The performance of an Exchange Server 2003 server
depends upon the efficiency of general server processes, such as memory
and processor operation, in addition to the processes specific to
Exchange. Troubleshooting server health involves interpreting the values
of the appropriate counters recorded in a performance log and taking
action as required. If you suspect that a fault is occurring that could
result in an unusually high or low counter reading, you can set
thresholds to trigger an alert. The alert could in turn initiate logging
of other counters.
Loss of data is a very serious
matter in an Exchange organization, and you need to be proactive in
troubleshooting data storage to prevent a disaster. If a disaster does
occur, you need to have confidence that your data recovery process is
operating correctly. If your servers are clustered to provide failover
or load sharing, then you need to have procedures in place to ensure
that those clusters are operating correctly and to repair any failures
before they affect your users.
Troubleshooting Server Health
In this lesson, you learn the significance of the results
obtained and the action that you can take when these results indicate a
problem.
You can also set up
alerts to indicate when resource usage or a performance counter exceeds a
critical limit. There are many counters and instances of counters in an
Exchange Server 2003 server. The following are among the most commonly
used to diagnose problems with server health:
Memory\Pages/sec
This counter indicates the rate at which pages are read from or written
to disk to resolve hard page faults. It is the sum of Memory\Pages
Input/sec and Memory\Pages Output/sec, and indicates the type of faults
that cause system-wide delays. It includes pages retrieved to satisfy
faults in the file system cache (usually requested by applications) and
non-cached mapped memory files. If the counter value increases over
time, it could indicate that memory is becoming a bottleneck. It can
also indicate “leaky” applications that use memory when running but do
not release it when they stop. Typically, the counter value should not
exceed five. A value of 20 or more indicates a problem.
Processor\% Processor Time
This is the percentage of elapsed time that the processor spends to
execute a non-idle thread. The counter is the primary indicator of
processor activity and displays the average percentage of busy time
observed during the sample interval. It is quite normal for this counter
to reach 100 percent. However, a value in excess of 80 percent averaged
over a period of time indicates that the processor may be overloaded.
If you have a symmetrical microprocessor (SMP) computer, then each
processor is monitored as an instance of this counter. If you discover
high readings for one processor and low readings for another, then you
should use Task Manager to discover what processes have a hard affinity
to the first processor.
Process\% Processor Time
This indicates the percentage of elapsed time for which all of the
threads of a process used the processor to execute instructions. An
instruction is the basic unit of execution in a computer, a thread is
the object that executes instructions, and a process is the object
created when a program is run. Because there are many processes created
in an Exchange Server 2003 server (or any server), there are many
instances of this counter (for example, store). Use the counter
instances to keep track of key processes. There is no “correct” value
for this counter. You need to establish a baseline for normal operation
and compare your current readings against this. If the processor time
used by a particular process increases over time, you need to judge
whether there is a problem with the process or whether this is normal
behavior that indicates that you may eventually need to upgrade the
processor.
MSExchangeIS\RPC Requests
The MSExchangeIS object represents the service that allows access to
mailbox and public folder stores. Remote Procedure Call (RPC) Requests
is the number of client requests that are currently being processed by
the information store. The RPC protocol is used to transfer messages
between computers and across connectors. You need to look at the value
of this counter, together with the readings for MSExchangeIS\RPC
Packets/sec (the rate that RPC packets are processed) and
MSExchangeIS\RPC Operations/sec (the rate that RPC operations occur) to
determine whether there is a bottleneck in the system.
PhysicalDisk\Disk Transfers/sec The
value in this counter indicates the rate of read and write operations
on a physical disk. A physical disk can contain several logical disks or
volumes. Conversely, if disk arrays are used, a logical disk can
contain several physical disks. You can add this counter to a
performance log, but you will get a value of zero unless the disk
counters are enabled using the diskperf command-line utility. Do not
enable disk counters unless you have a problem that you need to solve,
and do not enable them for any longer than you must. Enabling disk
counters can seriously degrade server performance.
SMTP Server\Local Queue Length
This indicates the number of messages in the local queue on an SMTP
server. You can get the same information from Queue Viewer, but a
performance log lets you view a report over time and track trends. You
should look at this counter in conjunction with the SMTP Server\Messages
Delivered/sec counter, which indicates the rate at which messages are
delivered to local mailboxes. It is possible that there are a lot of
messages in a queue, but the queue is being processed at a rate
sufficient to ensure that the messages are delivered promptly. You can
also set alerts on counters such as SMTP Server\Badmailed Messages (No
Recipient) so that you are warned if an excessive amount of anonymous
mail is delivered, possibly indicating spamming or a Denial of Service
(DoS) attack.
MSExchangeIS Mailbox\Local Delivery Rate
This is the rate at which messages are delivered locally. The
MSExchangeIS Mailbox object counters specifically measure mailbox, as
opposed to both mailbox and public folder, traffic. Other counters that
you might need to monitor are MSExchangeIS Mailbox\Folder Opens/sec,
which is the rate that requests to open folders are submitted to the
Information Store, and MSExchangeIS Mailbox\Message, which is the rate
that requests to open messages are submitted to the information store.
You need to compare these counter values against performance baselines
to determine whether a bottleneck exists and to track trends over time.
Troubleshooting Data Storage
With the exception of
RAID-0, the failure of a disk in an array is not always immediately
obvious. It is possible to generate an alert if a counter such as
Physical\Disk Transfers/sec drops to zero, but this would necessitate
having the disk counters enabled (and may be a good reason for enabling
these counters). You can also configure Monitoring And Status in
Exchange System Manager to write an event to the application log in
Event Viewer if free disk space in the array falls below a predefined
limit, and you can configure Notifications in the Monitoring And Status
tool to notify you by e-mail or by some other method specified in a
script file when the event occurs. This will alert you if there are
capacity problems, but will not indicate a disk failure in an array
because the loss of a spindle in an array does not affect free disk
space.
However,
it is important that you deal with a disk failure immediately because
your array is no longer fault-tolerant. If you are using RAID-5, then
the loss of a spindle will result in noticeable performance degradation;
basically everything slows down. In RAID-1 and RAID-0+1 arrays,
however, the degradation in read performance may not be immediately
noticeable, especially during quiet periods. Commercial hardware RAID
systems can generate visual and audible warnings of disk failure, and
you should take this functionality into account when choosing a system.
Mailbox and Public Store Policies
You can create mailbox
and public store policies for any administrative group by expanding the
administrative group in Exchange System Manager, right-clicking System
Policies, and then specifying either a new mailbox or a new public store
policy.
These procedures
help to troubleshoot storage, because problems can occur when databases
grow too large. Enforcing mailbox limits can prevent such problems.
Proactive troubleshooting—that is, preventing problems from occurring—is
the hallmark of the efficient administrator.
Troubleshooting Clusters
When a cluster node goes
down and failover occurs, it is not always immediately obvious that you
have a problem. You need to use Cluster Administrator on a daily basis
to check the health of your clusters.
One of the main problems
when using clusters is virtual memory fragmentation. You need to
monitor the following virtual memory counters for each node in the
cluster to determine when an Exchange virtual server must be restarted
due to this fragmentation:
MSExchangeIS\V Largest Block Size When
this counter drops below 32 MB, Exchange Server 2003 logs a warning in
the Event Viewer application log (Event ID=9582). It logs an error if
the counter drops below 16 MB.
MSExchangeIS\VM Total 16MB Free Blocks
You should monitor the trend on this counter to predict when the number
of 16-MB blocks is likely to drop below three. When this number drops
below three, you should restart all the services on the node.
MSExchangeIS\VM Total Free Blocks
This counter enables you to calculate the degree of fragmentation of
available virtual memory. The smaller the average block size, the
greater the fragmentation. You also need the value returned by the store
instance of the Process\Virtual bytes counter. The average block size
is the Process (store)\Virtual Bytes value divided by the
MSExchangeIS\VM Total Free Blocks value.
MSExchangeIS\VM Total Large Free Block Bytes
If the value in this counter drops below 32 MB on any node in the
cluster, failover the Exchange virtual servers, restart all the Exchange
services on the node (or restart the server), and then failback the
Exchange virtual servers.
Troubleshooting Backup and Restore
An online backup uses a checksum to check files for corruption and
writes events to the application log of Event Viewer if any
inconsistencies are found. In addition, a backup log is generated. Thus
if an online backup runs with no errors recorded, you can have a good
degree of confidence that the data has been backed up correctly.
Sometimes an offline
backup is necessary, either when an online backup fails or when
third-party software is used that does not support online backups. In
this case, you can use the eseutil command-line utility with the /k
switch to verify the backup copy.
No matter how confident you
may be about your online backup, it is wise to perform a practice
restore. You can perform a practice restore on a recovery server, which
is also used to recover deleted mailboxes after their retention periods
have expired. A recovery server needs to be in a separate forest. You
can also restore on the same server, or on a server in the same
organizational group, by using a recovery storage group.
Recovery Storage Groups
A
recovery storage group is a specialized storage group that can exist
alongside the regular storage groups in an Exchange Server 2003 server
(even if the server already has four normal storage groups). You can
restore mailbox stores from any normal Exchange Server 2003 storage
group to the recovery group. You can then, if appropriate, use the
exmerge command-line utility to move the recovered mailbox data from the
recovery storage group to the regular storage group.
Recovery storage
groups allow you to restore without overwriting the data in the stores
you backed up. This is important when you suspect there may be a problem
with backups and you do not want to risk overwriting your current data
with corrupted backup data. In addition, you can recover an entire
mailbox store (all of the database information, including the log data)
or just a single mailbox.
If you have confidence
in your backup and restore processes, then backup becomes a
troubleshooting tool rather than a troubleshooting problem. You can
restore the last full backup and, when appropriate, the last
differential backup or series of incremental backups. You can then
replay any transaction logs that are stored on a separate disk to
restore the data on up to the point of failure.
Practice: Configuring an Alert
In this practice, you
configure an alert that triggers if 20 or more messages are waiting to
be sent out from the Server01 mailbox. In your test network, this number
is an arbitrary choice. On a production network, you would use a
performance log and monitor Queue Viewer to create baselines for normal
and busy periods. The number of queued messages that you choose to
trigger the alert should be higher than the highest anticipated number
during busy periods, and therefore indicate a fault in the messaging
environment.
Exercise 1: Configure a Queue Alert
To configure a queue alert, perform the following steps:
1. | On Server01, open the Performance console.
|
2. | Expand Performance Logs And Alerts, right-click Alerts, and then click New Alert Settings.
|
3. | In New Alert Settings, in the Name box, type Send Queue Alert and then click OK.
|
4. | On the General tab of the Send Queue Alert dialog box, type Alert if 20 messages, and then click Add.
|
5. | In
the Add Counters dialog box, in the Performance Counters drop-down
menu, select MSExchangeIS Mailbox. In the Select Counters From List box,
select Send Queue Size (normally selected by default), and in the
Select Instances From List box, select First Storage Group–Mailbox Store
(SERVER01), as shown in Figure 1.
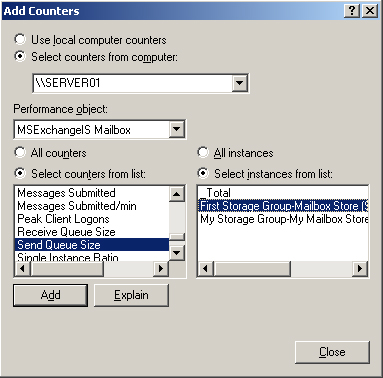
|
6. | Click Add to add the counter, and then click Close.
|
7. | In the Alert When Value Is box, select Over.
|
8. | In the Limit box, type 20.
Tip The
Alert When Value Is box can be set only to Over or Under. Therefore,
Over means “greater than or equal to,” and Under means “less than or
equal to.” So if you want the alert to trigger at 20 messages, you set
“Over 20.” If you did not know this, you might assume that “Over 19”
would trigger on 20. Examiners sometimes test areas where the intuitive
answer is not the correct one. |
|
9. | Ensure that the sample interval is at the default value of 5 seconds. Figure 2 shows the alert settings.
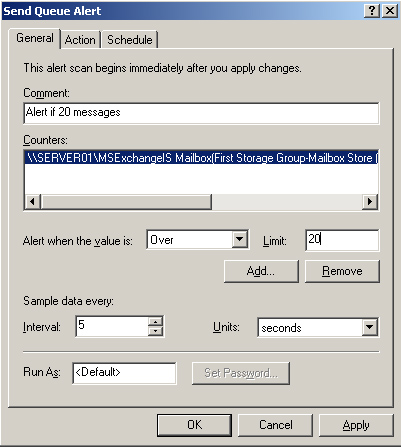
|
10. | On the Action tab, select Send A Network Message To and type Administrator in the associated box.
Note This
sends a network message to any PC (assuming it has a Windows NT,
Windows 2000, Windows Server 2003, or Windows XP operating system and
the messenger service is enabled) where you are logged on using the
Administrator account. You might want to consider sending messages to
the ordinary user account that you created for yourself according to the
Principle of Least Privilege. In a production network, you should log
on using the Administrator account as seldom as possible. Also note that
by default an event is logged in the applications log in Event Viewer,
that you can start a performance log if an alert is triggered, and that
you can run an executable file. This file could send you an e-mail
message or, if you have the appropriate technology installed, could
trigger a personal bleeper. |
|
11. | Click OK.
|
12. | In
the Performance console, click Alerts. In the details pane, right-click
the alert and confirm that it has started (Start is unavailable).
|
Warning
You
can also determine that an alert is running because it is green, but
this method is not infallible. A newly created alert may be started but
appear as red until the first time you click it. Also, those who are
prone to color blindness easily confuse red and green. |
