FRS was implemented in Windows 2000 to
perform functions similar to the NTLmRepl service in Windows NT. FRS was
designed to replicate the contents of SYSVOL (GPOs and scripts) and
Distributed File System (DFS) replica link-targets. NTFRS, or File
Replication Service, communicates with replication partners to determine
when changes are made to the replica set (SYSVOL or DFS) and replicates
that data to all downstream partners. It is a multithreaded,
multimaster replication engine. FRS relies on AD for its replication
topology (NTDS connection objects) and specific replica set information,
such as partners. FRS is dependant upon AD objects and AD replication,
which in turn depends on connectivity, DNS, and RPC (Remote Procedure
Calls). This is vital to remember when troubleshooting.
FRS uses its own service, the File Replication
Service, to identify replication partners, determine when file changes
in the SYSVOL or replicated branches of the DFS tree have occurred, and
replicate that data to all downstream partners. It is multithreaded,
uses a multimaster replication model, and relies on the AD replication
infrastructure for sites, connections, and so on.
1. Basic Operation
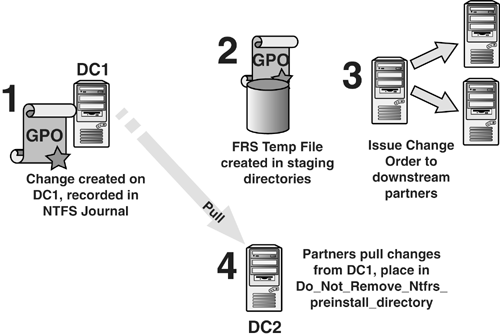
Basic FRS operation is illustrated in Figure 1.
The first step is a GPO modified on DC1. A temporary copy of the file
is then placed in the staging directories. In step 3, a change order is
issued to the downstream partner, DC2; and in step 4, the downstream
partner, DC2, receives the change order and pulls the file from DC1's
staging directory to DC2's Do_Not_Remove_NtFrs_ Preinstall_Directory.
The file is then moved to the proper folder. When all downstream
partners have pulled the file, the file is removed from DC1's staging
directories.
2. Replica Set Structure
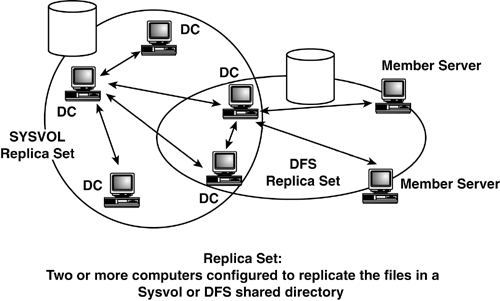
There are two basic types of replica sets: SYSVOL and DFS, sometimes referred to as non-SYSVOL. Figure 2
shows this concept. SYSVOL contents exist only on DCs. Thus, all DCs
are in a replica set that replicates SYSVOL information. DFS servers,
however, contain user-defined data and can exist on DCs, member servers,
or both. Note the two DCs in Figure 2 that participate in both FRS and DFS replica sets.
SYSVOL File Structure
This process is pretty simple when everything is
working, but unfortunately things break. Much of this depends on AD
replication, so if AD replication to a certain DC breaks, then FRS also
gets in trouble. Because AD is also a multimaster engine, each DC has
its own version of reality, until replication takes place and all DCs
share the same data. Thus, a DC that falls behind in replication is out
of touch with reality.
A junction point (also referred to as reparse point,
directory junction, and volume mount point) is a physical location on a
hard disk that points to another location on a disk or storage device.
Think of junction points as links in the file system—sort of a tunnel
that binds two ends into one because it connects two locations on the
disk to each other. SYSVOL uses junction points to manage a single
instance store by placing a junction point at the %systemroot%\sysvol\sysvol directory. For more information, refer to Microsoft KB article 324175 “Best Practices for SYSVOL Maintenance” and KB article 205524 “How to Create and Manipulate NTFS Junction Points.”
3. FRS Design Considerations
Any discussion of FRS topology design must include AD
replication topology design. Although FRS contains unique elements and
objects, such as replica members, subscriber objects, SYSVOL data, and
so forth, replication is effected over the framework of AD replication
components, such as NTDS connection objects, sites, and site links (to
name the important ones). Thus, an inefficient AD replication topology
results in an inefficient FRS topology, with errors and failures
resulting in both.
In FRS, it's not possible to provide coherent data in
a multimaster server environment composed of tens or hundreds of
members because not all servers might be connected at the same time and
even if they were, the cost to synchronize is prohibitive. Rather, the
contents of a replica tree in FRS are loosely coherent, meaning that
after all outside change has stopped and all objects are replicated, all
replica trees on all connected members will have the same data.
Efficient topology can minimize the effects of data latency.
Good topology is directly related to the overall
speed of replication. Tweaking the replication schedule from the default
can have far-reaching consequences. For instance, you might have a goal
of reducing replication traffic over a certain link between sites, so
you adjust the replication schedule to replicate every three hours and
only between 7 p.m. and 5 a.m. each day. This would significantly
increase the time to consistency. For instance, if a Group Policy with a
security setting change was created at 10 a.m., it would not be
replicated until 7 p.m. that evening. With replication latency in the
mix, it might not get to all the DCs by 5 a.m. the next morning and have
to wait until the next replication period. The point here is not to
specify that a restrictive schedule is good or bad, but you must know
the consequences when you implement it.
4. Common FRS Problems and Solutions
FRS was definitely an evolutionary product in Windows
2000 with a common troubleshooting step being checking to see whether
you have the latest FRS hotfix. During Windows Server 2003 development,
Microsoft took these problem issues and created better solutions or at
least workarounds and ported them into Windows 2000 Service Packs
starting at SP2. As of this writing, S4 has been released that is
current with all FRS hotfixes. However, if you have a problem with FRS,
contact Microsoft to see if there is a current FRS hotfix. Hopefully
these hotfixes will not be so common, and FRS will be more stable. SP4
and Windows Server 2003 have made FRS fairly stable and not so prone to
error. However, this depends on the Administrator being aware of the
issues and understanding how to design the FRS structure to take
advantage of the fixes. These issues and best practices are described in
this section.
Junction Points
Removal of the junction point causes FRS replication
to fail. Likewise, copying the junction point creates another SYSVOL
tree. I saw a case where an Admin copied the entire SYSVOL tree to his
DC's desktop for backup. Because he copied the junction point, it set up
a duplicate SYSVOL tree and replicated. That DC had two SYSVOL trees.
Deleting the whole directory would have wiped out the SYSVOL tree on all
DCs in the domain. We resolved it by using the ResKit utility,
LinkD.exe, to delete the junction point in the duplicate directory, and
then deleted the directory. What he should have done was to copy just
the contents of the %systemroot%\policies and %systemroot%\scripts to a directory outside of %systemroot%\sysvol.
Morphed Directories
Morphed directories and files have been replicated,
but an exact copy already exists on the target. FRS knows which one is
most recent, and protects the original by creating a copy, which is
referred to as a morph. These duplicate
directories or files are renamed by prefixing the name with
NtFrs_xxxxxxxx where xxxxxxxx is a random eight-digit number. This
usually occurs if an Authoritative Restore occurs, forcing an entire
SYSVOL tree to replicate to multiple replica set members at the same
time. The Administrator must decide which is the newest, most correct
version to keep. If it's the morphed version, delete the original and
rename the morphed folder by eliminating the NtFrs_xxxxxxxx prefix. If
it's the original, simply delete the morphed version. Morphed directory
contents are not replicated and if it is more recent data, you might
lose changes if the cause of the morphed directory is not resolved. For
more information, see Microsoft KB article 328492, “Folder Name Is
Changed to FolderName_NtFrs_ <xxxxxxxx>.”
Version Vector Joins
When you join a new DC to the domain, a version vector is created from the new DC to each of the other DCs in the domain. This also takes place when there is a failover to a new DC for AD
replication. In Windows 2000,
this was a parallel process that caused a lot of grief because it pulled
the entire SYSVOL tree from every DC in the domain at the same time—in
parallel. This caused problems not only in network performance, but also
in DC performance as it has the potential for taking a DC offline
during this process. Windows Server 2003 and Windows 2000 SP3+ corrected
this by making it a serialized process. The new DC does a vvjoin during
demotion, and after that is complete, contacts other DCs in the domain
one at a time for changes. If the source DC is up-to-date, the vvjoin is
still done to the others, but no replication takes place.
Staging Area Problems and Excessive FRS Replication
This is an oldie but a goodie. There are still many
Administrators who are not aware of this important issue. Changes made
to files in SYSVOL create temporary files in the staging directory %systemroot%\sysvol\staging\domain. The junction point %Systemroot%\sysvol\staging areas\<domain name>
points to that location as well, so it appears that the files are
duplicated when they are not. The junction point is simply a pointer.
The file stays in the staging directories until all downstream partners
have pulled it.
Some programs that scan the files, such as antivirus
and defragmenter programs, as well as setting file system policy in a
Group Policy to apply to the SYSVOL tree, modified the security
descriptors of the files, which forced a change order, causing all files
in the SYSVOL tree to be copied to the two staging directories. This
resulted in huge numbers of files dumped into the staging directories,
exceeding the 660MB limit on the staging directories, causing FRS
replication to stop. There was a Registry key to increase this limit,
but that was just to give you some breathing room until you could
resolve the problem (see Microsoft KB article 264822, “File Replication
Service Stops Responding When Staging Area is Full”). This functionality
has changed in Windows Server 2003 and Windows 2000 SP3+. As noted in
Microsoft KB article 307319, “Changes to the File Replication Service,”
when the staging gets to 90% of the capacity, FRS deletes the oldest
files until the directory is only 60% full, and keeps replication going.
This continues if the directory gets filled up again—never allowing
staging files to exceed the limit.
note
Note that most antivirus vendors now have
FRS-friendly versions of their products. If you ask and they don't know,
find another vendor. This is a well-known problem and they should have a
solution. For more information, see Microsoft KB article 815263,
“Antivirus, Backup, and Disk Optimization Programs That Are Compatible
with NTFRS.”
Microsoft made significant improvements on this issue in Windows 2000 SP3 and Windows Server 2003 in two ways:
Reduction of excessive FRS replication
(Microsoft KB article 811370, “Issues that are fixed in the post-Service
Pack 3 release of Ntfrs.exe”):
FRS detects these unnecessary updates to the files (presumably based on
frequency) and suppresses the updates. The Administrator is notified
with event ID 13567 in the NTFRS event log. This was available as a
Windows 2000 post-SP3 hotfix 811370 as well as Windows Server 2003, and
is described in Microsoft KB article 315045, “FRS Event 13567 is
Recorded in the File Replication Service Event Log After you Install
Service Pack 3.”
Replication is not stopped if staging directory is filled (Microsoft KB article 307319):
In Windows 2000 SP3+ and Windows Server 2003, when the staging directory
gets to 90% capacity, the oldest files are deleted until it is reduced
to 60% capacity, thus preventing replication from stopping and taking
the DC offline. Note that this is not a “fix.” The fix is to find out
what is causing this huge volume of files to be dumped into the staging
area.
note
There is really no reason to experience staging area
problems with Windows Server 2003 or Windows 2000 SP3+ if you are using
FRS-aware versions of defragmenters and antivirus products. These new
versions, combined with the new features in FRS that make it more
tolerant of error conditions, will reduce or eliminate most common FRS
issues.
Journal Wrap
When changes are made to files in the NTFS, an entry
is made in the NTFS journal indicating a new file, a deletion, or a
modification. When the NTFS journal gets filled, it wraps and writes
over the oldest entries. FRS uses the NTFS journal to detect files in
SYSVOL that have changes so it can start replication. If a lot of files
are changed and FRS gets overwhelmed, the NTFS journal will fill and
begin overwriting the oldest entries. This can cause FRS to get lost
because it needs those entries. The NTFS journal in Windows Server 2003
was simply increased to 128MB, a dramatic increase over the Windows 2000
limit of 32MB. This should significantly reduce the opportunity for
experiencing journal wrap errors and the resulting nonauthoritative
restore.
Authoritative and Nonauthoritative Restore
Authoritative and nonauthoritative restore in FRS are not
related to authoritative and nonauthoritative restore in AD, using the
Ntdsutil.exe tool. In regard to FRS, these terms refer to a restore of
the SYSVOL tree only.
Authoritative Restore
Authoritative restore uses a “big hammer” approach to
getting SYSVOL on all DCs in sync with a single source. Although
Microsoft now says it was never intended to be a “silver bullet”
solution to FRS issues, it was used extensively during the days when
antivirus products were causing huge numbers of files to be dumped into
the staging areas. Although this created other problems, it was the best
we could do at the time to recover. Today, there probably aren't a lot
of valid reasons to do an authoritative restore. In fact, Microsoft says
that authoritative restore is used too much as a quick fix rather than
finding the root cause, and is an excellent way to bring down a domain.
Authoritative restore also wipes out all FRS data—Group Policy
templates, associated .ini files, scripts, and anything you have placed
in the SYSVOL directory tree.
Authoritative restore usage assumes that all DCs in
the domain hold corrupt copies of the SYSVOL tree and that the NTFRS
database is corrupt. This needs to be investigated and resolved to
prevent this situation from reoccurring. This condition is a rarity and
the Administrator should only use authoritative restore as a last
resort.
So, now that you are properly frightened about using
this, you can refer to Microsoft KB article 315457, “How to Rebuild
SYSVOL and Its Content in a Domain,” for details on how to do it. The KB
article basically says to 1) back up SYSVOL; 2) turn FRS off on all
DCs; 3) set the “burflags” Registry value; 4) pick a source DC, delete
SYSVOL, and copy the backed-up version to this DC; and 5) turn SYSVOL on
the source and then one DC at a time until they are all in sync.
The confusing thing to me was what was meant by
“SYSVOL.” According to the author of the KB artilce, it means the data
in the SYSVOL tree. You must leave the SYSVOL structure in place and
just replace the data. Furthermore, the “data” in SYSVOL really boils
down to the contents of %systemroot%\sysvol\sysvol\<domainname>\policies and %systemroot%\sysvol\sysvol\<domainname>\scripts,
unless you are one of those mavericks who create your own directories
and use FRS to replicate your own data, in which case you'd have to
include them. Note that this data will populate into the %systemroot%\sysvol\policies
directory via the junction point, so no need to replace it in both
places. If you delete the SYSVOL tree, you'll also delete the junction
point, which will replicate and delete all the SYSVOL data on all DCs;
this is what the authoritative restore does anyway, but then you have to
re-create it, so just don't do it.
Nonauthoritative Restore
Nonauthoritative restore is the “little hammer”
approach. Unlike the authoritative restore, which syncs all DCs to a
common source, nonauthoritative restore syncs one out-of-date DC with an
up-to-date source. Thus, only one source and one satellite are
involved. This is less intrusive than the authoritative restore because
it can mess up only two DCs rather than all of them.
In this case, the FRS is stopped on the target (out-of-date) DC, the Burflags value is set to D2 on the target and the source, and then FRS is started on the target.
Unlike authoritative restore, there are good
reasons for this. When a DC gets out of sync and can't catch up—when a
serious FRS error occurs such as a journal wrap error which can disable a
DC—action must be taken to get the data in sync between the broken DC
and a DC with a good copy of the FRS (SYSVOL) data. Windows 2000
behavior is to automatically perform a nonauthoritative restore on a DC
that experiences an error such as journal wrap by having the out-of-date
DC contact a partner and pull the SYSVOL tree. However, because this is
intrusive and disables the DC for a period of time, Windows 2000 SP3
and Windows 2003 do not do this automatically. Rather, they log event
13568 and let the Administrator do it at his or her leisure, presumably
during off hours. Refer to Microsoft KB article 307319.
