The top portion of the Search Administration page is shown in Figure 1
and presents a dashboard of System Status information with links to
configuration dialogue boxes for general search service configurations.
On the left side of the page is a Quick Launch organized into three
sections: Administration, Crawling, and Queries And Results.
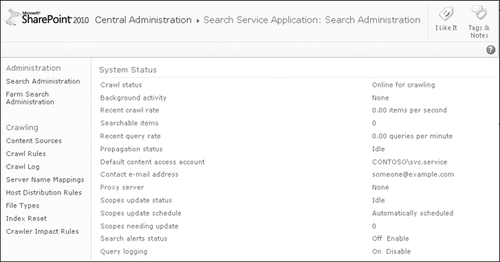
The top dashboard section
presents information on the crawl and indexing processes as well as the
recent query rate and scopes status. There are also six configuration
links.
The default
content access account was entered when you ran the Farm Configuration
Wizard and can be overridden here for this search service application’s
components.
The
Contact e-mail address is left behind by crawl components of this
service. This should be a monitored e-mail address, in case the crawler
is creating performance issues on remote sites.
The
Proxy server link opens the Farm Search Administration configuration
and changes the farm-wide settings, although it does not indicate that
it is not a local service setting.
The
scopes update schedule is a toggle between the automatic schedule of
the timer job and manually triggered updates. If there are scopes to be
updated, a link is presented to start the update process manually.
Search
alert status can be enabled/disabled here. Normally, it is
automatically disabled during an index reset but must be manually
enabled after the index is rebuilt.
If you disable Query logging, no data will be available for query reports.
1. Creating and Managing Content Sources
The first step in setting up
crawling is the creation of content sources. Click the Content Sources
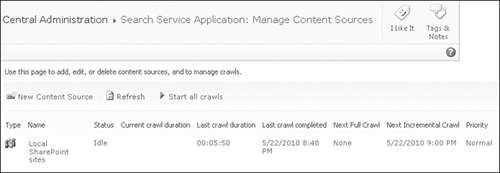
link in the Quick Launch (refer back to Figure 1) to open the Manage Content Sources page shown in Figure 2.
This page continues the dashboard theme to give the status of each
content source and crawl information that will be useful in scheduling crawls.
A content source is a
collection of addresses that can be crawled with the same connector or
protocol handler along with instructions about how deep to crawl from
the start address, how often to crawl the collection, and at what
priority.
When creating a new content
source, the name should be unique but meaningful to everyone managing
the search service. The default content source types are
A start address cannot appear
in more than one content source but does not have to start at the root
of an application. A single content source can contain up to 50 start
addresses and a search service application can have up to 50 content
sources. Start address entries are not checked for accuracy during the
creation of a content source. Start addresses should match the type of
content source you are creating.
For example, if you create a Web Sites content source, then be sure to
not include start addresses that start with file:// or some other type
of content that is not Web based.
The crawl settings
configuration is dependent on the content source type selected and
controls the depth of the crawl from the starting address. For a Web
Site content source, this includes how deep to follow hops within the
server and how far to follow hops to other servers. Unlimited in both
scenarios would be to crawl the Internet, starting at the specified
addresses.
You can create either Full
Crawl or Incremental Crawl schedules or both. Crawl schedules are not
required for content sources for which crawls
will be managed manually. It is not necessary to schedule a full crawl,
because starting an incremental crawl on a content source that has
never been crawled will result in a full crawl.
The ability to choose Normal
or High crawl priority for a content source is new in SharePoint 2010.
Items placed in the crawl queue are always crawled in their order in the
queue. Items from high priority content sources are always placed in
the queue before those from normal priority content sources, without
regard to when the crawls began on the content sources.
Finally, when creating a
content source, you may choose to begin a full crawl as soon as the
content source is created. Considering the resources consumed by full
crawls, they are usually scheduled when resources are available.
By default, a Local
SharePoint sites content source is always created for a search service,
and all applications associated with the service are placed in that
content source, as shown in Figure 3.
Although this does ensure that all content will be crawled, it is
seldom an optimum configuration because the crawls of content in
different locations will generally need to be managed independently.
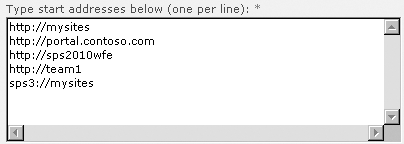
You can gain an understanding of the start addresses by examining the example shown in Figure 11-7. First, the address sps3://mysites
is a special crawl of the user profiles using the profile pages of the
My Site host. Profiles need to be crawled after they are imported and
before audiences are compiled. Incremental crawls
may not be required throughout the day at all, but certainly profile
data needs to be crawled on a different schedule and priority than other
content. Remember that profile data can be manually entered by users in
addition to imported from databases.
Depending on how personal sites are used in your organization, the content of the http://mysites
application will probably have a different schedule and priority than
other content. The content of a portal can be more or less dynamic than
that of a team collaborative site. The crawl scheduling for any content
source must reflect two main considerations: how fast changes in the
content source need to be reflected in your index and the rate at which
changes occur at the content source. This is why, for example, you might
crawl the company announcements folder every 4 hours but crawl http://archive only once every quarter.
So, crawl scheduling and
priority are two reasons for creating a unique content source. Other
reasons could include the need to define a scope based on a content
source, unique crawl settings for depth and hops to off-site links, and
crawl management.
In environments where
security is important, occasionally content is sometimes inadvertently
placed on websites with wider access than the material should be given.
When this “spillage” material is removed, a full crawl must be run to
prove that the material is not duplicated elsewhere and that the
information is completely removed from the index. Dividing the content
to be crawled into smaller content sources reduces the overhead of a
full crawl.
