1. Heaps
When data is stored for a
table within your database when no clustered indexes are present, the
table is stored in what is called a heap. System objects, like sys.indexes and sys.partitions,
with index ID values of zero identify the table as a heap table. In
most instances, heaps are not the preferred method of storing your
tables because of the access method required for retrieving data. When
no indexes exist on a table, then scanning the entire table is the only
method for retrieving data from the table. After the execution of a
query against the table, SQL Server has to check every row in the table
to determine if it meets the conditions of the query. The method of
scanning an entire heap table is referred to as a table scan.
Most of the time, table scans are not the most efficient method of
retrieving data from a table; however, there are times when SQL Server
optimizer will determine that a table scan is the most efficient method
to retrieve the data.
2. Clustered Indexes
Clustered indexes are one of
the two main types of indexes supported in SQL Server. A clustered index
stores the rows of its underlying table in the sorted order of the
clustered index keys. The clustered index keys are the column(s) you
select to represent how you want data ordered on disk. Since the order
of the table is determined by the clustered index, only one clustered
index can be defined on a table. Clustered indexes are represented in
system tables and views, like sys.objectssys.partitions, by the value 1 in the index ID column. and
Queries against tables
that contain clustered indexes may perform at extremely fast rates or
dreadfully slow rates. When indexes are involved, you can scan an entire
index looking for the data that meets your criteria or seek a record
based on the supplied criteria. In other words, if you are looking for
an employee with an identification number of 100 and the table has a
clustered index on the identification number, then SQL Server will seek
employee 100, which is very fast. However, if you are looking for every
employee who has a first name of Joe and you have a clustered index on
an identification number, then SQL Server is going to scan the entire
clustered index looking for every Joe. That can take a while if you have
a large number of employees in the table.
3. Nonclustered Indexes
Nonclustered indexes are
the second main type of index supported in SQL Server. A nonclustered
index contains the index key value and the row identifier for finding
the rest of the data for every row in the table. Nonclustered indexes
can be created on clustered index and heap tables. When a nonclustered
index is created on a clustered index table, the row identifier holds
the clustered index key and that key points to the actual data. If the
nonclustered index exists on a heap table, then the row identifier
points to the address of the data pages. Regardless of the table type,
clustered or heap, retrieving the actual data pages requires additional
steps, thus increasing IO. Ideally, you want to decrease IO, not
increase it.
SQL Server 2008 allows you to
create up to 999 clustered indexes on a given table, and you can specify
the list of columns for each of those. But keep this in mind: Just
because SQL Server 2008 allows you to perform certain actions does not
mean that you are required to do so.
Nonclustered
indexes are represented in SQL Server 2008 system tables and views with
an index ID greater than 1. SQL Server 2008 will scan or seek on a
nonclustered index when the index keys are useful in finding the data
based on the criteria of the query being executed.
4. Structure of Indexes and the Heap
Indexes within SQL Server 2008
are stored in B-tree data structure. The B-tree data structure is
divided into three basic parts: the root (top-most level of the tree),
the leaf level (bottom-most portion of the tree), and the intermediate
level (everything in between). The root and intermediate levels contain
the keys specified during creation and depending on the index type,
clustered or nonclustered index, the row identifier with the clustered
index key or the address of the data pages. On the intermediate and leaf
level pages, SQL Server uses a double linked list to navigate from page
to page. Based on the search criteria of the query, SQL Server will
traverse the tree starting at the root heading downward until it reaches
the leaf level pages. Let's take a closer look at the structure of both
types of indexes.
4.1. Clustered Index Structure
Keep in mind that
clustered indexes determine the order of the data on disk. The key of a
clustered index will be sorted in ascending or descending order. For the
next couple of examples, let's assume that you have a table with over
300 employees in it. The employee table has several columns that include
employee ID, first name, and last name. If you cluster the employee
table on the employee ID, then Figure 1
demonstrates the structure of that clustered index on disk. The root
level page contains employee ID 100 and 200, with pointers to the pages
that are greater than 200 or less than 200. The intermediate level
contains the key value of employee IDs 1 and 100 and 200 and 300, along
with pointers to the page where that data is stored. The leaf level
pages actually contain all the data of each employee ID within the
table.
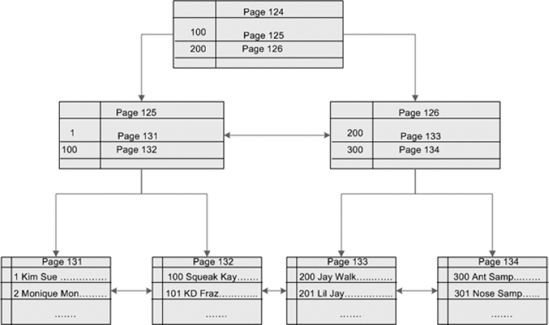
The following steps list the process that SQL Server goes through to retrieve data from clustered index structures.
Query the sys.system_internals_allocation_units to identify the root node page address for the index.
Compare the value from the query to the values on the root page.
Identify the uppermost key value that is less than or equal to the value from the query.
Trace the pointer to the page specified key value down to the next level.
Repeat steps 3 and 4 until you reach the leaf level pages.
Once
the leaf level pages are reached, SQL Server searches through data
pages looking for the query value. If no data pages are found, the query
will return no results.
4.2. Nonclustered Index Structure
Nonclustered index
structures look highly similar to the clustered index structures.
Nonclustered indexes have three main levels as well: the root level, the
leaf level, and the intermediate levels. The main difference between
the clustered index structure and the nonclustered index structure is
the data stored within the leaf level and the data row locator within
the structure. Remember that the leaf level pages in a nonclustered
index contain references to data pages or to index keys instead of the
actual data.
Figure 2
shows the structure of the nonclustered index. The example uses a first
name for the index key. The root level of the nonclustered index
contains the first name along with the pointer to the next page and the
data row locator. The intermediate level has the first name ranges
divided evenly, as well as the next page and data row locators. The leaf
level pages contain the keys, or first names, in this example. If the
underlying table is organized by a clustered index, then the leaf level
pages of the nonclustered index will contain clustered index keys (also
called data row locators). If the underlying table is a heap, then the leaf level pages will contain pointers to data pages in the heap.
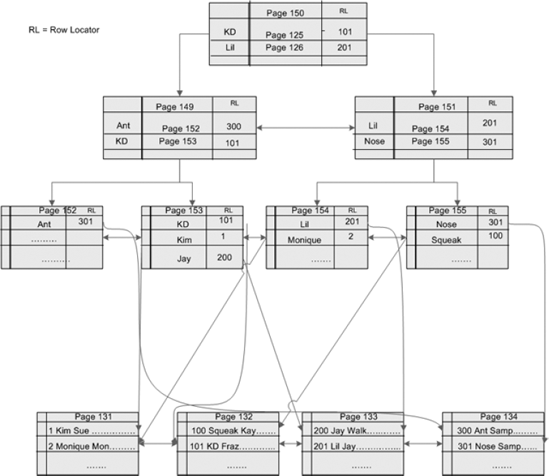
4.3. Heap Structure
We would like to briefly
mention the structure of heaps in this section. Unlike clustered and
nonclustered indexes, the data stored within a heap table has no
structure. The data stored within a heap table is linked by the index
allocation map (IAM) pages that are allocated for the object. The sys.system_internals_allocation_units
systems object points to the first IAM page where the data is stored.
Because of the lack of order within the heap, SQL Server has to scan
each page of the entire heap to determine what data meets the criteria
of any given query. Because of this, table scans on heaps are often
times inefficient. You should avoid scans on heaps as much as possible.
5. Indexes Created by Constraints
This section ensures you understand the terminology used when
people mention primary and unique indexes.
5.1. Primary Indexes
What in the world is a primary
index? I really don't know, but I have heard this term used frequently
by non-database administrators. (Well, that's my story and I'm sticking
to it.) Generally, most people who use the term primary index
are actually referring to the index created after they specify the
primary key for a table. The primary key can create a clustered or
nonclustered index that forces uniqueness within the key values and does
not allow null values. When someone says that the primary index is the
main index used for retrieving data, just smile and say yes; the
clustered index will determine the order of the data and will be used
frequently. You can correct the person if you want, but we often find it
easier to be subtle and slide the correct terms in there when you get
the chance.
5.2. Unique Indexes
Unique indexes are
created on the key columns of an index. A unique index forces
distinctness among the data for the specified columns. Tables can have
multiple unique indexes. Unique indexes allow nulls to exist in the key
columns. From a SQL Server perspective, it does not matter if a unique
index or a unique constraint is created first; the validation process of
the data is the same, and the result will consist of a unique index.
After creating the index, validation of the index keys occur for the
data in the table to ensure that the values are unique.
The validation of the key
values of a unique index happens before you insert data into the table.
If you are attempting to insert multiple records into a table and one
record violates the unique index, then none of the data will be inserted
and the entire statement will fail unless you set the IGNORE_DUP_KEY option to ON.
In batches where unique indexes are violated, the IGNORE_DUP_KEY option allows insertion of the records that don't violate the unique index, while only the offenders fail.
6. Other Ways to Categorize Indexes
There are many ways
to categorize index types. The distinction between clustered and
nonclustered is fundamental, and you'll commonly encounter the terms primary index and unique index.
But there are other ways to divide indexes into different types. The
following sections describe some of the types you'll encounter in your
work as a DBA.
6.1. Composite Indexes
Composite indexes are
those created on objects that contain multiple columns. Composite
indexes may include up to 16 columns that are all from the same table or
view. The combined column values of a composite index cannot be greater
than 900 bytes. Pay close attention to the structure of your columns
while creating your indexes. Make sure the index keys are in the same
order as the WHERE clause of your queries. SQL Server is more likely to use the index when the two are in the same order.
6.2. Filtered Indexes
Filtered indexes are a new feature of SQL Server 2008 whereby you can
create nonclustered indexes on subsets of data from the table. Think
about a WHERE clause on a table: If you
want to minimize the number of records retrieved from a table, then you
specify a condition within the WHERE
clause to prevent that data from being returned. Well, the filtered
index works in a similar fashion—you specify the rules to exclude data
from an index. Remember, nonclustered indexes contain rows for all the
data within a table. Filtered indexes will prevent all of the data from
being stored within the index.
Filtered indexes provide
benefits like improved query performance and data storage. From a
performance perspective, looking for data within a smaller subset of
records will decrease the seek time and increase query performance.
Filtered indexes will also utilize less space on disk because the index
does not have to store a record for every row within the table.
6.3. XML Indexes
SQL Server 2008 supports indexes
on the XML data type. XML indexes support two types: a primary index
and a secondary index. The primary XML index must be created first and
represents all of the tags, data, and paths for each row in the XML
column within the table. To increase performance, you can create
secondary XML indexes on the path, value, and properties of the XML
column depending on how the XML columns are queried. Once you understand
the data that will be retrieved from the XML column, spend some time
designing the appropriate index strategy on the column.
7. Other Index Concepts and Terminology
The following sections
describe other terms and concepts that you'll encounter when talking
about indexes. Understanding and applying these concepts will increase
your chances of creating effective and useful indexes.
7.1. Include Columns
Include columns are non-key
columns stored on the leaf level of nonclustered indexes. Keep in mind
that key columns of nonclustered indexes are stored at the intermediate
and leaf levels of indexes, while include columns are only stored on the
leaf levels. Include columns also allow you to bypass the restrictions
set for the composite keys by allowing you to have more than 16 columns
of a size larger than 900 bytes. You can have 1023 columns in an INCLUDE
statement without a size limit on disk. The primary benefit of include
columns and composite keys stem from the usefulness of covering your
queries.
7.2. Covering Queries
Covering your query generally means having the values needed for the SELECT clause and the WHERE
clause available in your nonclustered indexes. Because the data is
available in your nonclustered indexes, SQL Server does not have to
perform costly lookup operations to gather the remaining information
needed for the query. Your first thought may be to cover all queries,
but there is a cost associated with that. You have to be careful and
determine just which queries you want to cover based on the priority of
the queries within your system.
7.3. Searchable Arguments
Searchable
arguments (SARGs) are mentioned in SQL Server when discussing methods
for minimizing or filtering the results of a query. In other words, a
searchable argument is used when comparing a constant to columns in WHERE clauses and ON statements in a JOIN clause. Examples of searchable arguments include the following:
Using SARGs are the methods
SQL Server uses to identify an index to aid in data retrieval. When
creating indexes, you definitely want to think about the frequently
accessed searchable arguments used by the application.
7.4. Cardinality
When creating indexes in SQL Server, you always want to think about the cardinality of your data. Cardinality
in SQL Server refers to the uniqueness of the data within the columns.
The higher the cardinality, the less the data is duplicated in a given
column. The lower the cardinality, the more the data is the same within
the column. The query optimizer will utilize the cardinality of the data
when determining the most efficient execution plan to use.
Indexes that have a lot of
duplication, or low cardinality, will not be nearly as useful as an
index with very little duplication, or a high cardinality. Think about a
person table that has three columns in it: Social Security Number, Age,
and Favorite Color (only basic colors). The Social Security Number
column will have a higher cardinality than the Age column, which will
have a higher cardinality than Favorite Color. When creating your
indexes, you want to create them on Social Security number first,
followed by age, and then by color if you absolutely have to. Clearly,
looking for someone's Social Security number will be faster than finding
a person by their favorite color. You are going to return more rows
when searching by colors, requiring some additional filtering after
returning the data.
