What’s New in SQL Server Clustering
Much of what’s new for MSCS and
SQL Server Clustering has to do with the expanded number of nodes that
can be managed together and several ease-of-use enhancements in MSCS,
including the following:
Setup changes for SQL Server failover clustering—
One option forces you to run the Setup program on each node of the
failover cluster. To add a node to an existing SQL Server failover
cluster, you must run SQL Server Setup on the node that is to be added
to the SQL Server failover cluster instance. Another option creates an
enterprise push to nodes from the active node.
Cluster nodes residing on different subnets—
With Windows 2008, cluster nodes can now reside on different network
subnets across network routers. You no longer have to stretch virtual
local area networks to connect geographically separated cluster nodes.
This opens the door to clustered disaster recovery options.
Instances per cluster— SQL Server 2008 Enterprise Edition supports up to 25 SQL Server instances per cluster (up to 50 for a nonclustered server).
More cluster-aware applications—
Many of the MS SQL Server 2008 products are cluster aware, such as
Analysis Services, Full Text Search, Integration Services, Reporting
Services, FILESTREAM, and others, making these applications more highly
available and resilient.
Isolation of the quorum disk in MSCS— A shared disk partition that is not on the same physical drive/LUN as the quorum drive must be available in an attempt to reduce failure dependencies.
Number of nodes in a cluster—
With Windows 2003 Enterprise Edition (or Datacenter), you can now
create up to 8 nodes in a single cluster, and with Windows 2008
Enterprise Edition (or Datacenter), you can create up to 16 nodes.
These new features and
enhancements combine to make setting up SQL Server Clustering an easy
high-availability proposition. They take much of the implementation risk
out of the equation and make this type of installation available to a
broader installation base.
How Microsoft SQL Server Clustering Works
Put simply, SQL Server 2008
allows failover and failback to or from another node in a cluster. This
is an immensely powerful tool for achieving higher availability
virtually transparently. There are two approaches to implementing SQL
Server Clustering: active/passive or active/active modes.
In
an active/passive configuration, an instance of SQL Server actively
services database requests from one of the nodes in a SQL Server cluster
(that is, the active node). Another node is idle until, for whatever
reason, a failover occurs (to the passive node). With a failover
situation, the secondary node (the passive node) takes over all SQL
Server resources (for example, databases and the Microsoft Distributed
Transaction Coordinator [MSDTC]) without the end user ever knowing that a
failover has occurred. The end user might experience a brief
transactional interruption because SQL Server Failover Clustering cannot
take over in-flight transactions. However, the end user still just
looks at a single (virtual) SQL Server and truly doesn’t care which node
is fulfilling requests.
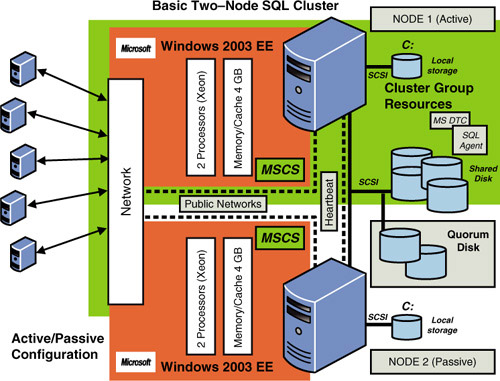
Figure 1
shows a typical two-node SQL Server Clustering configuration using
active/passive mode, in which Node 2 is idle (that is, passive).
In an active/active
configuration, SQL Server runs multiple servers simultaneously with
different databases. This gives organizations with more constrained
hardware requirements a chance to use a clustering configuration that
can fail over to or from any node, without having to set aside idle
hardware.
As previously mentioned, SQL
Server Clustering is actually created within (on top of) MSCS. MSCS, not
SQL Server, is capable of detecting hardware or software failures and
automatically shifting control of the managed resources to a healthy
node. SQL Server 2008 implements failover clustering based on the
clustering features of the Microsoft Clustering Service. In other words,
SQL Server is a fully cluster-aware application and becomes
a set of resources managed by MSCS. The failover cluster shares a
common set of cluster resources (or cluster groups), such as clustered
(that is, shared) disk drives.
Note
You can install SQL Server
on as many servers as you want; the number is limited only by the
operating system license and SQL Server edition you have purchased.
However, MSCS (for Windows 2008) can manage only up to 16 instances of
Microsoft SQL Server Standard Edition at a time and up to 25 instances
of Microsoft SQL Server Enterprise Edition at a time.
Understanding MSCS
A server cluster
is a group of two or more physically separate servers running MSCS and
working collectively as a single system. The server cluster, in turn,
provides high availability, scalability, and manageability for resources
and applications. In other words, a group of servers is physically
connected via communication hardware (network), shares storage (via SCSI
or Fibre Channel connectors), and uses MSCS software to tie them all
together into managed resources.
Server clusters can
preserve client access to applications and resources during failures and
planned outages. If one of the servers in a cluster is unavailable due
to failure or maintenance, resources and applications move to another
available cluster node.
Note
You cannot do clustering
with Windows 2000 Professional or older server versions. Clustering is
available only on servers running Windows 2000 Advanced Server (which
supports two-node clusters), Windows 2000 Datacenter Server (which
supports up to four-node clusters), Windows 2003 Enterprise Edition and
Datacenter Server, and Windows 2008 Enterprise Edition and Datacenter
Server.
Clusters use an algorithm
to detect a failure, and they use failover policies to determine how to
handle the work from a failed server. These policies also specify how a
server is to be restored to the cluster when it becomes available again.
Although
clustering doesn’t guarantee continuous operation, it does provide
availability sufficient for most mission-critical applications and is
the building block of numerous high-availability solutions. MSCS can
monitor applications and resources, automatically recognizing and
recovering from many failure conditions. This capability provides great
flexibility in managing the workload within a cluster, and it improves
the overall availability of the system. Technologies that are “cluster
aware”—such as SQL Server, Microsoft Message Queuing (MSMQ), Microsoft
Distributed Transaction Coordinator (MSDTC), and file shares—have
already been programmed to work within (under the control of) MSCS.
Tip
In previous versions of MSCS, the COMCLUST.EXE
utility had to be run on each node to cluster the MSDTC. It is now
possible to configure MSDTC as a resource type, assign it to a resource
group, and then have it automatically configured on all cluster nodes.
MSCS is relatively
sensitive to the hardware and network equipment you put in place. For
this reason, it is imperative that you verify your own hardware’s
compatibility before you go any further in deploying MSCS (check the hardware compatibility list at http://msdn.microsoft.com/en-us/library/ms189910.aspx). In addition, SQL Server failover cluster instances are not supported where the cluster nodes are also domain controllers.
Let’s look a little closer at a two-node active/passive cluster configuration. As you can see in Figure 2, the heartbeat (named ClusterInternal
in this figure) is a private network set up between the nodes of the
cluster that checks whether a server is up and running (“is alive”).
This occurs at regular intervals, known as time slices.
If the heartbeat is not functioning, a failover is initiated, and
another node in the cluster takes over for the failed node. In addition
to the heartbeat private network, at least one public network (named ClusterPublic
in this figure) must be enabled so that external connections can be
made to the cluster. Each physical server (node) uses separate network
adapters for each type of communication (public and internal heartbeat).
The shared disk
array is a collection of physical disks (SCSI RAID or Fibre
Channel–connected disks) that the cluster accesses and controls as
resources. MSCS supports shared nothing
disk arrays, in which only one node can own a given resource at any
given moment. All other nodes are denied access until they own the
resource. This protects the data from being overwritten when two
computers have access to the same drives concurrently.
The quorum drive
is a logical drive designated on the shared disk array for MSCS. This
continuously updated drive contains information about the state of the
cluster. If this drive becomes corrupt or damaged, the cluster
installation also becomes corrupt or damaged.
Note
In general (and as
part of a high-availability disk configuration), the quorum drive should
be isolated to a drive all by itself and be mirrored to guarantee that
it is available to the cluster at all times. Without it, the cluster
doesn’t come up at all, and you cannot access your SQL databases.
The MSCS architecture
requires there to be a single quorum resource in the cluster that is
used as the tie-breaker to avoid split-brain scenarios. A split-brain scenario
happens when all the network communication links between two or more
cluster nodes fail. In these cases, the cluster may be split into two or
more partitions that cannot communicate with each other. MSCS
guarantees that even in these cases, a resource is brought online on
only one node. If the different partitions of the cluster each brought a
given resource online, this would violate what a cluster guarantees and
potentially cause data corruption. When the cluster is partitioned, the
quorum resource is used as an arbiter. The partition that owns the
quorum resource is allowed to continue. The other partitions of the
cluster are said to have “lost quorum,” and MSCS and any resources
hosted on nodes that are not part of the partition that has quorum are
terminated.
The quorum resource is a
storage-class resource and, in addition to being the arbiter in a
split-brain scenario, is used to store the definitive version of the
cluster configuration. To ensure that the cluster always has an
up-to-date copy of the latest configuration information, you should
deploy the quorum resource on a highly available disk configuration
(using mirroring, triple-mirroring, or RAID 10, at the very least).
Starting with Windows 2003, a more durable approach of managing the quorum disks with clustering was created, called majority node set.
It all but eliminates the single-point-of-failure weakness in the
traditional quorum disk configuration that existed with Windows 2000
servers. However, even this approach isn’t always the best option for
many clustered scenarios.
The notion of quorum as a
single shared disk resource means that the storage subsystem has to
interact with the cluster infrastructure to provide the illusion of a
single storage device with very strict semantics. Although the quorum
disk itself can be made highly available via RAID or mirroring, the
controller port may be a single point of failure. In addition, if an
application inadvertently corrupts the quorum disk or an operator takes
down the quorum disk, the cluster becomes unavailable.
This
situation can be resolved by using a majority node set option as a
single quorum resource from an MSCS perspective. In this set, the
cluster log and configuration information are stored on multiple disks
across the cluster. A new majority node set resource ensures that the
cluster configuration data stored on the majority node set is kept
consistent across the different disks.
The disks that make up the
majority node set could, in principle, be local disks physically
attached to the nodes themselves or disks on a shared storage fabric
(that is, a collection of centralized shared storage area network [SAN]
devices connected over a switched-fabric or Fibre Channel–arbitrated
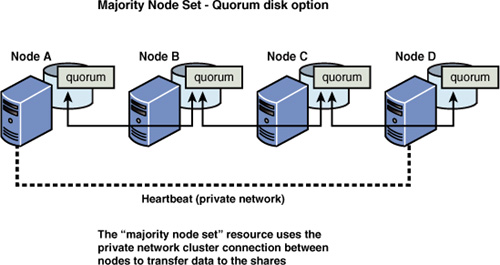
loop SAN). In the majority node set implementation that is provided as
part of MSCS in Windows Server 2003 and 2008, every node in the cluster
uses a directory on its own local system disk to store the quorum data,
as shown in Figure 3.
If the configuration of
the cluster changes, that change is reflected across the different
disks. The change is considered to have been committed (that is, made
persistent) only if that change is made to a majority of the nodes (that
is, [Number of nodes configured in the cluster]/2) + 1). In this way, a
majority of the nodes have an up-to-date copy of the data. MSCS itself
starts up only if a majority of the nodes currently configured as part
of the cluster are up and running as part of MSCS.
If there are fewer nodes, the cluster is said not
to have quorum, and therefore MSCS waits (trying to restart) until more
nodes try to join. Only when a majority (or quorum) of nodes are
available does MSCS start up and bring the resources online. This way,
because the up-to-date configuration is written to a majority of the
nodes, regardless of node failures, the cluster always guarantees that
it starts up with the most up-to-date configuration.
With Windows 2008, a few
more quorum drive configurations are possible that address various
voting strategies and also support geographically separated cluster
nodes.
In Windows Server 2008 failover clustering, you have four choices on how to implement the quorum:
One option is to use
Node majority; a vote is given to each node of the cluster, and the
cluster continues to run as long as a majority of nodes are up and
running.
A second
option is to use both the nodes and the standard quorum disk, a common
option for two-node clusters. Each node gets a vote, and the quorum, now
called a witness disk,
also gets a vote. As long as two of the three are running, the cluster
continues. The cluster can actually lose the witness disk and still run.
A
third option is to use the classic/legacy model and assign a vote to
the witness disk only. This type of quorum equates to the well-known,
tried-and-true model that has been used for years.
A fourth option is, of course, to use the majority node set (MNS) model with a file share witness.
We describe only the standard majority node set approach here.
Tip
A quick check to see
whether your hardware (server, controllers, and storage devices) is
listed on Microsoft’s Hardware Compatibility List will save you
headaches later. See the hardware pre-installation checklist at http://msdn.microsoft.com/en-us/library/ms189910.aspx.
