In this section, we’ll look at
how the Table service scales using partitioning at the storage account
and table levels. To achieve a highly scalable service, the Table
service will split your data into more manageable partitions that can
then be apportioned out to multiple servers. As developers, we can
control how this data is partitioned to maximize the performance of our
applications.
Let’s look at how this is done at the storage account layer.
1. Partitioning the storage account
In this section, we’ll look at how data is partitioned, but we’ll leave performance optimization to a later section.
In figure 1,
there were two tables within a storage account (ShoppingCart and
Products). As the Table service isn’t a relational database, there’s no
way to join these two tables on the server side. Because there’s no
physical dependency between any two tables in the Table service, Windows
Azure can scale the data storage beyond a single server and store
tables on separate physical servers.
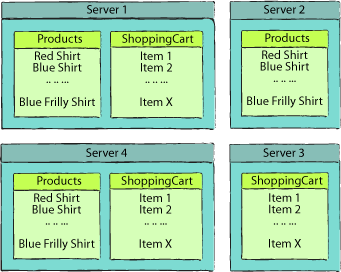
Figure 1
shows how these tables could be split across the Windows Azure data
center. In this figure, you’ll notice that the Products table lives on
servers 1, 2, and 4, whereas the ShoppingCart table resides on servers
1, 3, and 4. In the Windows Azure data center, you have no control over
where your tables will be stored. The tables could reside on the same
server (as in the case of servers 1 and 4) but they could easily live on
completely separate servers (servers 2 and 3). In most situations, you
can assume that your tables will physically reside on different servers.
|
In
order to protect you from data loss, Windows Azure guarantees to
replicate your data to at least three different servers as part of the
transaction. This data replication guarantee means that if there’s a
hardware failure after the data has been committed, another server will
have a copy of your data.
Once a transaction is
committed (and your data has therefore been replicated at least three
times), the Table service is guaranteed to serve the new data and will
never serve older versions. This means that if you insert a new Hawaiian
shirt entity on server 1, you can only be load balanced onto one of the
servers that has the latest version of your data. If server 2 was not
part of the replication process and contains stale data, you won’t be
load balanced onto that server. You can safely perform a read of your
data straight after a write, knowing that you’ll receive the latest copy
of the data.
The Amazon SimpleDB
database (which has roughly the same architecture as the Windows Azure
Table service) doesn’t have this replication guarantee by default. Due
to replication latency, it isn’t uncommon in SimpleDB for newly written
data not to exist or to be stale when a read is performed straight after
a write. This situation can never occur with the Windows Azure Table
service.
|
Now that you’ve seen how
different tables within a single account will be spread across multiple
servers to achieve scalability, it’s worth looking at how you can
partition data a little more granularly, and split data within a single
table across multiple servers.
2. Partitioning tables
One of the major issues
with traditional SQL Server–based databases is that individual tables
can grow too large, slowing down all operations against the table.
Although the Windows Azure Table service is highly efficient, storing
too much data in a single table can still degrade data access
performance.
The Table service allows you
to specify how your table could be split into smaller partitions by
requiring each entity to contain a partition key. The Table service can
then scale out by storing different partitions of data on separate
physical servers. Any entities with the same partition key must reside
together on the same physical server.
In tables 1 through to table 3,
all the data was stored in the same partition (Shirts), meaning that
all three shirts would always reside together on the same server, as
shown in figure 1. Table 4 shows how you could split your data into multiple partitions.
Table 4. Splitting partitions by partition key
| Timestamp | PartitionKey | RowKey | PropertyBag |
|---|
| 2009-07-01T16:20:32 | Red | 1 | Name: Red Shirt |
| | | | Description: Red |
| 2009-07-01T16:20:33 | Blue | 1 | Name: Blue Shirt |
| | | | Description: A Blue Shirt |
| 2009-07-01T16:20:33 | Blue | 2 | Name: Frilly Blue Shirt |
| | | | Description: A Frilly Blue Shirt |
| 2009-07-05T10:30:21 | Red | 2 | Name: Frilly Pink Shirt |
| | | | Description: A Frilly Pink Shirt |
| | | | ThumbnailUri: frillypinkshirt.png |
In table 4
the Red Shirt and the Frilly Pink Shirt now reside in the Red
partition, and the Blue Shirt and the Frilly Blue shirt are now stored
in the Blue partition. Figure 2 shows the shirt data from table 11.5
split across multiple servers. In this figure, the Red partition data
(Red Shirt and Pink Frilly Shirt) lives on server A and the Blue
partition data (Blue Shirt and Frilly Blue Shirt) is stored on server B.
Although the partitions have been separated out to different physical
servers, all entities within the same partition always reside together
on the same physical server.

Row Keys
The final property to
explain is the row key. The row key uniquely identifies an entity within
a partition, meaning that no two entities in the same partition can
have the same row key, but any two entities that are stored in different
partitions can have the same key. If you look at the data stored in table 11.5,
you can see that the row key is unique within each partition but not
unique outside of the partition. For example, Red Shirt and Blue Shirt
both have the same row key but live in different partitions (Red and
Blue).
The partition key and the
row key combine to uniquely identify an entity—together they form a
composite primary key for the table.
Indexes
Now that you have a basic
understanding of how data is logically stored within the data service,
it’s worth talking briefly about the indexing of the data.
There are a few rules of thumb regarding data-access speeds:
Retrieving an entity with a unique partition key is the fastest access method.
Retrieving
an entity using the partition key and row key is very fast (the Table
service needs to use only the index to find your data).
Retrieving
an entity using the partition key and no row key is slower (the Table
service needs to read all properties for each entity in the partition).
Retrieving
an entity using no partition key and no row key is very slow,
relatively speaking (the Table service needs to read all properties for
all entities across all partitions, which can span separate physical
servers).
We’ll explore these points in more detail as we go on.
|
Because data is
partitioned and replicated across multiple servers, all requests via the
REST API can be load balanced. This combination of data replication,
data partitioning, and a large web server farm provides you with a
highly scalable storage solution that can evenly distribute data and
requests across the data center. This level of horsepower and data
distribution means that you shouldn’t need to worry about overloading
server resources.
|
Now that we’ve covered the
theory of table storage, it’s time to put it into practice. Let’s open
Visual Studio and start storing some data.
