1. Problem
You need to implement a map
that handles certain records within a repeating series in an intelligent
fashion. The map must be able to determine the sequential order, or
index, of each repeating record, and perform customized logic based on
that index.
2. Solution
Develop a BizTalk Server map, and leverage the Iteration functoid by taking the following steps.
Click
the Toolbox, and click the Advanced Functoids tab. On the map surface,
between the source and destination schemas, drag and drop an Iteration
functoid. This functoid accepts a repeating source record (or data
element) as its one input parameter. The return value is the currently
processed index of a specific instance document (for a source record
which repeated five times, it would return 1, 2, 3, 4, and 5 in
succession as it looped through the repeating records).
Connect
the left side of the Iteration functoid to the repeating source record
(or data element) whose index is the key input for the required decision
logic.
Connect the right side of the Iteration functoid to the additional functoids used to implement the required business logic.
3. How It Works
An example of a map that uses the Iteration functoid is shown in Figure 1.
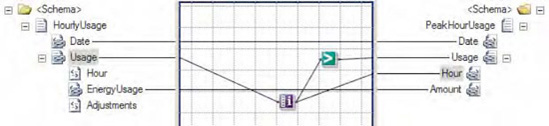
In this example, all the
peak hourly energy values from the source XML are mapped over to the
destination XML. The Iteration functoid is used to determine the index
of each HourlyUsage record, with those
having an index value of 3 or higher being flagged as peak hours.
Additionally, the output from the Iteration functoid is also used to
create the Hour element in the destination XML, defining to which hour the energy reading pertains. The XML snippet in Listing 1 represents one possible document instance of the source schema.
Example 1. Sample Source Instance for the Iteration Functoid Example
<ns0:HourlyUsage xmlns:ns0="http://IterationFunctoid.HourlyUsage"> <Date>09/06/2010</Date>
<Usage>
<Hour>01</Hour>
<EnergyUsage>2.4</EnergyUsage>
<Adjustments>0</Adjustments>
</Usage>
<Usage>
<Hour>02</Hour>
<EnergyUsage>1.7</EnergyUsage>
<Adjustments>1</Adjustments>
</Usage>
<Usage>
<Hour>03</Hour>
<EnergyUsage>3.9</EnergyUsage>
<Adjustments>0</Adjustments>
</Usage>
<Usage>
<Hour>04</Hour>
<EnergyUsage>12.4</EnergyUsage>
<Adjustments>3</Adjustments>
</Usage>
<Usage>
<Hour>05</Hour>
<EnergyUsage>15</EnergyUsage>
<Adjustments>0</Adjustments>
</Usage>
<Usage>
<Hour>06</Hour>
<EnergyUsage>3.2</EnergyUsage>
<Adjustments>1</Adjustments>
</Usage>
</ns0:HourlyUsage>
|
When passed through the map displayed in Figure 1, this XML will produce the XML document shown in Listing 2, containing all the peak hourly energy usage values with their associated Hour value.
Example 2. Sample Destination Instance for the Iteration Functoid Example
<ns0:PeakHourUsage xmlns:ns0="http://IterationFunctoid.PeakHourUsage">
<Date>09/06/2010</Date>
<Usage>
<Hour>4</Hour>
<Amount>12.4</Amount>
</Usage>
<Usage>
<Hour>5</Hour>
<Amount>15</Amount>
</Usage>
<Usage>
<Hour>6</Hour>
<Amount>3.2</Amount>
</Usage>
</ns0:PeakHourUsage>
|
The Iteration functoid can be a
crucial tool for those business scenarios that require the current index
number of a looping structure within a map to be known. In the energy
usage example, it allows a generic list of chronological usage values to
be mapped to a document containing only those values that occur in the
afternoon, along with adding an element describing to which hour that
usage pertains. As the map processes the repeating HourlyUsage
records in the source XML in a sequential fashion, the index from the
Iteration functoid is passed to the logical Greater Than functoid, which
compares the index with a hard-coded value of 3. If the index value is 4
or greater, the element is created in the destination XML, and its hour
ending value is set.
This example works well for
the purposes of our simple scenario, but those who have dealt with
hourly values of any kind know that days on which daylight saving time
(DST) falls need to be handled carefully. Since the time change
associated with DST actually occurs early in the morning, there are 13
morning (before afternoon) hourly values in the fall occurrence of DST,
and 11 morning hourly values in the spring occurrence.
The map in Figure 1
can easily be enhanced to account for this by adding logic based on the
record count of hourly values in the source XML document. You can
accomplish this via the following steps:
Click
the Toolbox, and click the Advanced Functoids tab. On the map surface,
between the source and destination schemas, drag and drop a Record Count
functoid. This functoid accepts a repeating source record (or data
element) as its one input parameter. The return value is the count of
repeating source records contained in a specific instance document.
Connect
the left side of the Record Count functoid to the repeating source
record (or data element) whose index is the key input for the required
decision logic.
Drag
and drop a Subtraction functoid from the Mathematical Functoids tab
onto the map surface, positioning it to the right of the Record Count
functoid. This functoid accepts a minimum of 2 and a maximum of 99 input
parameters. The first is a numeric value, from which all other numeric
input values (the second input parameter to the last) are subtracted.
The return value is a numeric value equaling the first input having all
other inputs subtracted from it.
Connect the right side of the Record Count functoid to the left side of the Subtraction functoid.
Specify the second input parameter for the Subtraction functoid as a constant, with a value of 12.
Connect
the right side of the Subtraction functoid to the left side of the
Greater Than functoid. Ensure that this input to the Greater Than
functoid is the second input parameter.
In this modified
example, the repeating source record's count has 12 subtracted from it
to adjust for the two DST days of the year (this works since we are
interested in only the afternoon energy usage values, which are always
the final 12 readings for a day). This adjusted value is then passed
through the same logical Greater Than functoid as in the previous
example, and the DST issue is effectively handled.
The use of the Iteration functoid
is common in a number of other scenarios. One such scenario is when
dealing with a document formatted with comma-separated values (CSV).
Often, the first row in a CSV document contains column header
information, as opposed to actual record values. The following flat file
snippet shows one possible representation of energy usage values in CSV
format:
EnergyUsage,Adjustments
2.4,0
2.5,0
2.8,0
In cases like these, it is
likely that you do not want to map the column headers to the destination
XML document. You can use an Iteration functoid to skip the first
record of a CSV document. The index from the Iteration functoid is
passed to a logical Not Equal functoid, which compares the index with a
hard-coded value of 1. If the index is anything other than 1 (the record
at index 1 contains the column header information), the values are
mapped to the destination XML.
NOTE
You can also strip out column headers by using envelope schemas.
Another common use of the
Iteration functoid is to allow the interrogation of records preceding
or following the currently processed record. This can be helpful when
mapping elements in a repeating record in the source schema that require
knowledge of the next or previous record.
