Creating indexes within SQL Server is an art, not a
science. The tips, tricks and recommendations for creating indexes are
useful starting points. If you think you can just follow that
information, create the indexes in your environment, and not have to
worry about indexes again, then you are mistaken. The more complex the
system, the harder it is to apply best practices without your personal
modification. As the database administrator, your role is to add your
own flavor, the artistic piece to your database system to make sure
everything runs as smoothly as possible. We would love to provide you
with some gold nuggets, some guaranteed rules that will work in every
environment, but the truth is that everything depends on the environment
you are supporting. However, we will provide you with some processes
that we do before and after creating indexes to ensure that they are
helping our environment and not hurting it.
1. Performance of Insert, Update, and Delete Statements
Keep an eye on the performance
of insert, update, and delete statements before and after adding indexes
to a table. To that end, be sure to gather statistical data about a
table before adding an index to it. Following is some of the information
that we gather before adding indexes:
The row count and size of the table in bytes:
The number of rows and the table's projected growth in terms of rows
and size helps you determine the amount of time that you spend analyzing
the creation of the index. If the table is relatively small, and will
remain small, but there is just a slow application query running against
it, then you should quickly add an index and move on. If the poorly
performing query is on a large table with a large number of records,
then you should spend more time in the analysis phase.
The current list of indexes that exist on the table:
The indexes that exist on the table are important for a couple of
different reasons. You want to make sure you know what indexes exists so
you don't duplicate an index. Reviewing the current indexes on a table
may also lead you down the path that determines that you don't need to
create an additional index. You may be able to add an additional clause
in your query to take advantage of an existing index or just include a
column to an existing index.
The average response times of frequent queries against the table:
The response times of the queries that are frequently executed against
the object in question are important. With them, you can determine what
the performance of those queries is after the index addition. The last
thing you want is to speed up one query and dramatically slow down the
other queries.
The frequency and type of access to the table:
For example, is the table used for a lot of reads, or does it
experience heavy write volumes? Understanding the type of access against
the table will ultimately help drive your indexing strategy. If the
table is heavily used for reads and very little for writes, then you can
cover more queries and over index because of the little cost of writes.
If the table is heavily used for writes or both reads and writes, then
you have to consider the cost of the writes and be careful when covering
your queries.
The projected growth rate of the table:
The projected growth rate just helps you plan your indexing strategy
better. Just because a table is small today, doesn't mean it will be
small three, six, or 12 months from now. Make sure the index strategy
that you deploy considers those facts.
Determining the speed of the
writes on a table is essential prior to index creation. In SQL Server
2008, there are several methods for capturing this information. Those
who control data access via stored procedures have it easy. You can
query the system catalog for stored procedures that reference the table
in question. Then you can capture the statistics on those stored
procedures before and after you have created an index on the table and
compare the results.
In order to gather the stats
on your procedures or capture the queries executed against the objects,
you can utilize SQL Server Profiler for access to that table, or you can
query SYS.DM_EXEC_QUERY_STATS Dynamic
Management View (DMV) and search for the queries that access those
tables. Once you find the queries in the DMV, you can use the execution
count along with total_elapsed_time and a series of other columns to
quickly compute the average runtime of queries against the table. It
doesn't matter if you use SYS.DM_EXEC_QUERY_STATS
or the Profiler—you should be able capture some statistics to use
before and after the index creation on the table. Armed with
information, go ahead and create the index that you plan to create,
preferably in a test environment. For those who have good QA
environments with load testing tools, then your environment may be a
good place to verify that the index creation will not negatively affect
the application. Set up your load testing tool to simulate a series of
application functions, including the one that you plan on fixing with
the addition of the new index. Hopefully, your tool will enable you to
see the response times of all the queries giving you a good baseline.
After you apply the index, re-run the test and compare your results. If
the difference in response times is acceptable, then apply the index to
your production environment and monitor your system. Monitor the
averages of your queries to ensure their durations are acceptable to the
application users. Monitor your indexes for as long as you need to make
sure the performance is what you expected.
NOTE
One other useful DMV is SYS.DM_DB_INDEX_USAGE_STATS.
This view allows you to see how often a newly created index is actually
used. We cover useful dynamic management views in the following
section.
2. Useful Dynamic Management Views
When determining the
usefulness of your indexes, identifying statistics on the queries that
execute against objects, and validating some of the suggestions for
index creations, we frequently use DMVs. The DMVs in question are SYS.DM_EXEC_QUERY_STATS, SYS.DM_DB_INDEX_USAGE_STATS, and the series of DMVs associated with the missing index feature in SQL Server 2008.
2.1. SYS.DM_EXEC_QUERY_STATS
The SYS.DM_EXEC_QUERY_STATS
view captures the queries executed against SQL Server. The view gives
information about CPU usage, the physical reads and writes, the
execution times in terms of how long a query runs, the number of times
it runs, and much more. See Figure 1 for some sample output from querying SYS.DM_EXEC_QUERY_STATS.
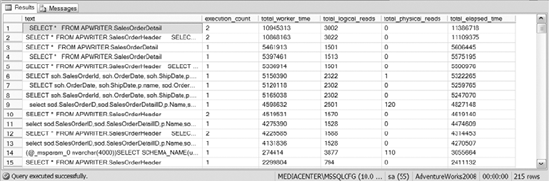
One of the most useful aspects of SYS.DM_EXEC_QUERY_STATS
is that it provides you with the statistical information needed to
determine whether write queries are performing in an acceptable time
frame before and after index creation. Spend some time with this view to
make sure you completely understand its usefulness.
2.2. SYS.DM_DB_INDEX_USAGE_STATS
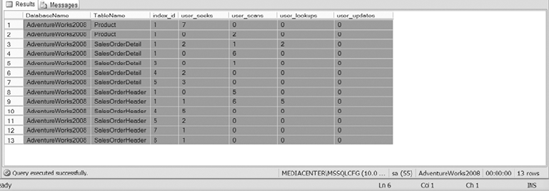
SYS.DM_DB_INDEX_USAGE_STATS
is extremely powerful when it comes to determining the usage of the
indexes that exist on a table. The view provides the number of index
scans, index seeks, lookups, and writes for each of the indexes that are
queried in your system.
Using SYS.DM_DB_INDEX_USAGE_STATS,
you can determine whether the indexes on a table are heavy on reads,
heavy on writes, or both. The view will also show you how an index is
performing right after creation. It is rewarding to create a new index,
and then watch the number of seeks on that index skyrocket. That leaves
you feeling like you are doing your job. See Figure 2 for sample output from querying this very useful view.
2.3. Missing Index Dynamic Management Views
In SQL Server 2008, the
missing index feature identifies opportunities for indexes to be created
on your system. The query optimizer determines that an index would be
utilized if an index that met certain criteria existed. The missing
index views provide the recommended index key, include columns, and some
usage statistics that indicate the index should be created.
Hopefully, you can see the
performance implications of using the missing index DMVs, but for this
section we would like to discuss another purpose. You can use the
missing index views to help validate if the system agrees with an index
that you want to create on your database. Granted, what the system
thinks and what you think will be different from time to time, but there
should be some similarities as well. Don't go out and create every
index suggested by the missing index views. Use the missing index views
as a method by which you can validate your index creation ideas against
what the system thinks prior to creation.
Using the SYS.DM_DB_MISSING_INDEX_DETAILS
DMV, you can query the view to see all of the identified missing
indexes for the instance or for a particular object. When you are
evaluating the index that you want to create, take a quick peek at the
results of the DMV to see if the system has identified that index as
well. The following query retrieves the table name and columns that the
system has identified as useful for queries.
SELECT OBJECT_NAME(object_id,database_id) TableName,
equality_columns,inequality_columns,included_columns
FROM SYS.DM_DB_MISSING_INDEX_DETAILS
Figure 3
shows the sample output of the preceding query. The equality_columns
are column names that are used in queries with an equals sign, like title ='Pro SQL Server Administration'. The inequality_columns are column names that are utilized in queries with an inequality, like date < '2009-01-01'. The included_columns are columns that should be included in the index.

