For those new to SharePoint, or even knowledge
management systems, the terms taxonomy and ontology are probably tied to
experiences in a biology class. Taxonomy is the practice and science of
classification. Originally used to classify organisms, the use of
taxonomies has spread to classifying things and concepts by underlying
principles. Taxonomies can be seen in the organization of companies with
an organizational chart. Organizational charts classify people by who
they work with, who they work for, and who works for them. Taxonomies
can be found in company product catalogs. A company may sell shoes, but
it may classify them into groups such as size, gender, season, or color.
Each of these properties is considered to be a node, and all of the
shoes are cataloged into one or more nodes. A more expanded taxonomy may
contain several subsets for each node. For example, to create more
accurate groupings, shoes may first be grouped by gender, and then by
season. Taxonomies allow for information to be organized into a
hierarchical structure so that it is easier to manage and understand.
While similar in
concept, ontologies are a bit broader than taxonomies, as they apply a
larger and more complex web of relationships between information.
Ontology is a formal connection of knowledge and connecting concepts
within a domain. Instead of simply grouping information together into
silos, ontologies define relationships between individual items.
Ontologies are the foundation of enterprise architecture and, as a
result, vital to the ability to catalog and understand information
within SharePoint.
Although taxonomies and
ontologies are not the only key to search, they are a significant
building block for effective navigation. Without relationships between
documents, teams, people, and sites, SharePoint 2010 would be a vast
blob of content without any framework. Searching for managed properties
would work, but SharePoint wouldn't be able to understand the difference
between the property that defines a file as a PDF and the one that
defines its author. Users could not scope searches to specific sites
because sites are taxonomic silos of information. Searches could be
executed for people, but users could not see organization charts or the
documents they created.
SharePoint 2010 makes
significant improvements over its predecessor in taxonomy management.
MOSS 2007 did not provide taxonomy management tools, and, as a result,
managing schemas and classifying content against them was difficult to
impossible. Taxonomies could be designed only with very limited nodes
and subsets. These setbacks resulted in potentially oversimplified
taxonomic structure. SharePoint 2010, by contrast, provides a powerful
toolset for creating and managing taxonomic structures. This helps
organizations leverage SharePoint for the backbone of their cataloging
and knowledge management needs.
1. Automated Classification
Building taxonomies is only
half of the solution. While SharePoint 2010 allows for the taxonomic
structure to be designed, it falls short of automatic mechanisms for
classifying items into the taxonomy. Farm structures can be built, but
items cannot easily be organized into the structure. Features are in
place for users and administrators to manually assign documents into
taxonomic structures and tag them with metadata, but this process can be
cumbersome and inaccurate. Unfortunately, people are inefficient and
inaccurate at tagging items. Too often, general terms such as meeting notes, sales report, policies, and manual
are tagged to large amounts of unrelated documents by users, which
dilutes the specifics of the item. It is extremely common to find the
name of the company that owns the portal on documents. If an employee of
the company American Ninjas Associated searches for the term Ninja,
they are probably going to return a massive amount of irrelevant
results because the company name was tagged as metadata. In fact, the
most relevant metadata in most environments is the properties SharePoint
automatically creates such as author, file type, and upload date.
Because the search
engine heavily relies on metadata for refinements and relevancy, the
efficiency of search is directly affected by the quality of metadata. If
items are incorrectly tagged or stored in the wrong location, they
cannot be found in search. Organizations may seek to improve search
relevancy by creating more thorough document upload processes that
request more specific information and providing better training on what
to include in document tags. These options still rely on the inaccuracy
of people and their opinions instead of strictly designed rules and
ontology. Although SharePoint 2010 cannot automatically add most
metadata to items, there are several Microsoft partners with
commercially available solutions to assist. There are several
well-established solutions to help auto-classify SharePoint data, such
as Smartlogic's Semaphore, MetaVis's CLASSIFIER, and Concept Searching's
conceptClassifier.
2. conceptClassifier
Concept Searching's
conceptClassifier can automatically classify content in SharePoint 2010
against any available taxonomy. It integrates with the SharePoint 2010
Term Store and can process any content that is indexed by SharePoint. It
then applies conceptual metadata to content and auto-classifies it to
the Term Store metadata model. The metadata it produces is then stored
as SharePoint properties. Authorized users can view, manipulate, and add
additional tags as necessary using a form that integrates with the
standard SharePoint 2010 Web Parts. This greatly reduces the time
resources and inaccuracies that come with manual tagging.
The Taxonomy Manager component
provides the ability to get instant feedback and automatic suggestions
for terms from the client's own content to automate the term creation
and building the hierarchical model. Management, testing, and validation
are done in conceptClassifier, and terms are written back into the Term
Store in real time.
Figure 1
shows the conceptClassifier Taxonomy Manager component interface. In
this image, the Avionics and Sensors node is highlighted on the left
panel. This shows the taxonomy hierarchy where nodes can be added,
moved, or deleted. On the right panel are the clues (terms) that have
been automatically or manually generated from the organizational
content.
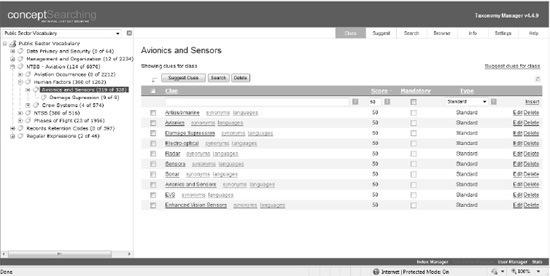
The user can add terms
manually, provide a score, make the clue mandatory, and select the type.
Clue types supported include the following:
STANDARD: Single words and phrases
CASE-SENSITIVE
DOCUMENT METADATA: Partial matching on metadata values
PHONETIC MATCHING: Ability to locate topics regardless of spelling variations
REGULAR EXPRESSION: Any regular expression can be used, such as part number, credit card numbers.
CLASS ID: Can be classified only if parent or grandparent is classified
LANGUAGE FILTERS: Individual topics limit individual clues to specific languages.
Document movement feedback is
also available to tune the taxonomy. This provides the mechanism to
evaluate the changes on the taxonomy in real time without the need to
reclassify the content. The feature will display the new classifications
based on changes made to the scores. Indicators show how the score
changes will impact the classification.
Indicators include the following:
Document remains classified with a higher score
Document remains classified but with a lower score
Document remains unclassified and the score does not change
Document will now become classified
Document either stays or becomes unclassified
conceptClassifier can
greatly increase document classification accuracy by leveraging
multi-word concepts in its matching algorithms. Unlike SharePoint 2010's
native tagging mechanism, which forces users to enter one potentially
ambiguous word to define a concept, Concept Searching's tool can apply
compound term processing to classify unstructured documents against
taxonomies.
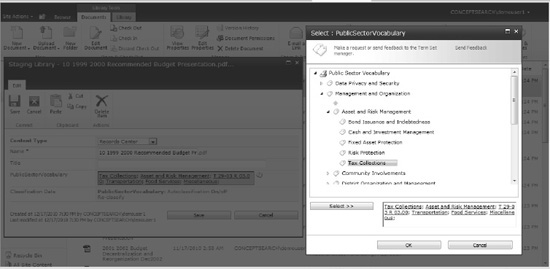
Figure 2
shows conceptClassifier's Term Store integration. All changes made in
conceptClassifier or in the Term Store are immediately available,
without the need to import or export. Classification rules for Avionics
and Sensors are illustrated, showing the same node as the previous
screenshot but from within the Term Store. The conceptClassifier
taxonomy component provides the ability to manage, validate, and test
the taxonomy(s). It also ensures that content will be correctly
classified to improve findability in search, records management, and
compliance.
In addition to
automatic concept extraction and classification, conceptClassifier also
provides more advanced classification rules. These allow the tool to
recognize the difference between single word and multi-word concept or
phrases. It can understand existing metadata such as file type and
storage location. The tool understands spelling variations based on
phonetics much like the phonetic search in people on SharePoint 2010. It
can also understand patterns such as part number and addresses. Finally
it can recognize hierarchical relationships between topics and
automatically detects the dominant language in a document.
Beyond the need for
well-designed taxonomy and metadata to drive the ability to find
information, it is also necessary to control sensitive information. For
SharePoint deployments with organizationally defined sensitive
information such as For Official Use Only (FOUO), Personally Identifiable Information (PII), and Personal Healthcare Information
(PHI), accurate document classification means more than efficiency. For
organizations with this type of information, poor classification leaves
portals open to security breaches. Concept Searching's
conceptClassifier can be used to automatically detect sensitive
information or potential security breaches. It can do this by detecting
patterns and cross-referencing them to associated vocabulary. Documents
that the tool finds to meet certain suspect parameters can be tagged
appropriately and locked down if necessary. This feature can also
automatically change the file's content type so that workflows and
permissions management can be automatically initiated to protect
potentially sensitive documents.
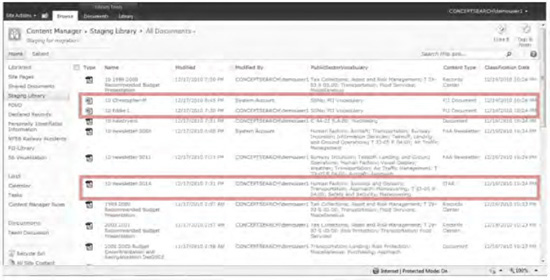
In Figure 3,
content has been automatically classified using one or more defined
taxonomies. Based on the conceptual metadata and organizationally
defined descriptors, documents are classified and, where appropriate,
the content type has been automatically changed. The second and third
document contained social security numbers and Personally Identifiable
Information (PII); therefore the content type was changed to PII
Document and the two highlighted documents will be routed to a secure
repository where Windows Rights Management can be applied.
The time it takes to install and
set up contentClassifier is relatively limited considering the massive
effect it can have on an environment. The product is downloadable in 30
minutes, contains a menu-driven setup, and from an administration
perspective is easy to use. The taxonomy capabilities are also very easy
to use, especially considering the amount of time it takes to create
them in out-of-the-box SharePoint 2010. There are, however, no solutions
that can completely operate autonomously without some administrative
attention. Taxonomies do need to be managed and maintained. The tool was
designed to provide this capability through the interactive features
designed for subject matter experts (business users) as opposed to
highly technical taxonomy specialists. SharePoint environments never
remain static, so time is required for ongoing management of the
taxonomy.
While these are not all of
the features of Concept Searching's conceptClassifier, this does provide
an initial idea of the available functionality in this and other
classification solutions. While auto-classification is not the only way
to improve information within taxonomies and ontologies, it is most
certainly a great place to start.
3. Choosing the Best Option
In addition to their
auto-classification solutions, both Smartlogic and Concept Searching
vendors offer additional tools for managing taxonomies and ontologies. A
comparison of the auto-classification solution features for these two
vendors is shown in Table 1.
Table 1. Auto-Classification Products
| Feature | SharePoint 2010 | Smartlogic Semaphore | Concept Searching |
|---|
| Vocabulary support | | | |
| Hierarchical Term Store (taxonomy) | X | X | X |
| Native read/write integration without the need to import/export terms | | X | X |
| Synonyms | X | X | X |
| Multi-language | X | X | X |
| List management (folksonomy and authority) | X | X | X |
| Relationship definition (ontology) | | X | X |
| Model support | | | |
| Poly-hierarchical taxonomy structure | Partial | X | X |
| User-definable model structure | | X | X |
| Expandable term information | | X | X |
| Text mining to identify candidate terms | | X | X |
| Ontology collaboration and review tools | | X | X |
| Extensive reporting management and control | | X | |
| Open, ability to layer standard Microsoft and other reporting tools | | X | X |
| Term approval workflow and audit log | | X | X |
| Term Store management with instant feedback and term suggestions | | X | X |
| Easy rollback | | | X |
| Import, combine, organize, and harmonize models | | X | X |
| Enterprise model management | | X | X |
| Distributed taxonomy management | | X | X |
| Controlled vocabularies from organization's own content | | X | X |
| Automatic content type updating based on organizationally defined vocabulary and descriptions | | X | X |
| Automatic declaration of documents of record and routing to records center | | X | X |
| Automatic identification and lockdown of data privacy assets | | | X |
| Navigation support | | | |
| Configurable and multiple best bets | One only | X | X |
| Concept mapping | | X | X |
| Taxonomy browse-as-you-type | | X | |
| Ontology and knowledge map browsing | | X | X |
| Dynamic classification summarization | | X | |
| Taxonomy navigation | | X | X |
| A–Z listing | | X | |
| Classification & text mining support | | | |
| Manual tagging | X | X | X |
| Assisted classification | | X | X |
| Automatic rules-based classification | | X | X |
| Incremental library classification | | X | X |
| Classification hierarchy support | | X | X |
| Classification strategy support | | X | |
| Compound term processing | | | X |
| Classification from SharePoint to other repositories | | | X |
| Classification of non-SharePoint content | | X | X |
| Content migration | | X | X |
| Semantic processing for driving SharePoint workflow | | X | X |
| Classifies all SharePoint content (libraries, blogs, wikis, pages, discussion threads) | | X | X |
| Entity extraction | | X | X |
