1. Mean Time to Failure and Mean Time to Recover
The two most common metrics used to measure fault tolerance and avoidance are the following:
Although a great deal of time
and energy is often spent trying to lower the MTTF, realize that even if
you have a finite failure rate, an MTTR that is zero or near zero might
be indistinguishable from a system that hasn’t failed. Downtime is
generally measured as MTTR divided by MTTF, so increasing the MTTF will
reduce the downtime—but at a significant cost.
Trying to increase the MTTF
beyond a certain point can be prohibitively expensive. A more
cost-effective and realistic strategy, especially in the small business
space where resources are finite and customers are very cost-conscious,
is to spend both time and resources on managing and reducing the MTTR
for your most likely and costly points of failure.
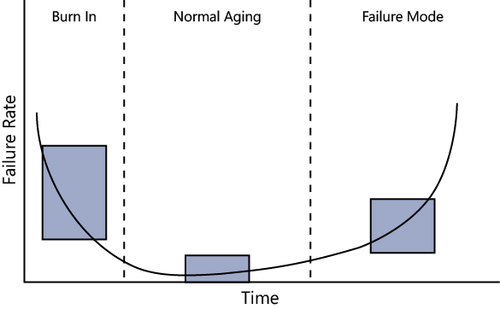
Most modern electronic components have a distinctive “bathtub” curve that represents their failure characteristics, as shown in Figure 1.
During the early life of the component (referred to as the burn-in
phase), it’s more likely to fail. When this initial phase is over, a
component’s overall failure rate remains quite low until it reaches the
end of its useful life, when the failure rate increases again.
The typical commodity hard disk of 15 years ago had an MTTF
on the order of three years. Today, the manufacturer’s published MTTF
for a typical commodity hard disk is more likely to be 35 to 50 years,
with MTTF ratings of server-oriented hard drives hitting 134 years!
At least part of that
difference is a direct result of counting only the portion of the curve
in the normal aging section, while taking externally caused failure out
of the equation. Therefore, a hard disk that fails because of an
improperly filtered power spike doesn’t count against the MTTF of the
disk, nor does a disk that fails in its first week or two. This might be
nice for the disk manufacturer’s statistics, but it doesn’t do much for
the system administrator whose system has crashed because of a disk
failure.
As you can see, it’s important
to look at the total picture and carefully evaluate all the factors and
failure points on your system. Only by looking at the whole system,
including the recovery procedures and methodology, can you build a truly
fault-tolerant environment.
2. Protecting the Power Supply
The single biggest failure
point for any network is its power supply. If you don’t have power, you
can’t run your computers. It seems pretty obvious, and most of us slap
an uninterruptible power supply (UPS) on the order when we’re buying a
new server. However, this barely scratches the surface of what you can
and should do to protect your network from power problems. You need to
protect your network from four basic types of power problems:
Local power supply failure Failure of the internal power supply on a server, router, or other network component
Voltage variations Spikes, surges, sags, and longer-term brownouts
Short-term power outages External power failures lasting from fractions of a second to several minutes
Long-term power outages External power failures lasting from several minutes to several hours or even days
Each type of power
problem poses different risks to your network and requires somewhat
different protection mechanisms. The level of threat that each poses to
your environment varies depending on the area where you are located, the
quality of power available to you, and the potential loss to your
business if your computers are down.
2.1. Local Power Supply Failure
Computer power supplies have
made substantial gains in the last 10 years, but they are still one of
the greatest risk points. All the power conditioning, uninterruptible
power supplies, and external generators in the world won’t help much if
your server’s power supply fails. Most servers these days either come with a redundant power supply or have the option of including one. Take the option! The extra cost associated with adding a redundant power supply to a server or critical piece of network hardware is far less than the cost of downtime if the power supply fails.
We found this out the hard
way recently—our main server turned out to have a run of bad power
supplies. The manufacturer knew about the problem and replaced them
without question. But if it hadn’t been for the second power supply in
it, we’d have been down and out until the replacement got to us. As it
was, they also replaced the second power supply in the server without
waiting for it to fail because it was part of the same batch of bad
power supplies.
If your server, router, or other piece of network hardware doesn’t have the option of a redundant power supply, order a spare power
supply for it when you order the original hardware. Don’t count on the
hardware manufacturer’s “four-hour response time,” especially when you
consider the cost to your business even if they actually repair the
equipment in four hours. If you have a spare power supply in a
well-marked cabinet where you can easily find it, you can quickly and
with minimal disruption replace the failed power supply and return the
equipment to full functionality. Then you can afford to wait patiently for the manufacturer’s service response.
Note:
Most major
manufacturers use proprietary components in their servers. This usually
means that you can’t count on using an off-the-shelf component, such as a
power supply, but must use one specifically designed to fit the
particular brand and model of server you have.
|
Having a good supply of
critical spares is a great idea, but sometimes reality intrudes. Storage
can be the weak link here. Most server rooms are not nearly as spacious
as we would like them to be, and in the SBS world a server room might
be little more than a lockable closet. If that’s the case, make sure the
closet has adequate, filtered ventilation and cooling—servers produce a
significant amount of heat, and a poorly ventilated environment will
greatly shorten the life of your server.
Dust is the enemy of your
server—it will impede cooling and can actually short out electrical
components. Server rooms should not have carpeting. And remove any
printers from the area—printers are dust generators.
All too often, the spare
parts end up jammed into a bin or shoved onto an upper shelf with
inadequate or nonexistent identification. If your network is down and
you need a power supply to get it back up, you don’t want to be pawing through a jumble of spare parts looking for the right power supply.
Make every effort to
develop a single, central, secure location for all spare parts. At least
then you have only a single place to search. Then make sure the
manufacturer’s part number is visible, and clearly label the computer or
computers each part is for. Protect the part from dust and spilled
coffee by keeping it in a sealed plastic storage bag.
We like to tape a list of the
manufacturer’s part numbers, details of the installed hardware, and the
list of spare parts we have right inside the case cover of the server
itself. It’s easy to find and doesn’t end up getting lost. It does you
no good to have a spare power supply if you can’t find it or don’t know you have it. And don’t forget to include the location
of any special tools required. It never ceases to amaze us how many
different and apparently unique screwdriver bits we need to get into our
various computers! We started our toolkit with an inexpensive computer
toolkit, and we add tools to it as needed.
|
Finally, practice! If you’ve never replaced a power
supply before, and you don’t have clear and detailed instructions, it
will take you orders of magnitude longer to replace it when the server
is down and everyone is yelling and the phone keeps ringing. By
practicing the replacement of the power supplies in your critical
hardware, you’ll save time and reduce the stress involved.
Ideally, document the steps you
need to perform, and include well-illustrated and detailed instructions
on how to replace the power supplies of your critical hardware as part
of your disaster recovery standard operating procedures. If you can swap
out a failed power supply in 10 minutes, rather than waiting hours
until an outside technician arrives, you’ve saved more than enough money
to pay for the spare part several times over.
|
Simple Network Management Protocol (SNMP) has been around for a long time, and it provides a standardized way for devices, including computers, to provide feedback about their health.
Many OEM servers come installed with third-party management suites that
can be configured to notify you of significant events—such as power
variations, CPU temperatures, and disk events—that can be a precursor
to hard disk failure. If your server comes with such a tool, by all
means use it.
|
2.2. Voltage Variations
Even in areas with exceptionally clean power
that is always available, the power that is supplied to your network
inevitably fluctuates. Minor, short-term variations merely stress your
electronic components, but major variations can literally fry them. You
should never, ever simply plug a computer into an ordinary wall socket
without providing some sort of protection against voltage
variations. The following sections describe the types of variations and
the best way to protect your equipment against them.
2.2.1. Spikes
Spikes are large but
short-lived increases in voltage. They can occur because of external
factors, such as lightning striking a power line, or because of internal
factors, such as a large motor starting. The most common causes of
severe voltage spikes are external and outside your control. The effects
can be devastating. A nearby lightning strike can easily cause a spike
of 1000 volts or more to be sent into equipment designed to run on 110
to 120 volts. Few, if any, electronic components are designed to
withstand large voltage spikes of several thousand volts, and almost all
will suffer damage if they’re not protected from them.
Protection from spikes comes in many forms, from the $19.95 power strip with built-in surge protection that you can buy at your local
hardware store to complicated arrays of transformers and specialized
sacrificial transistors that are designed to die so that others may
live. Unfortunately, those $19.95 power strips just aren’t good enough. They are better than nothing, but barely. They have a limited ability to withstand really large spikes.
More specialized (and more expensive, of course) surge
protectors that are specifically designed to protect computer networks
are available from various companies. They differ in their ability to
protect against really large spikes and in their cost. There’s a fairly
direct correlation between the cost of these products and their rated
capacity and speed of action within any company’s range of products, but
the cost for a given level of protection can differ significantly from
company to company. As always, if the price sounds too good to be true,
it is.
In general, these surge
protectors are designed to work by sensing a large increase in voltage
and creating an alternate electrical path for that excessive voltage
that doesn’t allow it to get through to your server. In the most severe
spikes, the surge protectors should destroy themselves before allowing
the voltage to get
through to your server. The effectiveness of these stand-alone surge
protectors depends on the speed of their response to a large voltage
increase and the mechanism of failure when their capacity is exceeded.
If the surge protector doesn’t respond quickly enough to a spike, bad
things will happen.
Most UPSs also provide some protection from spikes.
They have built-in surge protectors, plus isolation circuitry that
tends to buffer the effects of spikes. The effectiveness of the spike
protection in a UPS is
not directly related to its cost, however—the overall cost of the UPS
is more a factor of its effectiveness as an alternative power
source. Your responsibility is to read the fine print and understand
the limitations of the surge protection a given UPS offers. Also
remember that just as with simple surge protectors, large voltage spikes
can cause the surge protection to self-destruct rather than allow the
voltage through to your server. That’s the good news; the bad news is
that instead of having to replace just a surge protector, you’re likely
to have to repair or replace the UPS.
Note:
Online or continuous UPSs are
far more effective at protecting downstream electronic equipment than
standard reactive UPSs. Even though an online UPS typically costs 1.5 to
2 times the price of a standard reactive UPS of the same capacity, it’s
money well spent.
Finally, one other spike protection mechanism can be helpful—the constant voltage transformer (CVT).
You’re not likely to see one unless you’re in a large industrial
setting, but they are often considered to be a sufficient replacement
for other forms of surge protection. Unfortunately, they’re not really
optimal for spike protection. They do filter some excess voltage, but a
large spike is likely to find its way through. However, in combination
with either a fully protected UPS or a good stand-alone surge protector,
a CVT can be quite effective. They also provide additional protection
against other forms of voltage variation that surge protectors alone
can’t begin to manage.
2.2.2. Surges
Voltage surges and spikes are
often discussed interchangeably, but we’d like to make a distinction
here. For our purposes, a surge lasts longer than most spikes and isn’t
nearly as large. Most surges last a few hundred milliseconds and are
rarely over 1000 volts. They can be caused by many of the same factors
that cause voltage spikes.
Providing protection
against surges is somewhat easier than protecting against large spikes.
Most of the protection mechanisms just discussed also adequately handle
surges. In addition, most CVTs are sufficient to handle surges and might
even handle them better if the surge is so prolonged that it threatens
to overheat and burn out a simple surge protector.
2.3. Sags
Voltage
sags are short-term reductions in the voltage delivered. They aren’t
complete voltage failures or power outages and are shorter than a
full-scale brownout. Voltage sags can drop the voltage well below 100
volts on a 110- to 120-volt normal line and cause most servers to reboot
if protection isn’t provided.
Stand-alone surge protectors provide no defense against sags. You need a UPS or a very good CVT
to prevent damage from a voltage sag. Severe sags can overcome the
rating of all but the best constant voltage transformers, so you
generally shouldn’t use a CVT as the sole protection against sags. A
UPS, with its battery power supply, is an essential part of your protection from problems caused by voltage sags.
2.3.1. Brownouts
A brownout is a planned,
deliberate reduction in voltage from your electric utility company.
Brownouts most often occur in the heat of the summer and are designed to
protect the utility company from overloading. They are not designed to protect the consumer, however.
In general, a brownout
reduces the available voltage by 5 to 20 percent from the normal value. A
CVT or a UPS provides excellent protection against brownouts, within
limits. Prolonged brownouts might exceed your UPS’s ability to maintain a
charge at the same time that it is providing power at the correct
voltage to your equipment. Monitor the health of your UPS carefully
during a brownout, especially because the risk of a complete power
outage increases if the power company’s voltage reduction strategy
proves insufficient.
The best protection
against extended brownouts is a CVT of sufficient rating to fully
support your critical network devices and servers. If you live in an
area that is subject to brownouts and your budget can afford it, a good
CVT is an excellent investment. This transformer takes the reduced
voltage provided by your power company and increases it to the rated
output voltage. A good constant voltage transformer can handle most
brownouts for an extended time without problems, but you should still
supplement the CVT with a quality UPS and surge protection between the
transformer and the server or network device. This extra protection is
especially important while the power company is attempting to restore
power to full voltage, because during this period you run a higher risk
of experiencing power and voltage fluctuations.
2.4. Short-Term Power Outages
Short-term power
outages last from a few milliseconds to a few minutes. They can be
caused by either internal or external events, but you can rarely plan
for them even if they are internal. A server that is unprotected from a
short-term power outage will, at the very least, reboot or, at the
worst, fail catastrophically.
The best protection against a
short-term power outage is a UPS in combination with high-quality spike
protection. Be aware that many momentary interruptions of power are
accompanied by large spikes when the power is restored. Further, a
series of short-term power outages often occur consecutively, causing
additional stress to electronic components.
2.5. Long-Term Power Outages
Long-term
power outages, lasting from an hour or so to several days, are often
accompanied by other, more serious problems unless your server room is
in a very remote location. Long-term power outages can be caused by
storms, earthquakes, fires, and the incompetence of electric power
utilities, among other things. As such, plans for dealing with long-term
power outages should be part of an overall disaster recovery plan.
Protection against
long-term power outages really becomes a decision about how long you
want or need to function if all power is out. If you need to function
long enough to be able to gracefully shut down your network, a simple
UPS or a collection of them will be sufficient, assuming that you’ve
sized the UPS correctly. However, if you need to be sure that you can
maintain the full functionality of your SBS network during an extended
power outage, you’re going to need a combination of one or more UPSs and
an auxiliary generator. But before you start spending money on generators and failover switches, evaluate the overall infrastructure supplying your power. If you’re dependent on Internet
connectivity to do business, it does you no good to be up and running
in the middle of a two-day power outage if your Internet is also down.
We’ve been involved with more
than one operation that depended on—and implemented—auxiliary generators
to support their operations during extended power outages. Included in
this group is our office, thanks to the regular (and often extended)
outages that the weather here causes. The results of having an auxiliary
generator have been rather mixed, however. The one lesson we’ve learned
the hard way is that simply buying and installing an auxiliary
generator will do little, if anything, to keep you up and running when
the power goes out. Generators are complex mechanical and electrical
machines that require specialized expertise and consistent,
conscientious processes and maintenance.
If your situation requires an auxiliary generator to supplement your UPSs, you should carefully plan your power
strategy to ensure that your generator has sufficient clean load
capacity to provide the power your network will require in the event of a
long-term power outage. Portable industrial generators
often do not provide clean, sine wave power and are not appropriate for
computer networks. Verify with the manufacturer that the generator you
are considering is rated for electronics and computers. Generators
that produce sine wave output and are rated for electronics are
inevitably more expensive than the generators intended for most
construction jobs. We had to spend nearly twice as much within the same
brand and power rating to get a suitable generator for our office. But
it has more than paid for itself since!
Make sure you have a sufficient fuel source to power the generator for as long as you reasonably expect to have power out.
Warning:
IMPORTANT
For all but the smallest businesses, a generator powered by piped-in
natural gas is a far safer and more appropriate solution than a
gasoline-powered generator with all the potential issues that storage of
gasoline can entail.
To install and set up the
generator, you’ll need the expertise of a licensed electrician who has
experience installing and configuring generator failover switches. Test
your solution to make sure you didn’t miss anything! Further, you should
regularly test the effectiveness of your disaster recovery plans and
make sure that all key personnel know how to start the auxiliary
generator manually in the event it doesn’t start automatically.
Finally, you should have a regular preventive maintenance (PM)
program in place that services and tests the generator and ensures that
it is ready and functioning when you need it. This PM program should
include both static tests and full load tests on a regular basis, and it
should also call for periodically replacing the fuel to the generator
if it’s gasoline powered. One of the best ways to do all of this is to
plan and execute a “disaster day” for testing your entire disaster
recovery plan in as close to real-world conditions as possible,
including running your entire operation from the backup generator.
