Tracing Content Through the Build System
How does content go from an
idea in the mind of an artist to something represented in your game?
Well, so far, you have added the files to your content projects. Magic
happens, and then you load the content in your game!
When a file is first
added to a content project, its extension is checked. If there is a
content importer for the extension, the file’s Build Action is set to Compile.
It is now set to go through the content pipeline. During your
application’s build task, your content also is built. This is done in
essentially a two-step process. First, your content is imported, and
this is normally done by reading the data in the file on disk, and
performing some operation(s) on it. After the data has been imported, it
can be optionally processed, which enables you to massage the data if
needed.
After the content has been imported and processed, it writes out to a new file that is called assetname.xnb, where assetname is the name of the asset and xnb is the extension (short for XNA Binary). While your game runs, and you call Content.Load for that asset, the
.xnb binary file opens, reads back in, and the content objects are
created.
Why do you need to have a
content pipeline? In all actuality, you do not, but without a pipeline
means that the importing and processing of the content needs to happen
during the runtime of your game! For example, say that you create a 2D
game to run on the Xbox 360, you have fifty textures in your game, and
each one is 512 by 512 pixels.
You created these textures in an
art creation tool (for example, Photoshop or Paint), so they are 32-bit
PNG files. Without the content pipeline, you need to open each file and
load the data. With so many large textures though, you probably want to
use DXT compression on the textures. Because the file you just loaded is
a 32-bit PNG file, you will have to do the compression at runtime, and
then push the compressed data into the texture. Wait though, you aren’t
done yet! Your computer processor stores data in little-endian format,
but the Xbox 360 CPU expects the data to be big-endian! So you’ll also
need to byte swap all of the data before you DXT compress it.
Let’s say it takes
approximately 5ms to read the file from the disk. It then takes another
20ms to swap all the bytes, and another 30ms to DXT compress the
texture. Each file is now taking 55ms to process, and with a total of 50
files, you’re looking at 2750ms to load the data. That’s an almost
three-second load time!
Now compare that to a
similar scenario using the content pipeline. It still takes 20ms to swap
all the bytes and 30ms to DXT compress the texture. However, the 2500ms
it takes to do the two operations on 50 files occurs while your game is
building, not while it runs. While it runs, it reads only the file off
disk. Because the texture is compressed already at build time, reading
the file off the disk takes half the time now that the data is smaller!
So instead of having an almost three-second load time, your game now has
a 125ms load time, which is not even five percent the time it took
before. You’re doing the same operations, but because you moved the bulk
of the work out of the runtime of the game and into the build time,
your game is faster.
Note
The time spans used in
this example were purely hypothetical and used to illustrate a point.
Don’t consider them actual measurements.
Content Processors
Create a new Game project, and add an image to your content project. The code in the downloadable example uses cat.jpg. Then, draw that texture by replacing your Draw method with the following:
protected override void Draw(GameTime gameTime)
{
GraphicsDevice.Clear(Color.CornflowerBlue);
spriteBatch.Begin();
spriteBatch.Draw(Content.Load<Texture2D>("cat"),
GraphicsDevice.Viewport.Bounds, Color.White);
spriteBatch.End();
}
Replace the cat asset name in Content.Load
with whatever asset you used if you used something else. This does
nothing more than render your image to fill the entire game window.
However, now let’s mix things up with a different type of content
processor.
Note
You might wonder why the content wasn’t stored in a variable and is instead loaded every call to Draw. The content manager caches assets for you, so you do not get a new texture every time you draw this.
To add a new project to your solution to hold your content pipeline extension, right-click the solution, choose Add->New Project, and choose Content Pipeline Extension Library as in Figure 1 (you can name it whatever you like).
This creates a new
content pipeline extension projection in your solution, with a default
processor that doesn’t actually do much of anything. Because you will
update this though, and you want to change how your content is built,
you need to add a reference to the new project to your content project.
Right-click the References in your Content project and select Add Reference. Then choose the content pipeline extension project you just created from the Projects tab, as in Figure 2.
For this example, you take
over the processing phase mentioned earlier. Because you modify the
texture, you don’t need to import it—you can let the default importer
handle that. To create a
content processor, you need to create a class and derive from ContentProcessor, so delete the class that was generated for you and replace it with the following:
[ContentProcessor(DisplayName = "InvertColorsProcessor")]
public class InvertColorsProcessor : ContentProcessor<Texture2DContent, Texture2DContent>
{
}
Also notice that the types are Texture2DContent, not Texture2D
objects themselves. Although many times the runtime version of an
object and the build-time version of an object are the same , sometimes you might need (or want) to have
different properties/data/methods on your build-time type.
The last thing to mention before moving on is the first thing your class has, namely the ContentProcessor attribute. The DisplayName
property of this attribute enables you to specify what name is
displayed when you see the processor in Visual Studio. The name here
implies how you process the texture.
In order to do some actual processing, override the Process
method in your class. Because it is an abstract method, if you do not
do so, you get a compile error. Add the following override to your
class:
public override Texture2DContent Process(Texture2DContent input,
ContentProcessorContext context)
{
// Convert the input to standard Color format, for ease of processing.
input.ConvertBitmapType(typeof(PixelBitmapContent<Color>));
foreach (MipmapChain imageFace in input.Faces)
{
for (int i = 0; i < imageFace.Count; i++)
{
PixelBitmapContent<Color> mip = (PixelBitmapContent<Color>)imageFace[i];
// Invert the colors
for (int w = 0; w < mip.Width; w++)
{
for (int h = 0; h < mip.Height; h++)
{
Color original = mip.GetPixel(w, h);
Color inverted = new Color(255 - original.R,
255 - original.G, 255 - original.B);
mip.SetPixel(w, h, inverted);
}
}
}
}
return input;
}
After the conversion (if it was even needed), loop through each MipmapChain in the texture via the Faces property. In the case of a Texture2DContent, it is only a single Face,
and a cube texture has six. You then can enumerate through each mip
level in the face. After you have the current mip level, get each
pixel’s color by using the GetPixel method, create a new color that is an inversion of the original color, and then use the SetPixel method to update with the new inverted color. At the end, return the Texture2DContent you are modifying and you’re done. You now have a content processor that will invert all of the colors in a texture.
Notice
that when running the example, nothing at all has changed. The colors
certainly aren’t inverted; it’s the same image as it was last time!
That’s because you never changed the actual processor your application
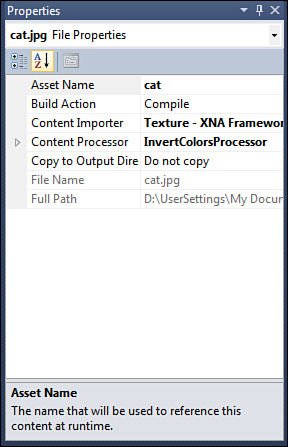
uses. Select the image you added to the content project and update its Content Processor to the InvertColorsProcessor, as in Figure 3. The name shown here is whatever you used for the DisplayName in the attribute before your class previously.
Now when you run the
application, notice that your original image is shown with the colors
inverted because the processor you wrote is used, as in Figure 4.

Now, this is all well and good,
but it isn’t customizable. The image simply has its colors inverted. A
way to customize the processors would be useful, and luckily, you can do
just that. Add a couple properties to control how the colors are
inverted (allow them to form blocks):
[DefaultValue(false)]
[DisplayName("BlockyInversion")]
[Description("Should the inversion be done in blocks?")]
public bool ShouldCauseBlocks
{
get;
set;
}
[DefaultValue(20)]
[DisplayName("BlockSize")]
[Description("The size in pixels of the blocks if a blocky inversion is done")]
public int BlockSize
{
get;
set;
}
The properties themselves are simple enough—a bool to determine whether you should use the blocky code (that you haven’t written yet), and an int
to specify the size of the blocks. Notice that the attributes on the
properties enable you to control how the properties are displayed in
Visual Studio. If you compile your solution now, and then look at the
properties of your image in the content project, you now see two extra
properties available, as in Figure 5.
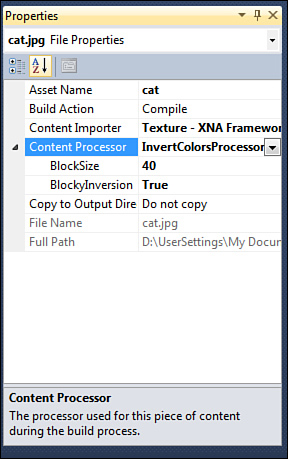
Note
If you get compile errors on the attributes, add a using System.ComponentModel clause to the code file.
Notice how the property name in the Visual Studio window is the name specified in the DisplayName attribute, and not the real property name. Set the BlockyInversion property to true. To update the processor to respond to the properties, add the following code before the SetPixel call in your Process method:
if (ShouldCauseBlocks)
{
if ((h % BlockSize > (BlockSize / 2))
|| (w % BlockSize > (BlockSize / 2)))
{
inverted = original;
}
}
Running the application now causes your image to be partially inverted, and partially not, forming a blocky type pattern, as in Figure 6.
Remember that all of the inversion is done at compile time. The texture
that is loaded into memory is already modified, so none of this happens
at runtime.

Debugging Content Pipeline Extensions
Because the content
pipeline is executed during compilation time, you can’t just “run the
application” to debug the code you’re writing in your content pipeline
extension. In reality, the application that is running the code is
Visual Studio (or MSBuild, depending on how you’re building), which
means that you need to do something else for debugging.
One option is to use a
second version of Visual Studio (or whichever debugger you use), and use
it’s Attach to Process command to attach to the original Visual Studio
instance. This enables you to put break points in your content pipeline
extension code and debug. However, this makes Visual Studio run
remarkably slow, so it isn’t recommended.
An easier solution is to force the compilation of your content to give you the opportunity to debug, which you can do using the Debugger.Launch method in the System.Diagnostics
namespace. When the line of your code is executed, it forces the system
to attempt to launch the debugger, and you see a dialog much like Figure 7. Using this method, you can then debug your content pipeline extension.
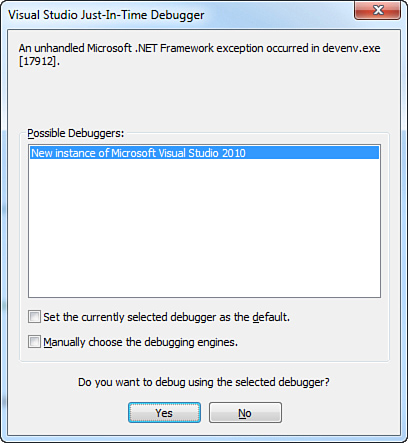
Note that if you select No in this dialog, it kills your Visual Studio session.
Now that you have a basic
understanding of the flow of the content pipeline (and some of the
reasons why you might want to use it), let’s dive right in and see some
examples.
