Creating an Application Deployment Plan
The stateful
applications that server clusters host usually have greater capabilities
than the stateless applications used on Network Load Balancing
clusters. This means that you have more flexibility in how you deploy
the applications on the cluster. Windows Server 2003 can host the
following two basic types of applications in a server cluster:
Single-instance applications
Applications that can run on no more than one server at a time, using a
given configuration. The classic example of a single-instance
application is the DHCP service. You can run a DHCP server with a
particular scope configuration on only one server at a time, or you risk
the possibility of having duplicate IP addresses on your network. To
run an application of this type in a cluster, the application can be
running on only one node, while other nodes function as standbys. If the
active node malfunctions, the application fails over to one of the
other nodes in the cluster.
Multiple-instance applications Applications in which duplicated (or cloned) code can run on multiple nodes in a cluster (as in an NLB cluster) or in which the code can be partitioned,
or split into several instances, to provide complementary services on
different cluster nodes. With some database applications, you can create
partitions that respond to queries of a particular type, or that
furnish information from a designated subset of the database.
Deploying Single-Instance Applications
Deploying one
single-instance application on a cluster is simply a matter of
installing the same application on multiple nodes and configuring one
node to be active, while the others remain passive until they are
needed. This type of deployment is most common in two-node clusters,
unless the application is so vital that you feel you must plan for the
possibility of multiple server failures.
When you plan to run more
than one single-instance application on a cluster, you have several
deployment alternatives. You can create a separate two-node cluster for
each application, with one active and one passive node in each, but this
requires having two servers standing idle. You can create a three-node
cluster, with two active nodes, each running one of the applications,
and one passive node functioning as the standby for both applications.
If you choose this configuration, the passive node must be capable of
running both applications at once, in the event that both active nodes
fail. A third configuration would be to have a two-node cluster with one
application running on each, and each server active as a standby for
the other. In this instance, both servers must be capable of running
both applications.
|
This talk of
running multiple applications on a server cluster introduces one of the
most important elements of cluster application deployment: capacity
planning. The servers in your cluster must have sufficient memory and
enough processing capabilities to function adequately in your worst-case
scenario.
For example, if your
organization is running five critical applications, you can create a
six-node cluster with five active nodes running the five applications
and a single passive node functioning as the standby for all five. If
your worst-case scenario is that all five active nodes fail, the single
passive node had better be capable of running all five applications at
one time with adequate performance for the entire client load.
In this example, the
possibility of all five active nodes failing is remote, but you must
decide on your own worst-case scenario, based on the importance of the
applications to your organization.
|
Deploying Multiple-Instance Applications
In
a multiple-instance application, more than one node in the cluster can
be running the same application at the same time. When deploying
multiple-instance applications, you either clone them or partition them.
Cloned applications are rare on server clusters. Most applications that
require this type of deployment are stateless and are better suited to a
Network Load Balancing cluster than to a server cluster.
Partitioning
an application means that you split the application’s functionality
into separate instances and deploy each one on a separate cluster node.
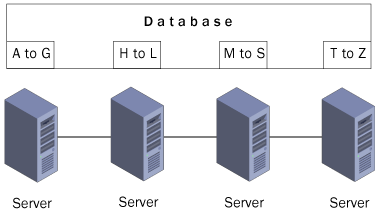
For example, you can configure a database application on a four-node
server cluster so that each node handles requests for information from
one fourth of the database, as shown in Figure 5.
When an application provides a number of different services, you might
be able to configure each cluster node to handle one particular service.
Note
With
a partitioned application, some mechanism must distribute the requests
to the appropriate nodes and assemble the replies from multiple nodes
into a single response for the client. This mechanism, like the
partitioning capability itself, is something that developers must build
into the application; these functions are not provided by the clustering
capability in Windows Server 2003 by itself. |
Partitioning by itself can
provide increased application efficiency, but it does not provide high
availability. Failure of a node hosting one partition renders part of
the database or certain services unavailable. In addition to
partitioning the application, you must configure its failover
capabilities. For example, in the four-node, partitioned database
application mentioned earlier, you can configure each partition to fail
over to one of the other nodes in the cluster. You can also add one or
more passive nodes to function as standbys for the active nodes. Adding a
single passive node to the four-node cluster would enable the
application to continue running at full capacity in the event of a
single node failure. It would be necessary for servers to run multiple
partitions at once only if multiple server failures occurred.
Planning
Here
again, you must decide what is the worst-case scenario for the cluster
and plan your server capacity accordingly. If you want the four-node
cluster to be able to compensate for the failure of three out of four
nodes, you must be sure that each server is capable of running all four
of the application’s partitions at once. |
If you plan to deploy
more than one multiple-instance application on your cluster, the problem
of configuring partitions, failover behavior, and server capacity
becomes even more complex. You must plan for all possible failures and
make sure that all the partitions of each application have a place to
run in the event of each type of failure.
Selecting a Quorum Model
Every node in a server
cluster maintains a copy of the cluster database in its registry. The
cluster database contains the properties of all the cluster’s elements,
including physical components such as servers, network adapters, and
shared storage devices; and cluster objects such as applications and
other logical resources. When a cluster node goes offline for any
reason, its cluster database is no longer updated as the cluster’s
status changes. When the mode comes back online, it must have a current
copy of the database to rejoin the cluster, and it obtains that copy
from the cluster’s quorum resource.
A cluster’s
quorum contains all the configuration data needed for the recovery of
the cluster, and the quorum resource is the drive where the quorum is
stored. To create a cluster, the first node must be able to take control
of the quorum resource, so that it can save the quorum data there. Only
one system can have control of the quorum resource at any one time.
Additional nodes must be able to access the quorum resource so that they
can create the cluster database in their registries.
Selecting the location
for the quorum is a crucial part of creating a cluster. Server clusters
running Windows Server 2003 support the following three types of quorum
models:
Single-node cluster
A cluster that consists of only one server. Because there is no need
for a shared storage solution, the application data store and the quorum
resource are located on the computer’s local drive. The primary reason
for creating single-node clusters is for testing and development.
Single-quorum device cluster
The cluster uses a single quorum resource, which is one of the shared
storage devices accessible by all the nodes in the cluster. This is the
quorum model that most server cluster installations use.
Majority node set cluster
A separate copy of the quorum is stored in each cluster node, with the
quorum resource responsible for keeping all copies of the quorum
consistent. Majority node set clusters are particularly well suited to
geographically dispersed server clusters and clusters that do not have
shared data storage devices.
Tip
Be sure to understand the differences between the various quorum models supported by Windows Server 2003. |
Creating a Server Cluster
Before you actually
create the cluster, you must select, evaluate, and install a shared
storage resource and install the critical applications on the computers
running Windows Server 2003. All the computers that are to become
cluster nodes must have access to the shared storage solution you have
selected; you should know your applications’ capabilities with regard to
partitioning; and you should have decided how to deploy them. Once you
have completed these tasks, you will use the Cluster Administrator tool
to create and manage server clusters (see Figure 6).
To create a new cluster, you must have the following information available:
The name of the domain in which the cluster will be located
The host name to assign to the cluster
The static IP address to assign to the cluster
The name and password for a cluster service account
With this information in hand, you can proceed to deploy the cluster, taking the following basic steps:
1. | Start up the computer running Windows Server 2003 that will be the first node in the cluster.
At this time, the other servers that you will later add to the cluster should not be running.
|
2. | Use the Cluster Administrator application on the first server to create a new cluster.
During this process, the New Server Cluster Wizard detects the
storage devices and network interfaces on the computer, and determines
whether they are suitable for use by the cluster. You also supply the
name and IP address for the cluster and the name and password for the
cluster service account.
|
3. | Verify that the cluster is operational and that you can access the cluster disks.
At this point, you have created a single-node cluster.
|
4. | Start up the computers running Windows Server 2003 that will become the other nodes in the cluster.
|
5. | Use the Add Nodes Wizard in Cluster Administrator to make the other servers part of the cluster.
|
6. | Test
the cluster by using Cluster Administrator to stop the cluster service
on each node in turn, verifying that the cluster disks are still
available after each stoppage.
|
Once you have added all
the nodes to the cluster, you can view information about the nodes in
Cluster Administrator as well as manage the nodes and their resources
from a central location. In addition, there are many clustering features
you can use to configure how the cluster behaves under various
conditions.
|
When managing a
cluster, you frequently work with cluster resources. A cluster resource
is any physical or logical element that the cluster service can manage
by bringing it online or offline and moving it to a different node. By
default, the cluster resources supported by server clusters running
Windows Server 2003 include storage devices, configuration parameters,
scripts, and applications. When you deploy a third-party application on a
server cluster, the application developer typically includes resource
types that are specific to that application.
|
Some of the configuration tasks you can perform in Cluster Administrator are as follows:
Create resource groups
A resource group is a collection of cluster resources that functions as
a single failover unit. When one resource in the group malfunctions,
the cluster service fails the entire group over to another node. You use
the New Group Wizard to create resource groups, after which you can
create new resources or move existing resources into the group.
Define resource dependencies You
can configure a specific cluster resource to be dependent on other
resources in the same resource group. The cluster service uses these
dependencies to determine the order in which it starts and stops the
resources on a node in the event of a failover. For example, when an
application is dependent on a particular shared disk where the
application is stored, the cluster service always brings down the
application on a node before bringing down the disk. Conversely, when
launching the application on a new node, the service will always start
the disk before the application, so that the disk is available to the
application when it starts.
Configure the cluster network role
For each network to which a cluster is connected, you can specify
whether the cluster should use that network for client access only, for
internal cluster communications only, or for both.
Configure failover relationships
For each resource that the cluster manages, you can specify a list of
nodes that are permitted to run that resource. With this capability, you
can configure a wide variety of failover policies for your
applications.
Tip
It
is a good idea to spend some time exploring the Network Load Balancing
Manager and Cluster Administrator applications. Learn the function of
each parameter or setting in these two programs, using the online help
for assistance. |
Configuring Failover Policies
By configuring the
failover relationships of your cluster applications and other resources,
you can implement a number of different failover policies that control
which cluster nodes an application uses and when. With small server
clusters, failover is usually a simple affair because you don’t have
that many nodes to choose from. As server clusters grow larger, however,
their failover capabilities become more flexible. Some of the failover
policies you might consider using are as follows:
Failover pairs
In a large server cluster running several applications, each
application is running on one node and has one designated standby node.
This makes server capacity planning simple, as the servers are never
running more than one application. However, half of the cluster’s
processing capacity is not in use, and, in the event of multiple node
failures, some applications could go offline unless an administrator
intervenes.
Hot-standby server
A single node functions as the designated standby server for two or
more applications. This option uses the cluster’s processing capacity
more efficiently (fewer servers are idle), but might not handle multiple
node failures well. For capacity planning, the standby server only has
to be able to support the most resource-intensive application it might
run, unless you want to plan for multiple node failures, in which case
the standby must be capable of running multiple applications at once.
N+I An
expanded form of the hot-standby server policy, in which you configure a
number of active nodes running different applications (N) to fail over
to any one of a number of idle servers (I). As an example, you can
create a six-node server cluster with four applications running on four
separate nodes, plus two standby nodes that are idle. When one of the
active nodes malfunctions, its application fails over to one of the
standby servers. This policy is better at handling multiple server
failures than failover pairs or hot-standby servers.
Failover ring
Each node in a server cluster runs an application, and you configure
each application to fail over to the next node. This policy is suitable
for relatively small applications, because in the event of a failure, a
server might have to run two or more applications at once. In the event
of multiple node failures, the application load could be unbalanced
across the active nodes. For example, in a four-node cluster, if Server 1
fails, Server 2 must run its own application and that of Server 1. If
Server 2 then fails, Server 3 must take on the Server 2 and Server 1
applications in addition to its own, while Server 4 continues to run
only one application. This makes server capacity planning difficult.
Random
In some cases, the best policy is for the administrator not to define
any specific failover relationships at all, and let the cluster service
be responsible for failing over resources to other nodes in the cluster.
This policy is usually preferable for smaller applications, so that a
single node can conceivably run multiple applications if necessary.
Random failovers also place less of a burden on the cluster
administrator.
