2. Creating and Managing Crawl Rules
Crawl rules allow you to
configure include/exclude rules, specific security contexts for crawling
that are different from the default content access account, and the
explicit path for the rule.
Crawl rules are global
to the search service and are relative to the target address, not a
content source. For example, you can have two content sources: one each
for http://SharePoint Server 2010/sites/IT and http://SharePoint Server 2010/sites/HR.
Both can be covered by one crawl rule with a path of http://SharePoint
Server 2010. You can also specify a crawl rule for a subset of a content
source, such as http://SharePoint Server 2010/sites/HR/Records, if
http://SharePoint Server 2010/ was the listing in the content source.
To manage existing crawl rules or create new ones, click the Crawl Rules link in the Quick Launch area (refer back to Figure 1), which opens the Manage Crawl Rules page shown in Figure 4.
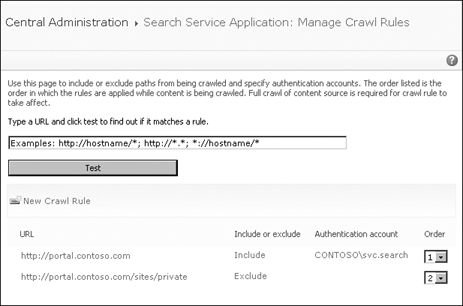
Crawl rules are applied in
the order listed on the Manage Crawl Rules page. The Exclude rule
overrides some content addressed by the Include rule that is applied
first.
Often it is necessary for
search administrators to omit only specific data that matches certain
patterns from targets to either improve search results or to protect
confidential data from being included. For example, typical items that
should not be indexed are social security numbers, credit card
information, or URLs with a specific parameter. Other types of
information that is normally not crawled are Web pages outlining the
site’s privacy policies, acceptable use policies, or even the About Us
pages.
Typically administrators
create crawl rules that limit SharePoint crawlers from accessing
specific links. Crawl rules require specification of each individual URL
separately in the Exclude list via Central Administration. However, if
you use a wildcard search such as \\servername\webfolder\* you could
keep the Exclude rule set small and prevent unwanted documents from
being included in search results.
Starting in SharePoint
2010, crawl rules allow the user to match URLs using regular (regex)
expressions. Now administrators can determine inclusion or exclusion
based on regex expression syntax.
Note:
MORE INFO More information about the regex expression syntax can be found at http://www.regular-expressions.info/reference.html. It is important to fully test all regex expressions.
Table 1 shows some examples of regex queries SharePoint 2010 supports.
Table 1. Regex Expression Examples
| REGEX EXPRESSION | DESCRIPTION |
|---|
| \\fileshare\.* | Match all files under the filesystem share \\fileshare. |
| \\fileshare\((private)|(temp))\.* | Match all files under fileshare that are named either private or temp. |
| http://site/default.aspx[?]ssn=.* | Match all links that have the parameter ssn= in the URL path. |
| http://site/default.aspx[?]var1=1&var2=.* | Match all links that have a var1 specified and var2 matches anything. |
Regex
expressions enable crawl rules that require less administrative
maintenance and provide a well-defined, dynamic set of rules that cover
existing and future content. However, regular expressions cannot be used
in the protocol component of the URL. Compare the following two regex
URL expressions.
To create a new crawl rule from the Manage Crawl Rules page, perform the following steps.
Click the New Crawl Rule link, which opens the Add Crawl Rule page shown in Figure 5.
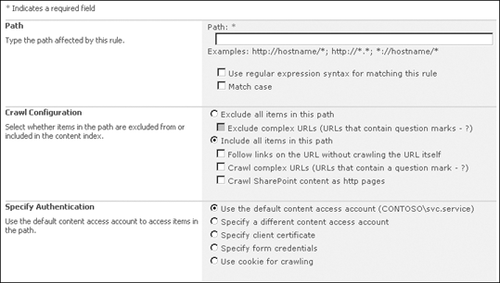
Choose
the path using regex expressions if needed. When you use regular
expressions, you must select the Follow Regular Expression Syntax
option. By default, the syntax of the regex expression and URL are case
insensitive. If the target content is case sensitive, select the Match
Case check box.
Choose
whether to exclude or include items that match the pattern. If you
select Include All Items In This Path, you also have the following
options.
Follow Links On The URL Without Crawling The URL Itself This option is useful when the starting point of a crawl is a menu of links and you don’t want the menu page in your index.
Crawl Complex URLs
If you want to crawl content defined by a string after a ’?’, select
this option. Complex URLs are common with SharePoint and also often
point to information contained in databases. In many cases, it is useful
to enter a global rule to capture all complex URLs: http://*/* and check Crawl Complex URLs.
Crawl SharePoint Content As HTTP Pages
The SharePoint connector includes security and versions. For anonymous,
public-facing sites, the overhead of including this information is not
necessary.
You can specify unique
authentication using a crawl rule. In some instances, this is the only
reason for the crawl rule, because it is the only way to override using
the default content access account. Simply enter the user name and
password to access the resource. You can also restrict Basic
authentication. This account is not a managed account, so the password
must be changed manually. This process should be documented in your
search-and-indexing maintenance plan as well as in your disaster
recovery plan.
You can specify a client
certificate for authentication, but the certificate must first exist in
the index server’s Personal Certificate Store for the local computer
before it will show up in the selection list.
Note:
The crawler will be able to index Information Rights Management (IRM) files stored in SharePoint. However, to index IRM files in other storage, the certificate for the crawler account must have read permission on the files.
Crawl rules also support forms-based authentication (FBA)
and cookie-based authentication unless the FBA has complex
authentication pages that change content without refreshing the page or
that require entries or selection based on content appearing on the
page.
One of the most
frustrating aspects of building a usable index is ensuring that
unnecessary or outdated content is not crawled by SharePoint. Taking the
time to carve out portions of a website or file server to be indexed
takes skill, testing, and patience.
What you want to do is to
visit the content source and become familiar with it. Connect to the
site or file share using the default content access account so that you
can understand exactly what the crawler will see. Try to open a random
set of files or Web pages to see if there are any security problems.
Look at the site and determine what information you don’t want to appear
in the index. Then note the paths and build your crawl rules accordingly.
Be sure to test your rules in a
lab environment to ensure that your crawl rules are working correctly.
Although most organizations will not take the time to ensure that their
index is clean, experience has shown that those who take the time to
build a targeted index to meet the needs of their users will have a
better, more robust deployment.
