Determining the Optimal Join Order
In addition to determining
the best join strategies, the Query Optimizer also evaluates and
determines the optimal join order that would result in the most
efficient query plan. In the query’s execution plan, you might find that
the order of the tables in the execution plan is a different order than
specified in the query. Regardless of the join strategy used, the Query
Optimizer needs to determine which table is the outer input and which
is the inner input to the join strategy chosen. For example, consider
the following query:
select a.au_lname, t.title, pubdate
from authors a
join titleauthor ta on a.au_id = ta.au_id
join titles t on ta.title_id = t.title_id
In addition to the possible
access paths and join strategies available, the server can consider the
following pool of possible join orders:
authors → titleauthor → titles
titles → titleauthor → authors
titleauthor → titles → authors
titleauthor → authors → titles
authors → titles → titleauthor
titles → authors → titleauthor
For each of these join
orders, the Query Optimizer considers the various access paths available
for each table as well as the different join strategies available. For
example, the Query Optimizer could consider the following possible join
strategies:
Perform a table scan on the authors table and for each row perform an index seek against the auidind index on titleauthor to find the matching rows by au_id. And for each matching row in titleauthor, perform an index seek against the primary key of the titles table to find the matching rows in titles by title_id.
Perform a table scan on the titles table and for each row perform an index seek against the titleidind index on titleauthor to find the matching rows by title_id. And for each matching row in titleauthor, perform an index seek against the primary key of the authors table to find the matching rows in authors by au_id.
Perform an index scan of the titleidind of the titleauthor table and use a hash join to match it with a clustered index scan of the titles table. And for each of the qualifying rows from this hash join, perform another hash join with an index scan of the aunmind index of the authors table.
Note
If you run this query
yourself and examine the query plan, you’ll likely see that the third
alternative is the one chosen by the Query Optimizer. Index scans are
performed on the authors and titleauthor
tables because the nonclustered indexes on those tables cover the join
query. That is, the nonclustered indexes contain all the columns
necessary to satisfy the join conditions as well as the requested result
columns.
These are just three of the
possibilities. There are many more options for the Query Optimizer to
consider as execution plans for processing this join. For example, for
each of the three options, there are other indexes to consider, and
there are other possible join orders and strategies to consider as well.
As you can see, there can be a
large number of execution plan options for the Query Optimizer to
consider for processing a join, and this example is a relatively simple
three-table join. The number of options increases exponentially as the
number of tables involved in the query increases.
Subquery Processing
SQL
Server optimizes subqueries differently, depending on how they are
written. For example, SQL Server attempts to flatten some subqueries
into joins when possible, to allow the Query Optimizer to select the
optimal join order rather than be forced to process the query
inside-out. The following sections examine the different types of
subqueries and how SQL Server optimizes them.
IN, ANY, and EXISTS Subqueries
In SQL Server, any query that contains a subquery introduced with an IN, = ANY, or EXISTS predicate is usually flattened into an existence join unless the outer query also contains an OR clause or unless the subquery is correlated or contains one or more aggregates.
An existence join is
optimized the same way as a regular join, with one exception: With an
existence join, as soon as a matching row is found in the inner table,
the value TRUE is returned, and SQL
Server stops looking for further matches for that row in the outer
table and moves on to the next row. A normal join would continue
processing to find all matching rows. The following query provides an
example of an existence join and a quantified predicate subquery that
will be converted to an existence join:
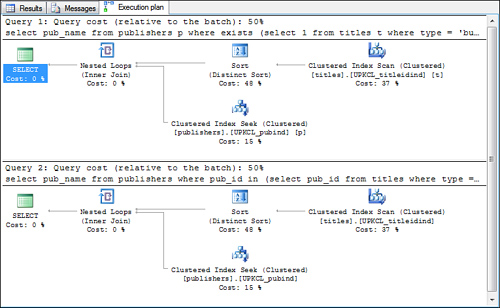
select pub_name from publishers p
where exists (select 1 from titles t
where type = 'business'
and t.pub_id = p.pub_id)
select pub_name from publishers
where pub_id in (select pub_id from titles
where type = 'business')
Figure 5
shows an example of the execution plan for both of these queries. You
can see that the query plans are the same, providing proof that the
quantified predicate subquery is being flattened into an existence join.
Materialized Subqueries
If an outer query is comparing a column against the result of a subquery using any of the comparison operators (=, >, <, >=, <=, !=),
and the subquery is not correlated, the results of the subquery are
often resolved—that is, materialized—before comparison against the outer
table column. For these types of queries, the Query Optimizer processes
the query inside-out.
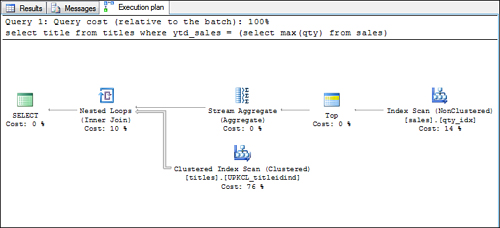
An example of this type of query is as follows:
select title from titles
where ytd_sales = (select max(qty) from sales)
In this example, the subquery is resolved first to find the maximum qty value from the sales table to compare against ytd_sales in the outer query. Figure 6 shows an example of a query plan for this materialized subquery.
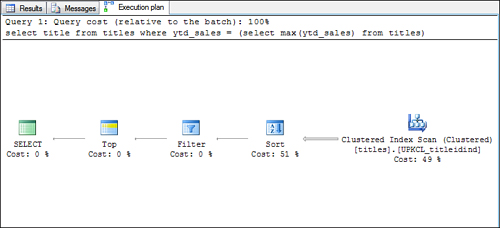
The following query is an interesting case in which the subquery is not materialized first:
select title from titles
where ytd_sales = (select max(ytd_sales) from titles)
In this example, with no index on the ytd_sales column, the Query Optimizer recognizes that a table scan is required on the titles table to find the maximum ytd_sales
value. Rather than run the subquery first using a table scan and then
use the value returned to perform another lookup against the titles table, it simply scans the titles table and returns and sorts the ytd_sales
value in descending order. It then simply returns the rows with the top
matching values because these rows are the ones where the ytd_sales value is the maximum. Figure 7 shows an example of a query plan for this subquery processing strategy.
Correlated Subqueries
A correlated subquery
contains a reference to an outer table in a join clause in the subquery.
Following is an example of a correlated subquery:
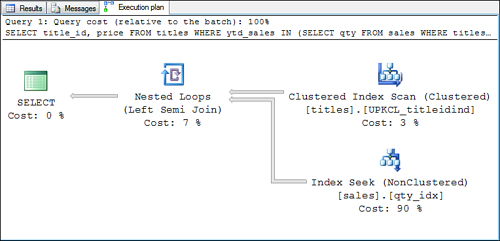
SELECT title_id, price
FROM titles
WHERE ytd_sales IN
(SELECT qty
FROM sales
WHERE titles.title_id = sales.title_id)
Because correlated subqueries
depend on values from the outer query for resolution, they cannot be
processed independently. Instead, SQL Server usually processes
correlated subqueries repeatedly, once for each qualifying outer row.
Often, a correlated subquery looks like a nested loop join. A sample
execution plan for the preceding correlated subquery example is shown in
Figure 8. Notice that an inner join using a left semi join is performed. Semi joins are joins that return rows from one table based on the existence of related rows in the other table. A left semi join
operation returns each row from the first (top or left) input when
there is a matching row in the second (bottom or right) input. If the
attributes are returned from the bottom (or right) table, it’s referred
to as a right semi join.
Note
The inverse of a semi join is
an anti–semi join. An anti–semi join looks for rows in one table based
on their nonexistence in the other, such as for a NOT IN or NOT EXISTS type subquery, or for some outer join queries.
However,
if there is no useful index on the correlated columns to find the
matching rows, the Query Optimizer may choose to perform a single search
against each table separately and perform a hash join against the
results.
