Using Multiple Indexes
SQL Server allows the
creation of multiple indexes on a table. If a query has multiple SARGs
that can each be efficiently searched using an available index, the
Query Optimizer in SQL Server can make use of multiple indexes by
intersecting the indexes or using the index union strategy.
Index Intersection
Index
intersection is a mechanism that allows SQL Server to use multiple
indexes on a table when you have two or more SARGs in a query and each
can be efficiently satisfied using an index as the access path. Consider
the following example:
--First, create 2 additional indexes on sales to support the query
create index ord_date_idx on sales(ord_date)
create index qty_idx on sales(qty)
go
select * from sales
where qty = 816
and ord_date = '1/2/2008'
In this example, two additional nonclustered indexes are created on the sales table: one on the qty column and one on the ord_date
column. In this example, the Query Optimizer considers the option of
searching the index leaf rows of each index to find the rows that meet
each of the search conditions and joining on the matching bookmarks
(either the clustered index key or RIDs if it’s a heap table) for each
result set. It then performs a merge join on the bookmarks and uses the
output from that to retrieve the actual data rows for all the bookmarks
that are in both result sets.
The index intersection
strategy is applied only when the cost of retrieving the bookmarks for
both indexes and then retrieving the data rows is less than that of
retrieving the qualifying data rows using only one of the indexes or
using a table scan.
You can go through the same
analysis as the Query Optimizer to determine whether an index
intersection makes sense. For example, the sales table has a clustered index on stor_id, ord_num, and title_id,
and this clustered index is the bookmark used to retrieve the data rows
for the matching data rows found via the nonclustered indexes. Assume
the following statistics:
There are 1,200 rows estimated to match where qty = 816.
There are approximately 215 index rows per leaf page for the index on qty.
There are 212 rows estimated to match where ord_date = '1/2/2008'.
There are approximately 185 index rows per leaf page for the index on ord_date.
The Query Optimizer estimates that the overlap between the two result sets is 1 row.
The number of levels in the index on qty is 3.
The number of levels in the index on ord_date is 3.
The number of levels in the clustered index on the sales table is 3.
The sales table is 1,252 pages in size.
Using this information, you can calculate the I/O cost for the different strategies the Query Optimizer can consider.
A table scan would cost 1,252 pages.
A standard data row retrieval via the nonclustered index on qty would have the following approximate cost:
| 2 | index page reads (root and intermediate pages to locate first leaf page) |
| + 6 | leaf page reads (1200 rows / 215 rows per page) |
| + 3600 | (1,200 rows × 3 pages per bookmark lookup via the clustered index) |
| = 3,608 | pages |
A standard data row retrieval via the nonclustered index on ord_date would have the following approximate cost:
| 2 | nonclustered index page reads (root and intermediate pages) |
| + 2 | nonclustered leaf page reads (212 rows / 185 rows per page) |
| + 636 | (212 rows × 3 pages per bookmark lookup via clustered index) |
| = 640 | pages |
The index intersection is estimated to have the following cost:
| 8 | pages (1 root page + 1 intermediate page + the 6 leaf pages to find all the bookmarks for the 1,200 matching index rows on qty) |
| + 4 | pages (1 root page + 1 intermediate page + 2 leaf pages to find all the bookmarks for the 212 matching index rows on ord_date) |
| + 3 | page reads to find the 1 estimated overlapping row between the two indexes using the clustered index |
| = 15 | pages |
As you can see from
these examples, the index intersection strategy is definitely the
cheapest approach. If at any point the estimated intersection cost
reaches 640 pages, SQL Server just uses the single index on ord_date and checks both search criteria against the 212 matching rows for ord_date.
If the estimated cost of using an index in any way ever exceeds 1,252
pages, a table scan is likely to be performed, with the criteria checked
against all rows.
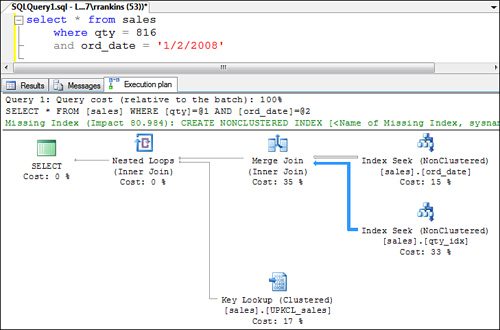
When an index
intersection is used to retrieve the data rows from a table with a
clustered index, you see a query plan similar to the one shown in Figure 8.
If the table does not have a
clustered index (that is, a heap table like the sales_noclust table in
the bigpubs2008 database) and has supporting nonclustered indexes for an
index intersection, you see a query plan similar to the one shown in Figure 9.
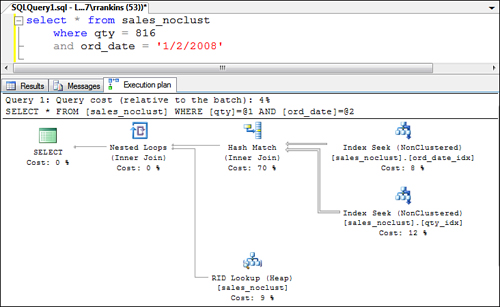
Notice that in the example shown in Figure 9,
the Query Optimizer performs a hash join rather than a merge join on
the RIDs returned by each nonclustered index seek and uses the results
from the hash join to perform an RID lookup to retrieve the matching
data rows.
Note
To duplicate the query plan shown in Figure 35.9, you need to create the following two additional indexes on the sales_noclust table:
create index ord_date_idx on sales_noclust(ord_date)
create index qty_idx on sales_noclust(qty)
The Index Union Strategy
You see a strategy similar to an index intersection applied when you have an OR condition between your SARGs, as in the following query:
select * from sales
where title_id = 'DR8514'
or ord_date = '2006-01-01 00:00:00.000'
The index union strategy (often referred to as the OR
strategy) is similar to an index intersection, with one slight
difference. With the index union strategy, SQL Server executes each part
separately, using the index that matches the SARG, but after combining
the results with a merge join, it removes any duplicate bookmarks for
rows that match both search arguments. It then uses the unique bookmarks
to retrieve the result rows from the base table.
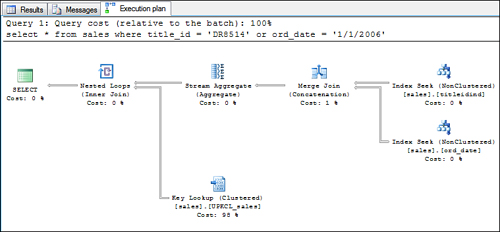
When the index union strategy is used on a table with a clustered index, you see a query plan similar to the one shown in Figure 10.
Notice the addition of the stream aggregation step, which
differentiates it from the index intersection query plan. The stream
aggregation step performs a grouping on the bookmarks returned by the
merge join to eliminate the duplicate bookmarks.
The following steps describe how SQL Server determines whether to use the index union strategy:
1. | Estimate
the cost of a table scan and the cost of using the index union
strategy. If the cost of the index union strategy exceeds the cost of a
table scan, stop here and simply perform a table scan. Otherwise,
continue with the succeeding steps to perform the index union strategy.
|
2. | Break the query into multiple parts, as in this example:
select * from sales where title_id = 'DR8514'
select * from sales where ord_date = '2006-01-01 00:00:00.000'
|
3. | Match each part with an available index.
|
4. | Execute each piece and perform a join on the row bookmarks.
|
5. | Remove any duplicate bookmarks.
|
6. | Use the resulting list of unique bookmarks to retrieve all qualifying rows from the base table.
|
If any one of the OR
clauses needs to be resolved via a table scan for any reason, SQL
Server simply uses a table scan to resolve the whole query rather than
applying the index union strategy.
When
the index union strategy is used on a heap table (such as the
sales_noclust table), you see a query plan similar to the one shown in Figure 11.
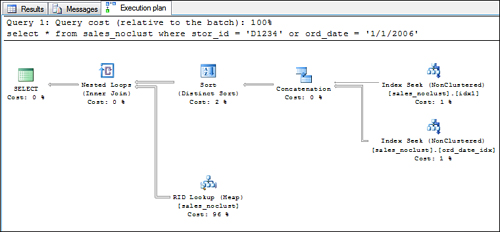
Notice that the merge join is replaced with a concatenation operation,
and the stream aggregate is replaced with distinct sort operation.
Although the steps are slightly different from the index intersection
strategy, the result is similar: a list of unique RIDs is returned, and
they are used to retrieve the matching data rows in the table itself.
When the OR in the
query involves only a single column and a nonclustered index exists on
the column, the Query Optimizer in SQL Server 2008 typically resolves
the query with an index seek against the nonclustered index and then a
bookmark lookup to retrieve the data rows. Consider the following query:
select * from sales
where ord_date in ('6/15/2005', '9/28/2008', '6/25/2008')
This query is the same as the following:
select * from sales
where ord_date = '6/15/2005'
or ord_date = '9/28/2008'
or ord_date = '6/25/2008'
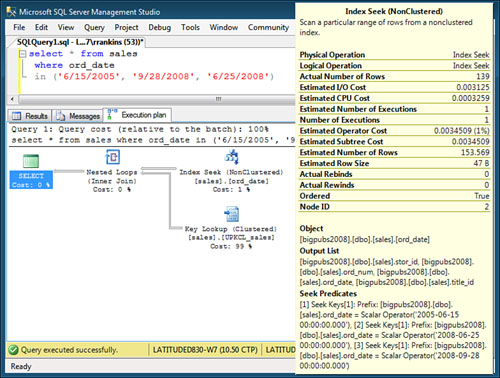
To process this query, SQL
Server performs a single index seek that looks for each of the search
values and then joins the list of bookmarks returned with either the
clustered index or the RIDs of the target table. No removal of
duplicates is necessary because each OR condition matches a distinct set of rows. Figure 12 shows an example of the query plan for multiple OR conditions against a single column.
Index Joins
Besides using the
index intersection and index union strategies, another way of using
multiple indexes on a single table is to join two or more indexes to
create a covering index. This is similar to an index intersection,
except that the final bookmark lookup is not required because the merged
index rows contain all the necessary information. Consider the
following example:
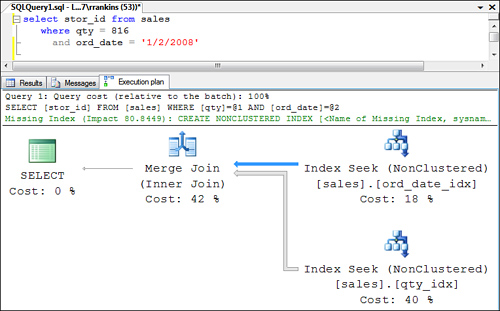
select stor_id from sales
where qty = 816
and ord_date = '1/2/2008'
Again, the sales table contains indexes on both the qty and ord_date columns. Each of these indexes contains the clustered index as a bookmark, and the clustered index contains the stor_id
column. In this instance, when the Query Optimizer merges the two
indexes using a merge join, joining them on the matching clustered
indexes, the index rows in the merge set have all the information needed
to resolve the query because stor_id
is part of the nonclustered indexes. There is no need to perform a
bookmark lookup on the data page. By joining the two index result sets,
SQL Server creates the same effect as having one covering index on qty, ord_date, and stor_id on the table. If you use the same numbers as in the “Index Intersection” section presented earlier, the cost of the index join would be as follows:
| 8 | pages (1 root page + 1 intermediate page + the 6 leaf pages to find all the bookmarks for the 1,200 matching index rows on qty) |
| + 4 | pages (1 root page + 1 intermediate page + 2 leaf pages to find all the bookmarks for the 212 matching index rows on ord_date) |
| = 12 | pages |
Figure 13
shows an example of the execution plan for an index join. Notice that
it does not include the bookmark lookup present in the index
intersection execution plan (refer to Figure 8).