Configuring a SQL Server database for Microsoft Dynamics NAV
It is imperative that
while configuring Microsoft Dynamics NAV, the hardware and software
recommendations from Microsoft are taken into consideration. From using
the latest version of Microsoft Windows, Microsoft SQL Server, or other
Microsoft stack products that are intended to be used with Dynamics NAV
or the hardware/server sizing, it is important that the Microsoft
guidelines for these are taken into account.
Let's discuss some of the
parameters and features that are to be properly set at the time of
setting up the Dynamics NAV database on the SQL Server.
Defining database and transaction log files
While defining the Database Files and Transaction Log Files
of the Dynamics NAV SQL server database, it is strongly recommended to
store the two sets on two separate physical drives. This not only helps
greatly in improved performance of the database, but is also a key
feature of a better disaster recovery management plan.
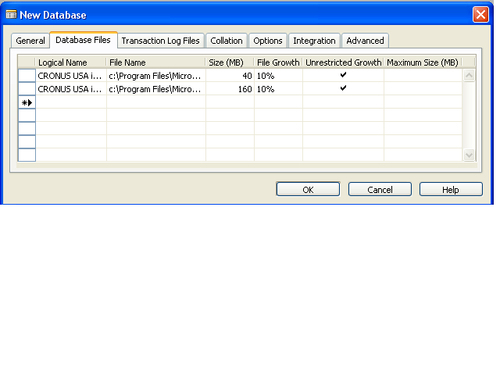
In order to avoid manually increasing the size of the database files every time it reaches the brink, we could check the Unrestricted Growth option for the database and log files. This can also be achieved by using the ALTER DATABASE T-SQL
command on the SQL Server after the database has been created. The only
disadvantage is that, this feature of unrestricted growth uses a lot of
system resources and we will have to monitor the disk size for the
database and log files.
Defining rules using collations
Collations
are used to define the rules for a particular language, character set,
or region. In SQL Server, the collation can be defined at various
levels. The various objects of an SQL Server instance inherit the
collation type from instance, though that can be changed later on for
each database, column, variable, or parameter. In the Microsoft Dynamics
NAV SQL Server database option, collation can be specified under the Collation tab while creating the database or by using the Alter Database option under the Collation tab.
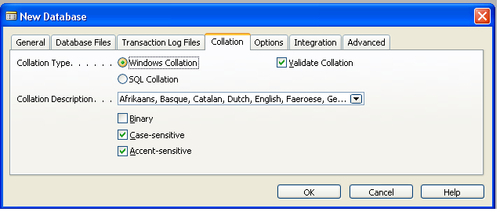
Binary is case sensitive and is the fastest sort order. However, it cannot be used concurrently with Case-sensitive and Accent-sensitive options.
Writing less expensive C/AL code for customizations
There are a few
considerations to keep in mind while writing a customized C/ AL code, as
poorly written code can affect the performance of the application or a
business process significantly.
Retrieving data using FINDFIRST/FINDLAST/FINDSET
Using FINDFIRST instead of the following FIND('-') statement is also an inexpensive command to retrieve the first record from the recordset.
The following is the code for retrieving the first record using the FIND statement:
GLEntry.SETRANGE(...);
IF NOT GLEntry.FIND('-') THEN
MESSAGE('No entries in the GL Entry table');
The previous code can be replaced with the following code:
GLEntry.SETRANGE(...);
IF NOT GLEntry.FINDFIRST THEN
MESSAGE('No entries in the GL Entry table');
Using FINDLAST instead of the following FIND('+') is an inexpensive way to retrieve the last record from the recordset.
The following is the code for retrieving the last record using the FIND('+') statement:
GLEntry.SETRANGE(...);
IF GLEntry.FIND('+') THEN
MESSAGE('Last entry no. used -'+ GLEntry."Entry No.");
The previous code can be replaced with the following code:
GLEntry.SETRANGE(...);
IF GLEntry.FINDLAST THEN
MESSAGE('Last entry no. used -'+ GLEntry."Entry No.");
FINDFIRST and FINDLAST should not be used with the REPEAT UNTIL or NEXT command, as these two commands do not create a cursor to the next record, which is needed in the loop.
Instead of using the loop statements with FIND('-') command, use the inexpensive statement FINDSET to find the subset of records in the recordset.
The following is the code for retrieving the subset of records using the FIND('-') statement:
IF GLEntry.FIND('-') THEN
REPEATUNTIL GLEntry.NEXT = 0;
The previous code can be replaced with the following code:
IF GLEntry.FINDSET THEN
REPEAT UNTIL GLEntry.NEXT = 0;
Using the NEXT statement
The use of the NEXT statement inadequately could be the source of the biggest performance glitches. The interpretation of NEXT by SQL has to be explicitly defined if a NEXT is used without finding a subset, with FINDFIRST or FINDLAST, or is used after a changed key/filter.
Using ISEmpty
Instead of using IF Recordset.FIND('-') THEN using IF Recordset.ISEMPTY THEN is more efficient and less taxing on the server resources.
Locking the recordset
While programming on the Dynamics NAV for SQL Server option, it is a good practice to use LOCKTABLE
and lock the recordset before modifying any records. This ensures that
the uncommitted dataset that is read from SQL Server is locked and
cannot be modified by another user.
Locking occurs when the following sequence of events takes place:
1. User X reads a record without using locktable.
2. User Y reads the same record without locks.
3. User Y modifies the record.
4. User X gets the error message Another user has modified the record for this tablename after you retrieved it from the database.
If both users X and Y in the
previous example use explicit locks before fetching the record, they are
blocked and will have to wait, until one or the other releases the
lock.
Deadlocks can
occur if both the users are blocking each other and both of them are
waiting for either one of them to release the lock or resources.
Let's take a look at the following example:
1. User X locks the customer, vendor table.
2. User Y locks the customer, vendor table.
3. User X gets the customer 10000 and User Y gets vendor 10000.
4. User X tries to get vendor 10000, User Y tries to get customer 10000.
5.
User X gets a deadlock warning, while user Y is able to get the desired
record. SQL Server randomly decides which user can get the record.
To avoid the previously mentioned conditions, we'll use the following guidelines at least whenever possible:
Disabling the "find-as-you-type" feature
The "find-as-you-type"
feature in Dynamics NAV takes a heavy toll on performance, as with every
keystroke, the SQL query is done.
