Designing a Clustering Solution
The first thing to
decide when you are considering a clustering solution for your network
is just what you expect to realize from the cluster—in other words, just
how much availability, reliability, or scalability you need. For some
organizations, high availability means that any downtime at all is
unacceptable, and clustering can provide a solution that protects
against three different types of failures:
Software failures
Many types of software failure can prevent a critical application from
running properly. The application itself could malfunction, another
piece of software on the computer could interfere with the application,
or the operating system could have problems, causing all the running
applications to falter. Software failures can result from applying
upgrades, from conflicts with newly installed programs, or from the
introduction of viruses or other types of malicious code. As long as
system administrators observe basic precautions (such as not installing
software updates on all the servers in a cluster simultaneously), a
cluster can keep an application available to users despite software
failures.
Hardware failures Hard
drives, cooling fans, power supplies, and other hardware components all
have limited life spans, and a cluster enables critical applications to
continue running despite the occurrence of a hardware failure in one of
the servers. Clustering also makes it possible for administrators to
perform hardware maintenance tasks on a server without having to bring
down a vital application.
Site failures
In a geographically dispersed cluster, the servers are in different
buildings or different cities. Apart from making vital applications
locally available to users at various locations, a multisite cluster
enables the applications to continue running even if a fire or natural
disaster shuts down an entire site.
Estimating Availability Requirements
The degree of
availability you require depends on a variety of factors, including the
nature of the applications you are running, the size, location, and
distribution of your user base, and the role of the applications in your
organization. In some cases, having applications available at all times
is a convenience; in others, it is a necessity. The amount of
availability an organization requires for its applications can affect
its clustering configuration in several ways, including the type of
clustering you use, the number of servers in the cluster, the
distribution of applications across the servers in the cluster, and the
locations of the servers.
The
technical support department of a software company might need the
company’s customer database available to be fully productive, but can
conceivably function without it for a time. For a company that sells its
products exclusively through an e-commerce Web site, however, Web
server downtime means no incoming orders, and therefore no income. For a
hospital or police department, non-functioning servers can literally be
a matter of life and death. Each of these organizations might be
running similar applications and servicing a similar number of clients,
but their availability requirements are quite different, and so should
their clustering solutions be. |
|
Availability is sometimes
quantified in the form of a percentage reflecting the amount of time
that an application is up and running. For example, 99% availability
means that an application can be unavailable for up to 87.6 hours during
a year. An application that is 99.9% available can be down for no more
than 8.76 hours a year.
Achieving
a specific level of availability often involves more than just
implementing a clustering solution. You might also have to install fault
tolerant hardware, create an extensive hardware and software evaluation
and testing plan, and establish operational policies for the entire IT
department. As availability requirements get higher, the amount of time,
money, and effort needed to achieve them grows exponentially. You might
find that achieving 95% to 99% reliability is relatively easy, but
pushing reliability to 99.9% becomes very expensive indeed.
Scaling Clusters
Both server clusters
and Network Load Balancing are scalable clustering solutions, meaning
that you can improve the performance of the cluster as the needs of your
organization grow. There are two basic methods of increasing cluster
performance, which are as follows:
Scaling up
Improving individual server performance by modifying the computer’s
hardware configuration. Adding random access memory (RAM) or level 2
(L2) cache memory, upgrading to faster processors, and installing
additional processors are all ways to scale up a computer. Improving
server performance in this way is independent of the clustering solution
you use. However, you do have to consider the individual performance
capabilities of each server in the cluster. For example, scaling up only
the active nodes in a server cluster might establish a level of
performance that the passive nodes cannot meet when they are called on
to replace the active nodes. It might be necessary to scale up all the
servers in the cluster to the same degree, to provide optimum
performance levels under all circumstances.
Scaling out
Adding servers to an existing cluster. When you distribute the
processing load for an application among multiple servers, adding more
servers reduces the burden on each individual computer. Both server
clusters and NLB clusters can be scaled out, but it is easier to add
servers to an NLB cluster.
In
Network Load Balancing, each server has its own independent data store
containing the applications and the data they supply to clients. Scaling
out the cluster is simply a matter of connecting a new server to the
network and cloning the applications and data. Once you have added the
new server to the cluster, NLB assigns it an equal share of the
processing load.
Scaling
out a server cluster is more complicated because the servers in the
cluster must all have access to a common data store. Depending on the
hardware configuration you use, scaling out might be extremely expensive
or even impossible. If you anticipate the need for scaling out your
server cluster sometime in the future, be sure to consider this when
designing its hardware configuration.
Be
sure to remember that the scalability of your cluster is also limited
by the capabilities of the operating system you are using. When scaling
out a cluster, the maximum numbers of nodes supported by the Windows
operating systems are as follows: | Operating System | Network Load Balancing | Server Clusters |
|---|
| Windows Server 2003, Standard Edition | 32 | Not Supported | | Windows Server 2003, Enterprise Edition | 32 | 8 | | Windows Server 2003, Datacenter Edition | 32 | 8 | | Windows 2000 Advanced Server | 32 | 2 | | Windows 2000 Datacenter Server | 32 | 4 |
When scaling up a cluster, the operating system limitations are as follows: | Operating System | Maximum Number of Processors | Maximum RAM |
|---|
| Windows Server 2003, Standard Edition | 2 | 4 GB | | Windows Server 2003, Enterprise Edition | 8 | 32 GB | | Windows Server 2003, Datacenter Edition | 32 | 64 GB | | Windows 2000 Advanced Server | 8 | 8 GB | | Windows 2000 Datacenter Server | 32 | 64 GB |
|
|
How Many Clusters?
If you want to deploy
more than one application with high availability, you must decide how
many clusters you want to use. The servers in a cluster can run multiple
applications, of course, so you can combine multiple applications in a
single cluster deployment, or you can create a separate cluster for each
application. In some cases, you can even combine the two approaches.
For example, if you
have two stateful applications that you want to deploy using server
clusters, the simplest method would be to create a single cluster and
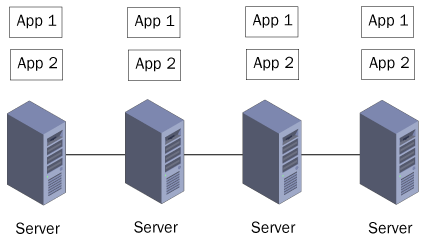
install both applications on every computer in the cluster, as shown in Figure 3.
In this arrangement, a single server failure affects both applications,
and the remaining servers must be capable of providing adequate
performance for both applications by themselves.
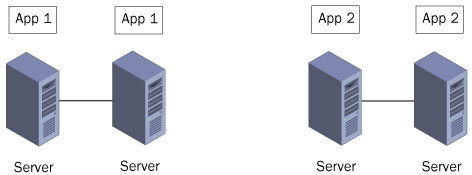
Another method is to create a separate cluster for each application, as shown in Figure 4.
In this model, each cluster operates independently, and a failure of
one server only affects one of the applications. In addition, the
remaining servers in the affected cluster only have to take on the
burden of one application. Creating separate clusters provides higher
availability for the applications, but it can also be an expensive
solution, because it requires more servers than the first method.
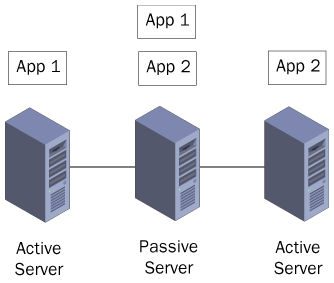
It is also possible
to compromise between these two approaches by creating a single
cluster, installing each of the applications on a separate active node,
and using one passive node as the backup for both applications, as shown
in Figure 5.
In this arrangement, a single server failure causes the passive node to
take on the burden of running only one of the applications. Only if
both active nodes fail would the passive node have to take on the full
responsibility of running both applications. It is up to you to evaluate
the odds of such an occurrence and to decide whether your
organization’s availability requirements call for a passive node server
with the capability of running both applications at full performance
levels, or whether a passive node scaled to run only one of the
applications is sufficient.

Combining Clustering Technologies
The
decision to use server clustering or Network Load Balancing on your
clusters is usually determined by the applications you intend to run.
However, in some cases it might be best to deploy clusters of different
types together to create a comprehensive high availability solution.
The most common example
of this approach is an e-commerce Web site that enables Internet users
to place orders for products. This type of site requires Web servers
(which are stateless applications) to run the actual site, and
(stateful) database servers to store customer, product, and order entry
information. In this case, you can build an NLB cluster to host the Web
servers and a server cluster for the database servers, as shown in Figure 6. The two clusters interface just as though the applications were running on individual servers.
Dispersing Clusters
Deploying
geographically dispersed clusters enables applications to remain
available in the event of a catastrophe that destroys a building or even
a city. Having cluster servers at different sites can also enable users
to access applications locally, rather than having to communicate with a
distant server over a relatively slow wide area network (WAN)
connection.
Geographically
dispersed server clusters can be extremely complex affairs: in addition
to the regular network, you have to construct a long-distance storage
area network (SAN) that gives the cluster servers access to the shared
application data. This usually means that you have to combine privately
owned hardware and software products with WAN links for the SAN supplied
by a third-party service provider.
Geographically
dispersing Network Load Balancing clusters is much easier, because
there is no shared data store. However, in most cases, an NLB cluster
that is dispersed among multiple sites is not actually a single cluster
at all. Instead of installing multiple servers at various locations and
connecting them all into a single cluster, you can create a separate
cluster at each location and use another technique to distribute the
application load among the clusters. This is possible with stateless
applications. In the case of a geographically dispersed cluster of Web
or other Internet servers, the most common solution is to create a
separate NLB cluster at each site, and then use the DNS round robin
technique to distribute client requests evenly among the clusters.
Normally, DNS
servers contain resource records that associate a single host name with a
single IP address. For example, when clients try to connect to an
Internet Web server called www.contoso.com, the clients’ DNS servers
always supply the same IP address for that name. When the
www.contoso.com Web site is actually a Network Load Balancing cluster,
there is still only one name and one IP address, and it is up to the
clustering software to distribute the incoming requests among the
servers in the cluster. In a typical geographically dispersed NLB
cluster, each site has an independent cluster with its own separate IP
address. The DNS server for the contoso.com domain associates all the
cluster addresses with the single www.contoso.com host name and supplies
the addresses to incoming client requests in a round robin fashion. The
DNS server thus distributes the requests among the clusters, and the
clustering software distributes the requests for the cluster among the
servers in that cluster.
