Data Storage in SQL Server
A database is a storage structure for database objects. It is made up of at least two files. One file, referred to as a data file, stores the database objects, such as tables and indexes. The second file, referred to as the transaction log file, records changes to the data. A data file or log file can belong to only one database.
SQL Server stores data on the data file in 8KB blocks, known as pages. A page
is the smallest unit of input/output (I/O) that SQL Server uses to
transfer data to and from disk. An 8KB page is equal to 1024 bytes × 8,
or 8192 bytes. There is some overhead associated with each data page, so
the maximum number of bytes of data that can be stored on a page is
8060 bytes. The overhead on a data page includes a 96-byte page header
that contains system information about the page. This system information
includes the page number, page type, and amount of free space on the
page.
Generally, a row of data in
a SQL Server database is limited to the 8060-byte maximum. With SQL
Server 2008, there are some exceptions to this 8060-byte limit if the
table contains columns that have the data types text/image, varchar, nvarchar, varbinary, or sql variant.
With these data types, SQL Server can store the data in a separate data
structure when the size of the row exceeds the 8060-byte limit. When
the 8060-byte limit is exceeded, SQL Server stores a pointer to the
separate data structure so that the information in these columns can be
accessed.
In an effort to reduce
internal operations and increase I/O efficiency, SQL Server, when
allocating space to a table or an index, allocates space in extents. An extent
is eight contiguous pages, or 64KB of storage. There are actually two
types of extents. Every table or index is initially allocated space in a
mixed extent.
As the name implies, mixed extents store pages from more than one
object. When an index or a table is first created, it is assigned an
index allocation map (IAM), which is used to track space usage for the
object, and at least one data page. The IAM and data page are assigned
to a mixed extent in an effort to save space
because dedicating an extent to a table with a few small rows would be
wasteful. Up to eight initial pages are assigned this way. When an
object requires more than eight pages of storage, all further space is
allocated from uniform extents. A uniform extent
stores pages for only a single index or table. This allows SQL Server
to optimize read and write operations and reduce fragmentation because
the data is stored in units of 64KB (that is, eight pages) as opposed to
individual 8KB pages being scattered throughout the data file.
Database Files
SQL Server maps a database
over a set of operating system files visible to the SQL Server machine.
Microsoft recommends that the files be located on a storage area network
(SAN), on an iSCSI-based network, or on a locally attached disk. These
three storage options provide the best performance and reliability for a
SQL Server database. You have an option of storing database files on a
network, but this option is turned off by default. You can use the trace
flag 1807 to enable network-based database files, but it is generally
not recommended that you do so.
Each
database can contain a maximum of 32,767 files. Each database file
serves a different purpose for the database engine. These files have a
standard layout that allows SQL Server to organize and read the data
within the files. SQL Server needs to keep track of the allocated space
in each data file; it does so by allocating special pages in the first
extent of each file. Because the data stored on these pages is dense and
the files are accessed often, they are usually found in memory;
therefore, they can be retrieved quickly.
The first page (page 0) in
every file is the file header page. This page contains information about
the file, such as the database to which the file belongs, the filegroup
it is in, the minimum size, and its growth increment.
The second page (page 1) in
each file is the page free space (PFS) page. The PFS page keeps track of
the other pages in the database file. The PFS uses 1 byte for each
page. This byte keeps track of whether the page is allocated, whether it
is empty, and, if it is not empty, how full the page is. A single PFS
page can keep track of 8,000 contiguous pages. Additional PFS pages are
created as needed.
The third page (page 2) in
each file is the global allocation map (GAM) page. This page tracks
allocated extents. Each GAM page tracks 64,000 extents, and additional
GAM pages are allocated as needed. The GAM page contains 1 bit for each
extent, which is set to 0 if the extent is allocated to an object and to 1 if it is free.
The fourth page (page 3) is the
secondary GAM (SGAM) page. The SGAM page tracks allocated mixed extents.
Each SGAM page tracks 64,000 mixed extents, and additional SGAM pages
are allocated as needed. A bit set to 1 for an extent indicates a mixed extent with pages available.
Primary Files
The primary data file
is the data file that keeps track of all the other data files used by
the database. It is an operating system file that typically has the file
extension .mdf. SQL Server does not require that it have this .mdf
extension, but it is recommended for consistency. The primary data file
is the first file created for a database. Each database must have only
one primary file. This file stores data for any database objects mapped
to it, and it contains references to any other database files created.
In many cases, the primary
data file is the only data file. There is no requirement to have more
than one data file, and often, a database contains only one primary data
file (for example, C:\mssql\mydb.mdf) and only one log file (for example, C:\mssql\mydb_log.ldf).
Secondary Files
You can create zero or more secondary data files in a database. These files, by default, are identified with the .ndf
extension, but the extension can be different. Secondary data files
provide an opportunity to spread the data that SQL Server stores over
more than one physical file. This capability can be particularly useful
for larger databases and can help with performance and management of
database files. Consider, for example, a situation in which a database
server has four physical drives available for the data file(s). Each
drive is 1GB in size, but the database you are creating is 2GB. In this
example, the database will not fit on one drive. A solution to this
problem is to create a primary data file on one of the drives and a
secondary data file on each of the three remaining drives. SQL Server
automatically spreads the 2GB database across the four data files
located on four separate drives.
Secondary files also provide
some added flexibility for backing up or copying databases. This is
most apparent with large databases. For example, let’s say you have a
100GB database, and it contains only a primary data file. If you want to
move this database to another environment, you must have a drive that
is at least 100GB to store the primary data file. If you want to copy
the database to a server that has 10 50GB drives, you cannot do it. You
have the space across all 10 drives, but you do not have a single drive
that can hold the primary data file. If, however, you create the
database with several secondary files, you have the option of placing
each of the secondary files on a separate drive.
Tip
You can use the sys.master_files catalog view to list the database files for all the databases. For example, SELECT db_name(database_id),* from sys.master_files order by 1 returns all the database files, ordered by the name of the database they belong to. You can change the sort order for the SELECT statement and order it by physical_name to quickly locate a database file and find which database is using that file.
Using Filegroups
Filegroups
allow you to align certain database objects with specific data files.
Tables, indexes, and large object (LOB) data can be assigned to a
filegroup. A filegroup can be associated with one or more data files.
The alignment of data and indexes to filegroups can provide performance
benefits and improve manageability. Each database has at least one
filegroup, called the primary filegroup.
This filegroup, by default, contains the primary data file and any
other secondary data files that have not been specifically aligned with
another filegroup. Any database object that you create without
specifying a filegroup is created in the primary filegroup.
Additional filegroups can be
created and aligned with secondary data files. There is no requirement
to have more than one filegroup, but additional filegroups give you
added flexibility. Filegroups can be aligned with data files that can be
stored on separate disk drives to improve data access. This improvement
is facilitated by concurrent disk access across the disk drives
assigned to the filegroups.
Tip
If too many outstanding
I/Os are causing bottlenecks in the disk I/O subsystem, you might want
to consider spreading the files across more disk drives. Performance
Monitor can identify I/O bottlenecks by monitoring the PhysicalDisk object and Disk Queue Length counter. You should consider spreading the files across multiple disk drives if the Disk Queue Length
counter is greater than two times the number of spindles on the disk.
For example, you could create a filegroup called UserData_FG, consisting of three files spread over three physical drives. You could create another filegroup named Index_FG, with a single file, on a fourth drive. Then, when you create the tables, you can create them on the UserData_FG filegroup. You can create indexes on the Index_FG
filegroup. This reduces contention between tables because the data is
spread over three disks and can be accessed independently of the
indexes. If more storage is required in the future, you can easily add
additional files to the index or data filegroup, as appropriate.
You can create filegroups at
the time the database is created, or you can add them after the database
is created. When you create filegroups along with the database, the
definition for the filegroup is contained in the CREATE DATABASE statement. Following is an example of a CREATE DATABASE statement with filegroup definitions:
CREATE DATABASE [mydb] ON PRIMARY
( NAME = N'mydb',
FILENAME = N'C:\mssql2008\data\mydb.mdf' ,
SIZE = 2048KB , FILEGROWTH = 1024KB ),
FILEGROUP [Index_FG]
( NAME = N'mydb_index1',
FILENAME = N'I:\mssql2008\data\mydb_index1.ndf' ,
SIZE = 2048KB , FILEGROWTH = 1024KB ),
FILEGROUP [UserData_FG]
( NAME = N'mydb_userdata1',
FILENAME = N'D:\mssql2008\data\mydb_userdata1.ndf' ,
SIZE = 2048KB , FILEGROWTH = 1024KB ),
( NAME = N'mydb_userdata2',
FILENAME = N'E:\mssql2008\data\mydb_userdata2.ndf' ,
SIZE = 2048KB , FILEGROWTH = 1024KB ),
( NAME = N'mydb_userdata3',
FILENAME = N'F:\mssql2008\data\mydb_userdata3.ndf' ,
SIZE = 2048KB , FILEGROWTH = 1024KB )
LOG ON
( NAME = N'mydb_log',
FILENAME = N'L:\mssql2008\log\mydb_log.ldf' ,
SIZE = 1024KB , FILEGROWTH = 10%)
This example creates a database named mydb that has three filegroups. The first filegroup, PRIMARY, contains the .mdf file. Index_FG contains one file: I:\mssql2008\data\mydb_index1.ndf. The third filegroup, UserData_FG, contains three data files located on the D:, E:, and F:
drives. This example demonstrates the relationship between databases,
filegroups, and the underlying operating system files.
After you create a
database with multiple filegroups, you can then create a database object
on a specific filegroup. In the preceding example, you could use the
filegroup named UserData_FG to hold user-defined tables, and you could use the filegroup named Index_FG
for the database indexes. You assign database objects at the time you
create the object. The following example demonstrates the creation of a
user-defined table on the UserData_FG filegroup and the creation of an index for that table on the Index_FG filegroup:
CREATE TABLE dbo.Table1
(TableId int NULL,
TableDesc varchar(50) NULL)
ON [UserData_FG]
CREATE CLUSTERED INDEX [CI_Table1_TableID] ON [dbo].[Table1]
( [TableId] ASC)
ON [Index_FG]
Any objects not explicitly created on a filegroup are created on the default filegroup. The PRIMARY
filegroup is the default filegroup when a database is created. You can
change the default filegroup, if necessary. If you want to change the
default group to another group, you can use the ALTER DATABASE command. For example, the following command changes the default filegroup for the mydb database:
ALTER DATABASE [mydb] MODIFY FILEGROUP [UserData_FG] DEFAULT
You can also change the
default filegroup by right-clicking the database in the Object Explorer,
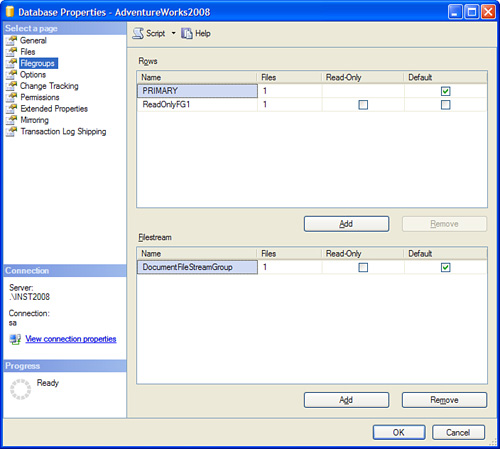
choosing Properties, and selecting the Filegroups page. Then you select
the check box labeled Default to make the given filegroup the default. Figure 1 shows the filegroups for the AdventureWorks2008 database, with the primary filegroup selected as the default.
When creating filegroups, you should keep in mind the following restrictions:
- You can’t move a data file to another filegroup after it has been added to the database.
- Filegroups apply only to data files and not to log files.
- A data file can be part of only one filegroup and cannot be spread across multiple filegroups.
- You can have a maximum of 32,767 filegroups for each database.
Note
Using SANs and RAID arrays
for the database disk subsystem diminishes the need for filegroups. SAN
and RAID systems typically have many disks mapped to a single data
drive. This inherently allows for concurrent disk access without
requiring the creation of a filegroup with multiple data files.
Using Partitions
Partitioning
in SQL Server 2008 allows for a single table or index to be aligned to
more than one filegroup. This capability was introduced in SQL Server
2005. Prior to SQL Server 2005, you could use filegroups to isolate a
table or an index to a single filegroup, but the table or index could
not be spread across multiple filegroups or data files. The ability to
spread a table or an index across multiple filegroups is particularly
useful for large tables. You can partition a table across multiple
filegroups and have data files live on separate disk drives to improve
performance.
Transaction Log Files
A transaction
is a mechanism for grouping a series of database changes into one
logical operation. SQL Server keeps track of each transaction in a file
called the transaction log. This log file usually has the extension .ldf,
but it can have a different extension. Typically, there is only one log
file. You can specify multiple log files, but these files are accessed
sequentially. If multiple files are used, SQL Server fills one file
before moving to the next. You realize no performance benefit by using
multiple files, but you can use them to extend the size of the log.
Note
The transaction log file is not a
text file that can be read by opening the file in a text editor. The
file is proprietary, and you cannot easily view the transactions or
changes within it. However, you can use the undocumented DBCC LOG (database name)
command to list the log contents. The output is relatively cryptic, but
it can give you some idea of the type of information that is stored in
the log file.
Because the transaction log
file keeps track of all changes applied to a database, it is very
important for database recovery. The transaction log is your friend: it
can prevent significant data loss and provide recovery that is not
possible without it. Consider, for example, a case in which a database
is put in simple recovery mode. In short, this causes transaction detail
to be automatically removed from the transaction log. This option is
often selected because the transaction log is seen as taking too much
disk space. The problem with simple mode is that it limits your ability
to recover transactions. If a catastrophic failure occurs, you can
restore your last database backup, but that may be it. If that backup
was taken the night before, all the database work done that day is lost.
If your database is not in
simple mode (Full or Bulk-Logged), and the transaction log is intact,
you have much better recovery options. For example, if you back up your
transaction log periodically (for example, every hour) and a
catastrophic error occurs, your data loss is limited. You still need to
restore your last database backup, but you have the option of applying
all the database changes stored in your transaction log. With hourly
backups, you should lose no more than an hour’s worth of work.
How the Transaction Log Works
SQL
Server utilizes a write-ahead log. As changes are made to data through
transactions, those changes are written immediately to the transaction
log when the transaction is complete. The write-ahead log guarantees
that all data modifications are written to the log prior to being
written to disk. By writing each change to the transaction log before it
is written to the database, SQL Server can increase I/O efficiency to
the data files and ensure data integrity in case of system failure.
To fully understand the
write-ahead log, you must first understand the role of SQL Server’s
cache or memory as it relates to database updates. SQL Server does not
write updates directly to the data page on disk. Instead, SQL Server
writes a change to a copy of the data page that has been placed in
memory. Pages changed in memory and not yet written to disk are called dirty pages.
The same basic approach is used for transaction log updates. The update
to the log is performed in the log cache first, and it is written to
disk at a later time. The time when the updates are actually written
from cache to disk is called a checkpoint.
The checkpoint occurs periodically, and SQL Server ensures that dirty
pages are not written to disk before the corresponding log entry is
written to disk.
The write-ahead log was
designed for performance reasons, and it is critical for the recovery
process after a system failure. If the system fails, an automatic
recovery process is initiated when SQL Server restarts. This recovery
process can use the checkpoint marker in the log file as a starting
point for recovery. SQL Server examines all transactions after the
checkpoint. If they are committed transactions, they are rolled forward;
if they are incomplete transactions, they are rolled back, or undone.
Note
Changes were made in SQL Server
2005 that improve the availability of the database during the recovery
process. These changes have been carried forward to SQL Server 2008. In
versions prior to SQL Server 2005, the database was not available until
it was completely recovered and the roll-forward and roll-back processes
were complete. In versions following SQL Server 2005, the database is
made available right after the roll-forward process. The roll-back or
undo process can occur while users are in the database. This feature,
known as Fast Recovery, is available only with the Enterprise Edition of
SQL Server 2008.
