This section describes how Tailspin designed one
functional area of the Surveys application for scalability. Tailspin
anticipates that some surveys may have thousands, or even hundreds of
thousands of respondents, and Tailspin wants to make sure that the
public website remains responsive for all users at all times. At the
same time, survey owners want to be able to view summary statistics
calculated from the survey responses to date.
1. Goals and Requirements
The Surveys application currently
supports three question types: free text, numeric range (values from
one to five), and multiple choice. Survey owners must be able to view
some basic summary statistics that the application calculates for each
survey, such as the total number of responses received, histograms of
the multiple-choice results, and aggregations such as averages of the
range results. The Surveys application provides a pre-determined set of
summary statistics that cannot be customized by subscribers. Subscribers
who want to perform a more sophisticated analysis of their survey
responses can export the survey data to a SQL Azure instance.
Calculating summary statistics is an expensive operation if there are a large number of responses to process.
Because of the expected
volume of survey response data, Tailspin anticipates that generating the
summary statistics will be an expensive operation because of the large
number of storage transactions that must occur when the application
reads the survey responses. However, Tailspin does not require the
summary statistics to be always up to date and based on all of the
available survey responses. Tailspin is willing to accept a delay while
the application calculates the summary data if this reduces the cost of
generating them.
The public site where
respondents fill out surveys must always have fast response times when
users save their responses, and it must record the responses accurately
so that there is no risk of any errors in the data when a subscriber
comes to analyze the results.
| There are also integration tests that verify the end-to-end behavior of the application using Windows Azure storage. |
The developers at Tailspin also
want to be able to run comprehensive unit tests on the components that
calculate the summary statistics without any dependencies on Windows
Azure storage.
2. The Solution
To meet the
requirements, the developers at Tailspin decided to use a worker role to
handle the task of generating the summary statistics from the survey
results. Using a worker role enables the application
to perform this resource-intensive process as a background task,
ensuring that the web role responsible for collecting survey answers is
not blocked while the application calculates the summary statistics.
Based on the framework for
worker roles that the previous section outlined, this asynchronous task
is one that will by triggered on a schedule, and it must be run as a
single instance process because it updates a single set of results.
The application can use
additional tasks in the same worker role to perform any additional
processing on the response data; for example, it can generate a list of
ordered answers to enable paging through the response data.
To calculate the
survey statistics, Tailspin considered two basic approaches. The first
approach is for the task in the worker role to retrieve all the survey
responses to date at a fixed time interval, recalculate the summary
statistics, and then save the summary data over the top of the existing
summary data. The second approach is for the task in the worker role to
retrieve all the survey response data that the application has saved
since the last time the task ran, and use this data to adjust the
summary statistics to reflect the new survey results.
The first approach is the
simplest to implement, because the second approach requires a mechanism
for tracking which survey results are new. The second approach also
depends on it being possible to calculate the new summary data from the
old summary data and the new survey results without re-reading all the
original survey results.
| You can use a queue
to maintain a list of all new survey responses. This task is still
triggered on a schedule that determines how often the task should look
at the queue for new survey results to process. |
Note:
You
can recalculate all the summary data in the Surveys application using
the second approach. However, suppose you want one of your pieces of
summary data to be a list of the 10 most popular words used in answering
a free-text question. In this case, you would always have to process
all of the survey answers, unless you also maintained a separate list of
all the words used and a count of how often they appeared. This adds to
the complexity of the second approach.
The key difference between the two approaches is cost. The graph in Figure 1
shows the result of an analysis that compares the costs of the two
approaches for three different daily volumes of survey answers. The
graph shows the first approach on the upper line with the Recalculate
label, and the second approach on the lower line with the Merge label.
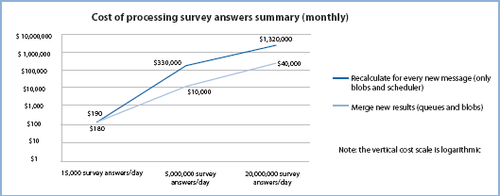
The graph clearly shows how
much cheaper the merge approach is than the recalculate approach after
you get past a certain volume of transactions. The difference in cost
is due almost entirely to the transaction costs associated with the two
different approaches. Tailspin decided to implement the merge approach
in the Surveys application.
Note:
The
vertical cost scale on the chart is logarithmic. The analysis behind
this chart makes a number of “worst-case” assumptions about the way the
application processes the survey results. The chart is intended to
illustrate the relative difference in cost between the two approaches;
it is not intended to give “hard” figures.
It is possible to optimize
the recalculate approach if you decide to sample the survey answers
instead of processing every single one when you calculate the summary
data. You would need to perform some detailed statistical analysis to
determine what proportion of results you need to select to calculate the
summary statistics within an acceptable margin of error.
In the
Surveys application, it would also be possible to generate the summary
statistics by using an approach based on MapReduce. The advantage of
this approach is that it is possible to use multiple task instances to
calculate the summary statistics. However, Tailspin is willing to accept
a delay in calculating the summary statistics, so performance is not
critical for this task.
3. Inside the Implementation
Now is a good time to walk
through the code that implements the asynchronous task that calculates
the summary statistics in more detail. As you go through this section,
you may want to download the Visual Studio solution for the Tailspin Surveys application from http://wag.codeplex.com/.
3.1. Using a Worker Role to Calculate the Summary Statistics
The team at
Tailspin decided to implement the asynchronous background task that
calculates the summary statistics from the survey results by using a
merge approach. Each time the task runs, it processes the survey
responses that the application
has received since the last time the task ran; it calculates the new
summary statistics by merging the new results with the old statistics.
The worker role in the TailSpin.Workers.Surveys project periodically scans the queue for pending survey answers to process.
The following code example from the UpdatingSurvey ResultsSummaryCommand
class shows how the worker role processes each temporary survey answer
and then uses them to recalculate the summary statistics.
private readonly IDictionary<string, SurveyAnswersSummary>
surveyAnswersSummaryCache;
private readonly ISurveyAnswerStore surveyAnswerStore;
private readonly ISurveyAnswersSummaryStore
surveyAnswersSummaryStore;
public UpdatingSurveyResultsSummaryCommand(
IDictionary<string, SurveyAnswersSummary>
surveyAnswersSummaryCache,
ISurveyAnswerStore surveyAnswerStore,
ISurveyAnswersSummaryStore surveyAnswersSummaryStore)
{
this.surveyAnswersSummaryCache =
surveyAnswersSummaryCache;
this.surveyAnswerStore = surveyAnswerStore;
this.surveyAnswersSummaryStore =
surveyAnswersSummaryStore;
}
public void PreRun()
{
this.surveyAnswersSummaryCache.Clear();
}
public void Run(SurveyAnswerStoredMessage message)
{
this.surveyAnswerStore.AppendSurveyAnswerIdToAnswersList(
message.Tenant,
message.SurveySlugName,
message.SurveyAnswerBlobId);
var surveyAnswer =
this.surveyAnswerStore.GetSurveyAnswer(
message.Tenant,
message.SurveySlugName,
message.SurveyAnswerBlobId);
var keyInCache = string.Format(CultureInfo.InvariantCulture,
"{0}_{1}", message.Tenant, message.SurveySlugName);
SurveyAnswersSummary surveyAnswersSummary;
if (!this.surveyAnswersSummaryCache.ContainsKey(keyInCache))
{
surveyAnswersSummary = new
SurveyAnswersSummary(message.Tenant,
message.SurveySlugName);
this.surveyAnswersSummaryCache[keyInCache] =
surveyAnswersSummary;
}
else
{
surveyAnswersSummary =
this.surveyAnswersSummaryCache[keyInCache];
}
surveyAnswersSummary.AddNewAnswer(surveyAnswer);
}
public void PostRun()
{
foreach (var surveyAnswersSummary in
this.surveyAnswersSummaryCache.Values)
{
var surveyAnswersSummaryInStore =
this.surveyAnswersSummaryStore
.GetSurveyAnswersSummary(surveyAnswersSummary.Tenant,
surveyAnswersSummary.SlugName);
surveyAnswersSummary.MergeWith(
surveyAnswersSummaryInStore);
this.surveyAnswersSummaryStore
.SaveSurveyAnswersSummary(surveyAnswersSummary);
}
}
The Surveys application uses the Unity Application Block (Unity) to initialize an instance of the UpdatingSurveyResultsSummary Command class and the surveyAnswerStore and surveyAnswers SummaryStore variables. The surveyAnswerStore variable is an instance of the SurveyAnswerStore type that the Run method uses to read the survey responses from BLOB storage. The survey AnswersSummaryStore variable is an instance of the Survey AnswersSummary type that the PostRun method uses to write summary data to BLOB storage. The surveyAnswersSummaryCache dictionary holds a SurveyAnswersSummary object for each survey.
Note:
Unity
is a lightweight, extensible dependency injection container that
supports interception, constructor injection, property injection, and
method call injection. You can use Unity in a variety of ways to help
decouple the components of your applications, to maximize coherence in
components, and to simplify design, implementation, testing, and
administration of these applications.
For
more information about Unity and to download the application block, see
the patterns & practices Unity page on CodePlex (http://unity.codeplex.com/).
The PreRun
method runs before the task reads any messages from the queue and
initializes a temporary cache for the new survey response data.
The Run
method runs once for each new survey response. It uses the message from
the queue to locate the new survey response, and then it adds the
survey response to the SurveyAnswersSummary object for the appropriate survey by calling the AddNewAnswer method. The AddNewAnswer method updates the summary statistics in the surveyAnswersSummaryStore instance. The Run method also calls the AppendSurveyAnswerIdToAnswersList method to update the list of survey responses that the application uses for paging.
The PostRun
method runs after the task reads all the outstanding answers in the
queue. For each survey, it merges the new results with the existing
summary statistics, and then it saves the new values back to BLOB storage.
The worker role uses some “plumbing” code developed by Tailspin to invoke the PreRun, Run, and PostRun methods in the Updating SurveyResultsSummaryCommand class on a schedule. The following code example shows how the Surveys application uses the “plumbing” code in the Run method in the worker role to run the three methods that comprise the job.
public override void Run()
{
var updatingSurveyResultsSummaryJob =
this.container.Resolve
<UpdatingSurveyResultsSummaryCommand>();
var surveyAnswerStoredQueue =
this.container.Resolve
<IAzureQueue<SurveyAnswerStoredMessage>>();
BatchProcessingQueueHandler
.For(surveyAnswerStoredQueue)
.Every(TimeSpan.FromSeconds(10))
.Do(updatingSurveyResultsSummaryJob);
var transferQueue = this.container
.Resolve<IAzureQueue<SurveyTransferMessage>>();
var transferCommand = this
.container.Resolve<TransferSurveysToSqlAzureCommand>();
QueueHandler
.For(transferQueue)
.Every(TimeSpan.FromSeconds(5))
.Do(transferCommand);
while (true)
{
Thread.Sleep(TimeSpan.FromSeconds(5));
}
}
This method first uses Unity to instantiate the UpdatingSurvey ResultsSummaryCommand object that defines the job and the AzureQueue object that holds notifications of new survey responses.
The method then passes these objects as parameters to the For and Do “plumbing” methods. The Every “plumbing” method specifies how frequently the job should run. These methods cause the plumbing code to invoke the PreRun, Run, and PostRun method in the UpdatingSurveyResultsSummaryCommand class, passing a message from the queue to the Run method.
The preceding code example also shows how the worker role initializes the task defined in the TransferSurveysToSqlAzure Command class that dumps survey data to SQL Azure. This task is slightly simpler and only has a Run method.
You should tune the frequency at which these tasks run based on your expected workloads by changing the value passed to the Every method.
Finally, the method uses a while loop to keep the worker role instance alive.
Note:
The For, Every, and Do methods implement a fluent API for instantiating tasks in the worker role. Fluent APIs help to make the code more legible.
3.2. The Worker Role “Plumbing” Code
The “plumbing” code in the worker role enables you to invoke commands of type IBatchCommand or ICommand by using the Do method, on a Windows Azure queue of type IAzureQueue by using the For method, at a specified interval. Figure 2 shows the key types that make up the “plumbing” code.
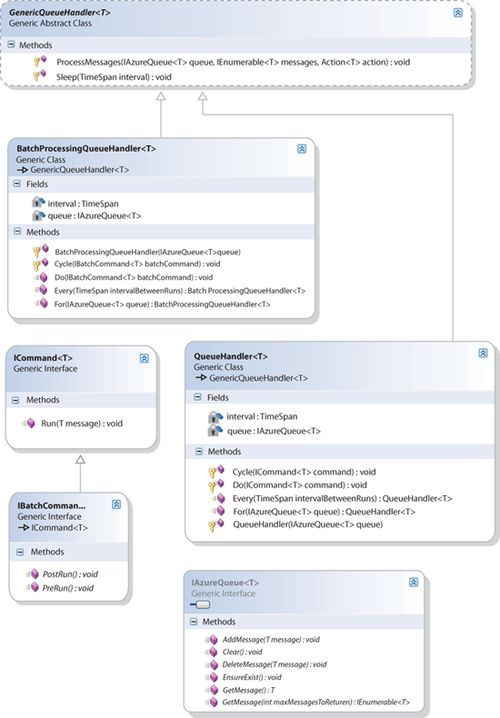
Figure 2 shows both a BatchProcessingQueueHandler class and a QueueHandler class. The QueueHandler class runs tasks that implement the simpler ICommand interface instead of the IBatch Command interface. The discussion that follows focuses on the Batch ProcessingQueueHandlerTask that the application uses to create the summary statistics.
The worker role first invokes the For method in the static Batch ProcessingQueueHandler class, which invokes the For method in the BatchProcessingQueueHandler<T> class to return a Batch ProcessingQueueHandler<T> instance that contains a reference to the IAzureQueue<T> instance to monitor. The “plumbing” code identifies the queue based on a queue message type that derives from the AzureQueueMessage type. The following code example shows how the For method in the BatchProcessingQueueHandler<T> class instantiates a BatchProcessingQueueHandler<T> instance.
private readonly IAzureQueue<T> queue;
private TimeSpan interval;
protected BatchProcessingQueueHandler(IAzureQueue<T> queue)
{
this.queue = queue;
this.interval = TimeSpan.FromMilliseconds(200);
}
public static BatchProcessingQueueHandler<T> For(
IAzureQueue<T> queue)
{
if (queue == null)
{
throw new ArgumentNullException("queue");
}
return new BatchProcessingQueueHandler<T>(queue);
}
Next, the worker role invokes the Every method of the BatchProcessingQueueHandler<T> object to specify how frequently the task should be run.
| The current implementation uses a single queue, but you could modify the BatchProcessingQueue-Handler to read from multiple queues instead of only one. According to the benchmarks published at http://azurescope.cloupapp.net, the maximum write throughput for a queue is between 500 and 700 items per second. If the Surveys
application needs to handle more than approximately 2 million survey
responses per hour, the application will hit the threshold for writing
to a single queue. You could change the application to use multiple
queues, perhaps with different queues for each subscriber. |
Next, the worker role invokes the Do method of the BatchProcessingQueueHandler<T> object, passing an IBatch Command object that identifies the command that the “plumbing” code should execute on each message in the queue. The following code example shows how the Do method uses the Task.Factory.StartNew method from the Task Parallel Library (TPL) to run the PreRun, ProcessMessages, and PostRun methods on the queue at the requested interval.
Note:
Use Task.Factory.StarNew in preference to ThreadPool.Queue UserWorkItem.
public virtual void Do(IBatchCommand<T> batchCommand)
{
Task.Factory.StartNew(() =>
{
while (true)
{
this.Cycle(batchCommand);
}
}, TaskCreationOptions.LongRunning);
}
protected void Cycle(IBatchCommand<T> batchCommand)
{
try
{
batchCommand.PreRun();
bool continueProcessing;
do
{
var messages = this.queue.GetMessages(32);
ProcessMessages(this.queue, messages,
batchCommand.Run);
continueProcessing = messages.Count() > 0;
}
while (continueProcessing);
batchCommand.PostRun();
this.Sleep(this.interval);
}
catch (TimeoutException)
{
}
}
The Cycle
method repeatedly pulls up to 32 messages from the queue in a single
transaction for processing until there are no more messages left.
The following code example shows the ProcessMessages method in the GenericQueueHandler class.
protected static void ProcessMessages(IAzureQueue<T> queue,
IEnumerable<T> messages, Action<T> action)
{
...
foreach (var message in messages)
{
var success = false;
try
{
action(message);
success = true;
}
catch (Exception)
{
success = false;
}
finally
{
if (success || message.DequeueCount > 5)
{
queue.DeleteMessage(message);
}
}
}
}
This method uses the action
parameter to invoke the custom command on each message in the queue.
Finally, the method checks for poison messages by looking at the DequeueCount property of the message; if the application has tried more than five times to process the message, the method deletes the message.
Note:
Instead of deleting poison messages, you should send them to a dead message queue for analysis and troubleshooting.
3.3. Testing the Worker Role
The implementation of the
“plumbing” code in the worker role, and the use of Unity, makes it
possible to run unit tests on the worker role components using mock
objects instead of Windows Azure queues and BLOBs. The following code
from the BatchProcessingQueue HandlerFixture class shows two example unit tests.
[TestMethod]
public void ForCreatesHandlerForGivenQueue()
{
var mockQueue = new Mock<IAzureQueue<StubMessage>>();
var queueHandler = BatchProcessingQueueHandler
.For(mockQueue.Object);
Assert.IsInstanceOfType(queueHandler,
typeof(BatchProcessingQueueHandler<StubMessage>));
}
[TestMethod]
public void DoRunsGivenCommandForEachMessage()
{
var message1 = new StubMessage();
var message2 = new StubMessage();
var mockQueue = new Mock<IAzureQueue<StubMessage>>();
mockQueue.Setup(q =>
q.GetMessages(32)).Returns(
() => new[] { message1, message2 });
var command = new Mock<IBatchCommand<StubMessage>>();
var queueHandler =
new BatchProcessingQueueHandlerStub(mockQueue.Object);
queueHandler.Do(command.Object);
command.Verify(c => c.Run(It.IsAny<StubMessage>()),
Times.Exactly(2));
command.Verify(c => c.Run(message1));
command.Verify(c => c.Run(message2));
}
public class StubMessage : AzureQueueMessage
{
}
private class BatchProcessingQueueHandlerStub :
BatchProcessingQueueHandler<StubMessage>
{
public BatchProcessingQueueHandlerStub(
IAzureQueue<StubMessage> queue) : base(queue)
{
}
public override void Do(
IBatchCommand<StubMessage> batchCommand)
{
this.Cycle(batchCommand);
}
}
The ForCreateHandlerForGivenQueue unit test verifies that the static For method instantiates a BatchProcessingQueueHandler correctly by using a mock queue. The DoRunsGivenCommand ForEachMessage unit test verifies that the Do method causes the command to be executed against every message in the queue by using mock queue and command objects.
