you should plan on having
enough memory to fit 33 percent of the index in RAM to meet sub-second
latency responses. The index size and full-text queries must be
monitored so that the topology design is kept current with the growth of
search activities and performance standards.
To split the index, select
Index Partition And Query Component from the New menu (though note that
the dialog box that opens is titled Add Query Component). Select the
farm member to host the index partition and query component and then
select the existing property database with which this index will be
associated. Then specify the location for the index file. Unlike the
crawl component, the index component will store a complete copy of this
partition of the index, so sufficient space must be reserved to handle
the current partition and estimated growth.
Finally, there is a Set This
Query Component As Failover Only option that is available even for the
first query server associated with this index.
The command to add mirrors is tucked away in the context menu for the query component, as you saw in Figure 11-23.
The property box for the new query component is the same as before,
except the Associated Property Database is preconfigured and inactive.
The failover option is still available. You would add mirrors for the
index partitions to reduce query latency due to the number of queries.
Note that the term “mirror” is used even though these are index files,
not SQL databases.
