5. IPv4 to IPv6 Transitional Techniques
Obviously, the entire
networking world cannot shift from one networking scheme to another
overnight. There are billions upon billions of networking
address-bearing devices floating around to this day, and a good share of
these devices are commonly used for legacy business operations and will
most likely never
be able to understand new networking technology. As of 2008, the year
of the release of the MCITP Enterprise Administrator exam, IPv6 hasn't
come into popular use. However, over the next several years it's
possible that this will become more relevant. Thus, the next section
will become valuable as administrators learn techniques to handle the
dramatic shift from IPv4 to IPv6. For now, you are interested in three
methods: dual stacking, tunneling, and translating.
5.1. Dual Stacking
The simplest of the
transitional techniques designed to transition from IPv6 to IPv4 is the
idea of a dual IP stack. In a dual IP stack, you operate both an IPv4
address and an IPv6 address. In Microsoft Windows Vista and Microsoft
Windows Server 2008, this option is enabled by default. With dual
stacking, using the ipconfig command will display both a hexadecimal address and an IPv4 address.
The reason that this is
possible is that addresses are logical. So, there's no reason that a
computer couldn't be logically identified two different ways. In
practical implementation, this is done by one of two ways—by using a
dual IP layer or by using a complete dual stack.
Dual IP layer
In dual layer addressing,
both the IPv4 and IPv6 protocols access the same information in the same
TCP/IP stack. This means that the network portion contains both the
IPv4 and IPv6 implementations, and they both access the same transport
layer. So, regardless of whether a packet is sent via IPv4 or IPv6, it
passes through the same area. This technology is supported by Windows
Vista and Windows Server 2008.
NOTE
Dual IP layer supports IPv4, IPv6, and IPv6 over IPv4.
Dual stack
Dual stack
implementations differ from dual IP layer implementations in that dual
stack creates a complete separate stack through which each protocol
travels. What this means for network administrators is that routers will
have to support both the IPv6 and IPv4 protocols. And, of course, each
of these stacks has its own transport layer that interfaces with the
application layer. By default, if you install IPv6 support for Windows
XP and Windows Server 2003, both of these operating systems will use a
separate stack, where the settings will be defined by tcpip6.sys.
Both dual stack and dual layer
implementations get a little tricky when you start to throw in the
confusing factor for any normal and well-functioning network: DNS.
5.2. Tunneling
If you've ever set up a VPN connection before, you've used a type of tunnel. Tunneling
is the process of placing a protocol or piece of information within
another protocol that serves as the primary method of connection. With
VPNs, when you use Point-to-Point Protocol (PPP) to connect via the
Internet to your internal network, you're using the VPN as a tunnel to
transmit data via TCP/IP, where the server sees you as remotely
connected across the network.
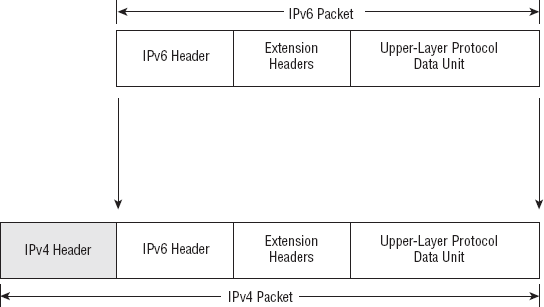
When working with IP
transitional tunneling, you're doing something very similar. In effect,
you're taking IPv6 information and passing it through IPv4 by adding on a
header. Visually, an IPv6 over IPv4 packet looks like Figure 11.
This can be achieved by one of
two ways, each with many different customer configurations. First, it
can be achieved by manual configuration. And second, it can be achieved
automatically. Configured and automatic tunnels can be configured in
many different ways; in particular, the manually configured tunnels can
be configured by using the netsh interface ipv6 add v6v4tunnel command. And automatic tunnels can be configured by using one of three different technologies: 6to4, Teredo, or ISATAP.
5.2.1. Tunneling Between Devices
As you know from basic
networking, every device that sends a packet from one place to another
exists in some manner on the network layer. Accordingly, every device
that is connected on the network layer is logically connected in some
fashion. Thus, every host and router (both of which are capable of
understanding the network protocol) must have a way of communicating
with one another. However, this varies with each device. In a tunnel,
this breaks down to three types of communication between devices:
Router to router
When tunneling
between routers, two routers capable of both IPv6 and IPv4 communicate
to one another by referencing a network behind each of the routers that
operates on IPv6 and then send packets to one another across a tunnel
that operates IPv4 with IPv6 packets embedded within. Figure 12
depicts this communications process. On the left side of Router A,
there is an IPv6 network, and on the right side of Router B, there is
also an IPv6-capable network. These two devices are connected via IPv4,
and the messages sent between them contain IPv6 packets within IPv4
packets.

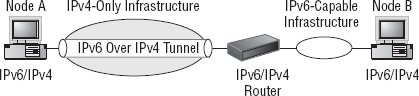
Host to host
When two hosts running both
IPv4 and IPv6 stacks in an IPv4 infrastructure communicate, IPv6
information can be sent between the two by creating a tunnel that sends
IPv6 over IPv4. Since the two computers both understand the different
stacks, the IPv4 information is interpreted and the internal information
is recognized, forming a connection that allows them to communicate.
Router to host and host to router
When operating
between hosts that reside between firewalls or routers, a host running
IPv4 can communicate between infrastructures operating different IP
protocols by creating an IPv4 tunnel containing IPv6. The way this is
accomplished is that the routers again understand both protocols, IPv4
and IPv6. And when an IPv4-capable computer sends a request to the
router with an IPv6 packet embedded inside a tunnel that is usually a
subnet route, the router receives the IPv4 packet, examines the internal
IPv6 packet, and then forwards that packet onto the IPv6 host computer
running in an IPv6 infrastructure. In Figure 13,
on the left side of Router A is an infrastructure running IPv4, and on
the right is a network operating IPv6. The left network can communicate
to the right by using a tunnel to the router, which the router
recognizes as a tunnel and then examines the internal contents.
6to4
6 to 4, much as it sounds, is a
direct method of transitioning from IPv6 to IPv4 over the IPv4
protocol. 6to4 accomplishes this by implementing both stacks of the IPv4
and IPv6 protocol and then translating the given IPv4 address into a
standardized address for IPv6. This is done by inserting the given IPv4
address in this format—129.118.1.3—into the hexadecimal form:
2002:AABB:CCDD:Subnet:InterfaceID
AA is the first octet, BB
is the second octet, CC is the third octet, and DD is the fourth octet.
The subnet portion is the standard /48 to /64 subnet range, and the
interface ID is the 64-bit portion of IPv6 dedicated to the host.
In this example, you could
convert the portions of the decimal address into hexadecimal by using
some simple math, which I won't dive into because you've most likely
learned it by this point:
129 = 81
118 = 76
1 = 1
3 = 3
Thus, your full address would be as follows:
2002:8176:13:Subnet:InterfaceID
Within 6to4 tunneling, the
entire subnet is treated as a single link. Hosts are automatically given
their 2002:AABB:CCDD:Subnet address with a /64 mask, and then
communication within the subnet is given directly to neighbors. If, for
some reason, the given address is not found on the subnet, that
information is passed onto a 6to4 router that exists on a /16 mask by
default.
|
A Windows Server 2008 or Windows Vista computer can act as a 6to4 router through Internet Connection Sharing (ICS).
|
|
5.2.2. ISATAP
ISATAP, which stands
for Intra-Site Automatic Tunnel Addressing Protocol, is an automatic
dual stacking tunneling technology that is installed by default in
Windows Vista without
Service Pack 1, Windows Server 2003, and Windows XP. However, in
Windows Server 2003 and Windows XP, it is called Automatic Tunneling
Pseudo-Interface. The ISATAP tunneling method can be used for either
public or private addressing. With public unicast addressing, ISATAP
uses this global address:
::5EFE:A.B.C.D.
A.B.C.D. in this case is a
standard IPv4 address that is assigned within the IPv4 infrastructure.
Additionally, ISATAP uses the private address of ::200:5EFE:A.B.C.D. where A.B.C.D. is again the assigned IPv4 address within the infrastructure.
By this method, ISATAP creates a
link-local address that can be used to communicate between devices
through tunneling. An important feature to note, however, is that ISATAP
is not installed by default on either Windows Vista Service Pack 1 or Windows Server 2008 unless the name "ISATAP" can be resolved.
ISATAP allows computers
operating IPv6 in IPv4 infrastructures to communicate with IPv4 clients
in the same subnet. However, to communicate with additional subnets
running either pure or mixed IP protocols, an ISATAP router is required.
Normally, this router is resolved either through the mapping of the
"ISATAP" hostname or by the use of the netsh interface isatap set router command, which allows the address of the router to be manually specified in either Windows Server 2008 or Windows Vista.
5.2.3. Teredo
As mentioned earlier, one
of the primary goals with the implementation of IPv6 was to enable
almost all organizations to use publicly assigned addresses throughout
their entire organization without the use of Network Address
Translation. Although this is good in theory (NAT was such a pain
anyway), the problem is that NAT is still used...a lot.
Therefore, to make the shift from IPv6 to IPv4, network administrators
need to have an option at their disposal to shift from IPv4 to IPv6 and
still make use of NAT or at least give the network the ability to
interpret between these addresses. And that's where Teredo comes in.
Teredo is also known as
Network Address Translator Traversal (NAT-T). What it does is provide a
unicast address for each device located within the NAT pool. It does
this by sending out IPv6 data over Uniform Data Protocol (UDP). In some
ways, it's actually fairly similar to 6to4 tunneling. However, if you'll
remember from the earlier discussion of 6to4, 6to4 requires a router to
be used that comprehends 6to4 routing in order to get past its
particular subnet. Instead of using a router to translate out the NAT
pool, Teredo uses host-to-host communication and establishes a tunnel
directly between two individual hosts.
For your exam, the most
important point you need to remember about Teredo is the process it uses
for the initial configuration and communication between clients. Beyond
that, Teredo is quite complex and uses a series of XOR operations to
determine a unique address; then it also creates a randomly generated
series of numbers and a flag field for security purposes. So, it's
unlikely you'll be asked to manually configure a Teredo address.
However, the process breaks down into two portions: initial client
configuration and initial client communication.
The client sends a router solicitation request (RS) to a Teredo server with the cone flag (a high-order bit that indicates a device is behind a NAT) set.
The
Teredo server responds with a router advertisement (RA) from a router
that is on an alternate IPv4 address so it can determine whether the
address is behind a NAT.
If the RA is not received, the client repeats the RS with the cone flag not set.
The
server responds with an RA from the source address to the destination
address. If the client receives the RA, it is behind a restricted NAT.
To make sure there isn't a symmetric NAT in place, the client sends another RS to an alternate server.
The
alternate server responds. If the RAs are different, the map is mapping
the same internal address and UDP port number, and Teredo will not be
available.
Teredo has several
different processes of initial communication based on what type of NAT
the client is assigned under. The most commonly referenced one of these
is a situation where a client resides on a restricted NAT. In which
case, the process of two computers, A and B, communicating is as
follows:
Client A sends a bubble packet to Client B.
Client A sends a bubble packet to Client B through Client B's Teredo server.
Client B's Teredo server forwards the packet to Client B.
Client B responds to the packet with its own bubble packet to Client A.
Client A determines NAT mappings for both NATs.
6. Legacy Networking and Windows Server 2008
Although it would be nice if
we existed in a world where all technology was upgraded instantly at
the same time and there were never any issues switching back and forth
between technologies and we could just link with IPv6, that world simply
doesn't exist. In fact, even before IPv4 and the current networking
situation, the world of networks wasn't exactly laid out in perfect
order.
To this day, there are many
protocols that aren't used as often as others but that occasionally rise
to make their presence known and require special attention from
administrators who otherwise no longer encounter them. On the MCITP
level, you actually encounter these sorts of scenarios frequently. This
is because most complex networks will contain a lot of different
technologies that mutually cohabit (or at least coexist) in the same
environment. Because of this, Microsoft expects that all candidates
applying for MCITP-level certification completely understand how to deal
with even the most obscure networking protocols and understand their
effect on their networking environment.
In the following section, I'll begin by explaining the most commonly encountered protocol: WINS.
6.1. WINS
In some ways, I've
already addressed legacy technology at some level, but now you're going
to dive into a concept that isn't used as commonly anymore and will
probably go the way of the dodo after this incarnation of Windows
Server, or possibly after the next incarnation. In case you hadn't
guessed, I'm talking about Windows Internet Name Service (WINS).
6.1.1. Wins Components
When using WINS, generally four components are available to administrators using Windows Server 2008:
Server
WINS database
Client
Proxy
Each of these roles in
self-explanatory by its name; the server serves WINS, the WINS database
keeps a collection of records, the clients request WINS information, and
the proxies provide resolution for WINS in TCP/IP configured networks.
6.1.2. Reasons for WINS
Normally organizations won't implement WINS without a valid reason. Among these reasons are the following:
Additionally, an organization may
implement WINS if it is running logically older versions of Windows or
applications requiring older versions of Windows, which include anything
using Network Neighborhood or My Network Places.
6.1.3. WINS Name Resolution
The WINS name
resolution process is pretty easy to understand. First, any given client
sends up to three attempts to connect to a WINS server, but no response
is given. If no response is given, it will attempt to find another. If
it does, the WINS server responds with a given IP address.
6.1.4. Client Records
Within the WINS database,
various pieces of information are stored that in total create the
necessary components to resolve names to IP addresses, which is the
given purpose of any general name resolution server. Within WINS, client
records contain the following:
Record names
IP addresses
Types
State
Static
Owner
Version
Each of these records within the database is occasionally changed, deleted, or somehow modified through a process called scavenging.
6.2. WINS Replication
Just like Active Directory, a
WINS server knows very little about the world around it. In fact, it
knows nothing about it. And, just like Active Directory, in order to
understand the world around it, WINS uses replication to exchange
information about its clients. However, in WINS, this process is called push/pull.
The push occurs after a certain
server reaches a number of specified changes. For instance, a server
may reach 10 changes in its database and decide that it needs to send
its information to another WINS server. Thus, it informs the server that
it has reached a certain amount of predetermined changes and needs to
replicate, and the server that needs to understand the replication
changes responds with a request to receive the changes. The original
server then sends the changes across the subnets.
A pull replication is
essentially the opposite of a push. Instead of requesting another
machine to make a change after a certain number of events, a partner
machine will ask another if changes have occurred after a period of
time. This happens regardless of whether any changes actually have happened. And, as you might imagine, this can be combined with push to create a push/pull replication process.
6.3. WINS to DNS Using GlobalNames Zones
If an organization runs WINS,
there's a strong chance that in addition to running WINS that it is also
using DNS. The reason is because the modern standard for name
resolution is DNS. Thus, Windows Server 2008 enables a simple transition
from WINS to DNS by using a GlobalNames Zone. A GlobalNames Zone enables a WINS environment to resolve single-label, static, global names if the server is using DNS.
The GlobalNames Zone is a
completely new Windows Server 2008 zone for DNS in addition to zones
such as forward lookup, reverse lookup, and stub. It's responsible for
resolving names without WINS and requires that the zone be available on
all DNS servers. But, it's best if you place it within Active Directory.
Another special fact about GlobalNames Zones is that they use CNAME
records for fully qualified domain names.
GlobalNames Zones work in a multistep process that's pretty easy to understand:
The browser requests the address.
The
client computer tries to request domain by domain from most granular to
least (users.engineering.mydomain.com to users.engineering.com to
users.com).
If the query fails, the DNS server checks the GlobalNames Zone.
NOTE
GlobalNames Zones support IPv6.
