Configuring for High-Availability
From a scalability standpoint,
this can be beneficial because it enables us to leverage SQL Server’s
high-availability SQL clusters. Specifically, the minimal configuration
for us to establish a high-availability BizTalk infrastructure would
consist of:
This would result in an architecture similar to what is illustrated in Figure 1.

Techniques for Scaling
The
Enterprise edition of BizTalk Server is self-clustering, in as much as
it shares configuration information that is stored in a common
management database. New servers join a group, and start participating
in the workload. As a best practice, all servers have the identical
configuration, with the same items deployed to the local GACs.
Processing can be partitioned by controlling host instance and having
only certain host instances running on certain machines.
In the BizTalk
administrative tool, a host is a definition of a service. Many of the
features of BizTalk message processing, such as throttling and
threading, are defined at the host level. A host instance is a Windows
Service process that is an instance of the host type running on one or
more servers. Multiple instances of a host are used to add processing
power (horizontal scaling) and ensure high availability. Only one
instance of a specific host is allowed on a BizTalk Server. Note that
host instances can be defined on many or all of the BizTalk Servers and
enabled or disabled as appropriate to loading conditions.
This partitioning means
that you can (for example) have certain machines that are dedicated to
receiving messages, others that only send, and still others that only
run transformation services. This approach allows you to scale specific
partitions as needs evolve and requirements change.
The Systems Center
Operations Manager Management Pack for BizTalk Server provides further
visibility into the health and activities occurring on the server. Using
Operations Manager, it is possible to script compensations to events.
For example, if you have two BizTalk Servers running a receiving host
instance, and you suddenly receive a surge of messages that stress the
servers, you can script a compensating action that starts that host
instance on other machines. Most small and medium enterprises will never
need to go to this extreme; however, it’s reassuring to know that you
have the ability to construct adaptive networks that will respond to
changing needs and that you can enable services dynamically on an
as-required basis.
An example of a high-availability and scalable architecture is shown in Figure 2.
By studying this diagram we can identify multiple receive hosts behind a
load balance that distributes HTTP traffic. Because BizTalk nodes are
self-clustering in groups, the load balancer does not affect the nodes.
It is strictly there for the Web service.
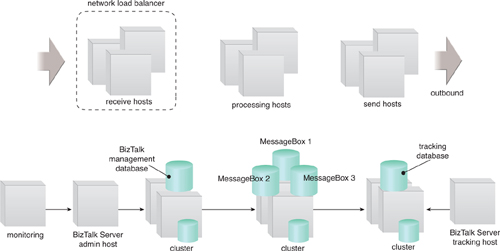
Should
there be load pressure over time, more machines can be added to the
various BizTalk groups, either dynamically or in advance, to accommodate
anticipated usage surges and increased workloads. For example, more
processing hosts can be added to accommodate complex processing.
To complete a
high-availability BizTalk infrastructure, disaster recovery can be
implemented through a combination of the BizTalk backup jobs and log
shipping. “Complete” high-availability needs highly-available
installations to be mirrored in separate (and geographically separated)
data centers, with log shipping being performed through a high-speed
connection. You can have high-availability in a given data center, but
should there be a catastrophic event that disables the data center, you
would need to fail over to the other data center.
Distributed ESBs
No discussion of ESBs would be
complete without touching on the topic of distributed (or federated)
ESBs. The notion here is that although you already have distributed
services within an ESB, you may have additional ESBs within your
enterprise, perhaps each in a separate domain service inventory or
several within the same service inventory.
Regardless of the
stratification reason, the existence of distributed ESB implementations
will result in a need to flow messages across ESB boundaries. The ESB
Toolkit provides building blocks that can be helpful to enable this type of inter-ESB messaging framework.
If they are in direct
communication, then an off-ramp on one ESB would send a message to an
on-ramp of another ESB. In other cases, you may opt to relay through an
intermediary, where a message is sent from one ESB to the Windows Azure
platform Service Bus and from there it is relayed to another ESB.
Note
Also worth noting is that
there are various strategies you could consider around using SQL
Server’s replication features to replicate the itinerary repository. You
can also explore using UDDI 3.0’s syndication capabilities to federate
distributed UDDI directories.
