To fully appreciate the purpose and importance of the ESB, we need to understand a bit of the history that led to its creation.
Application Integration 101
In the beginning, we had standalone systems called silo-based
applications. They created isolated silos of information to address
specific, single-purpose automation requirements. They were designed to
be self-contained with no need to interact with other applications (Figure 1).

Integration at this stage in the
evolution meant redundant data entry or some form of file dumping to
get information out of one system and into another. The barriers between
applications were quite substantial.
Next, applications became more
tightly bound by means of point-to-point integration channels. Now data
could flow more readily between applications, but it turned out that
this sort of integration leads to long-term problems, the most notable
being the inherent brittleness of the resulting architecture. If either
side of a point-to-point integration channel changed its contract, the
other would also need to be modified or the integration would cease to
function.
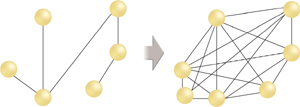
Point-to-point
integration became increasingly difficult to manage as its proliferation
resulted in increasingly large and convoluted enterprise environments (Figure 2).
In many cases, IT resources would be devoting significant effort and
resources to preserving the existing integration architectures, rather
than solving new and emerging business
requirements. Changes to the integration architectures were inherently
difficult and time consuming to accommodate and as the number of
connections to a single point increased, versioning that point meant
updating an increasing number of integration clients. Versioning and the
ultimate decommissioning of integrated applications often led to the
need to “rip-and-replace” segments of an enterprise.
Note
It is important to note
that silo-based applications and integrated architectures can just as
easily be implemented in cloud computing environments (such as Windows
Azure) as they can in traditional on-premise environments. Fortunately,
the application of service-orientation principles provides us with the
opportunity to avoid the mistakes of the past.
Following the
point-to-point integration phase, came the advent of messaging-based
middleware, event-driven message exchange patterns, and the notion of
the hub-and-spoke model. With the resulting integration architecture, a
client application sends a message to a central hub that is published to
one or more spokes, or message recipients (Figure 3).
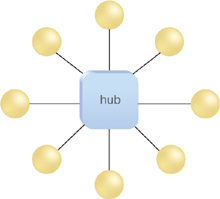
The relationship between
the publisher and recipients can be defined by configuration, or by
using a publish-and-subscribe messaging framework. Following this
approach, an application would publish a message that is received by
appropriate subscribers.
The
two applications involved are naturally loosely coupled because they do
not communicate directly with each other, but rather both communicate
only with the central hub. Should a third participating application be
introduced, it could also subscribe and receive messages and process
them without affecting the relationship of the other two applications.
The BizTalk Hub-Bus Model
When BizTalk Server 2004 was released, it took the publish-and-subscribe model a step further into a hybrid model called hub-bus
that combined the hub-and-spoke model with bus topologies. In a hub-bus
model, functionality can be distributed across multiple machines, with
multiple hubs sharing a centralized bus (Figure 4).
As a result, there is no single point of failure. Configuration can be
centralized, as are capabilities such as capturing operational and
business metrics.
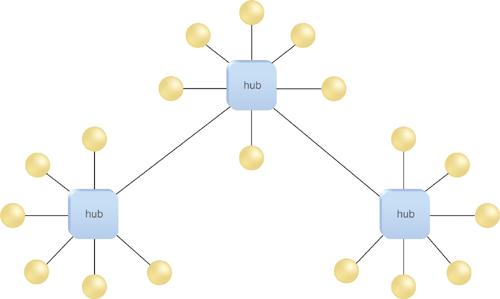
Conceptually, you can think
of a BizTalk host as a hub, and all the machines running an instance of
that host form a logical hub. The bus encompasses the BizTalk MessageBox
(messaging data store) and Management Database (configuration data
store), as well as the centralized operational and management
capabilities and tools.
From
a functionality stratification perspective, a receiving hub combines
potentially numerous host instances across multiple machines to provide
receiving functionality. After a message is received and stored in the
MessageBox, a processing hub picks it up and acts on it. This is an
instance of the processing host instance running on a given machine or
collection of machines.
This architecture is
intended to be scalable in that you can adjust the processing power of a
hub by adding more machines and host instances. The MessageBox
configuration database and business activity monitoring (BAM) tracking
infrastructure use SQL Server databases that can be clustered and made
fault tolerant.
However, this
architecture did have limitations. For example, it was not possible to
geo-distribute the hubs, as they shared a common backend database that
introduced network latency. In addition, there was no notion of runtime
resolution of artifacts.
