A cluster is a group of two or more servers dedicated
to running a specific application (or applications) and connected to
provide fault tolerance and load balancing. Clustering is intended for
organizations running applications that must be available, making any
server downtime unacceptable. In a server cluster, each computer is
running the same critical applications, so that if one server fails, the
others detect the failure and take over at a moment’s notice. This is
called failover.
When the failed node returns to service, the other nodes take notice
and the cluster begins to use the recovered node again. This is called failback.
Clustering capabilities are installed automatically in the Windows
Server 2003 operating system. In Microsoft Windows 2000 Server, you had
to install Microsoft Clustering Service as a separate module.
Clustering Types
Windows Server 2003 supports two different types of clustering: server clusters and Network Load Balancing (NLB).
The difference between the two types of clustering is based on the
types of applications the servers must run and the nature of the data
they use.
Important
Server
clustering is intended to provide high availability for applications,
not data. Do not mistake server clustering for an alternative to data
availability technologies, such as RAID (redundant array of independent
disks) and regular system backups. |
Server Clusters
Server
clusters are designed for applications that have long-running in-memory
states or large, frequently changing data sets. These are called stateful applications,
and include database servers such as Microsoft SQL Server, e-mail and
messaging servers such as Microsoft Exchange, and file and print
services. In a server cluster, all the computers (called nodes)
are connected to a common data set, such as a shared SCSI bus or a
storage area network. Because all the nodes have access to the same
application data, any one of them can process a request from a client at
any time. You configure each node in a server cluster to be either
active or passive. An active node receives and processes requests from
clients, while a passive node remains idle and functions as a fallback,
should an active node fail.
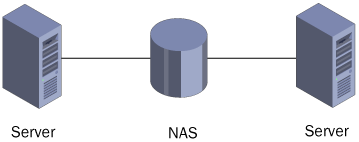
For example, a
simple server cluster might consist of two computers running both
Windows Server 2003 and Microsoft SQL Server, connected to the same
Network-Attached Storage (NAS) device, which contains the database files
(see Figure 1).
One of the computers is an active node and one is a passive node. Most
of the time, the active node is functioning normally, running the
database server application, receiving requests from database clients,
and accessing the database files on the NAS device. However, if the
active node should suddenly fail, for whatever reason, the passive node
detects the failure, immediately goes active, and begins processing the
client requests, using the same database files on the NAS device.
See Also
The
obvious disadvantage of this two-node, active/passive design is that
one of the servers is being wasted most of the time, doing nothing but
functioning as a passive standby. Depending on the capabilities of the
application, you can also design a server cluster with multiple active
nodes that share the processing tasks among themselves. You learn more
about designing a server cluster later in this lesson. |
A server cluster has its
own name and Internet Protocol (IP) address, separate from those of the
individual computers in the cluster. Therefore, when a server failure
occurs, there is no apparent change in functionality to the clients,
which continue to send their requests to the same destination. The
passive node takes over the active role almost instantaneously, so there
is no appreciable delay in performance. The server cluster ensures that
the application is both highly available and highly reliable, because,
despite a failure of one of the servers in the cluster, clients
experience few, if any, unscheduled application outages.
Windows Server 2003,
Enterprise Edition, and Windows Server 2003, Datacenter Edition, both
support server clusters consisting of up to eight nodes. This is an
increase over the Microsoft Windows 2000 operating system, which
supports only two nodes in the Advanced Server product and four nodes in
the Datacenter Server product. Neither Windows Server 2003, Standard
Edition, nor Windows 2000 Server supports server clusters at all.
Planning
Although
Windows Server 2003, Enterprise Edition, and Windows Server 2003,
Datacenter Edition, both support server clustering, you cannot create a
cluster with computers running both versions of the operating system.
All your cluster nodes must be running either Enterprise Edition or
Datacenter Edition. You can, however, run Windows 2000 Server in a
Windows Server 2003, Enterprise Edition, or Windows Server 2003,
Datacenter Edition, cluster. |
Network Load Balancing
Network Load
Balancing (NLB) is another type of clustering that provides high
availability and high reliability, with the addition of high scalability
as well. NLB is intended for applications with relatively small data
sets that rarely change (or may even be readonly), and that do not have
long-running in-memory states. These are called stateless applications,
and typically include Web, File Transfer Protocol (FTP), and virtual
private network (VPN) servers. Every client request to a stateless
application is a separate transaction, so it is possible to distribute
the requests among multiple servers to balance the processing load.
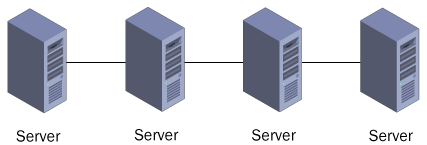
Instead of being
connected to a single data source, as in a server cluster, the servers
in an NLB cluster all have identical cloned data sets and are all active
nodes (see Figure 2).
The clustering software distributes incoming client requests among the
nodes, each of which processes its requests independently, using its own
local data. If one or more of the nodes should fail, the others take up
the slack by processing some of the requests to the failed server.
|
Network
Load Balancing is clearly not suitable for stateful applications such as
database and e-mail servers, because the cluster nodes do not share the
same data. If one server in an NLB cluster were to receive a new record
to add to the database, the other servers would not have access to that
record until the next database replication. It is possible to replicate
data between the servers in an NLB cluster, for example, to prevent
administrators from having to copy modified Web pages to each server
individually. However, this replication is an occasional event, not an
ongoing occurrence.
|
Network
Load Balancing provides scalability in addition to availability and
reliability, because all you have to do when traffic increases is add
more servers to the cluster. Each server then has to process a smaller
number of incoming requests. Windows Server 2003, Standard Edition,
Windows Server 2003, Enterprise Edition, and Windows Server 2003,
Datacenter Edition, all support NLB clusters of up to 32 computers.
Off the Record
There
is also a third type of clustering, called component load balancing
(CLB), designed for middle-tier applications based on Component Object
Model (COM+) programming components. Balancing COM+ components among
multiple nodes provides many of the same availability and scalability
benefits as Network Load Balancing. The Windows Server 2003 operating
systems do not include support for CLB clustering, but it is included in
the Microsoft Windows 2000 Application Center product. |
Exam Tip
Be
sure you understand the differences between a server cluster and a
Network Load Balancing cluster, including the hardware requirements, the
difference between stateful and stateless applications, and the types
of clusters supported by the various versions of Windows Server 2003. |
