Everyone
expects that they’ll be able to dynamically scale their service in
Azure. Dynamic scaling is possible, but it requires some heavy lifting
on the developer’s part. Over time, vendors will provide this as a
service on top of Azure. In the meantime, you’ll want to provide some
sort of control over the amount of resources allocated to your service.
In this section, we’re going
to follow the same model that our homes use for heating and cooling. Our
homes are driven by a sensor that detects a healthy condition (is the
temperature in a pleasant range?), a mechanism to change that
temperature, and some simple rules that keep the heater from running for
24 hours straight. We can take this approach and apply it to a cloud
service. We’ll instrument the cloud service with
the diagnostic engine, use the management API to control the
infrastructure, and provide some code to control how all that works. You
want to respond to events and keep your system healthy so you don’t
come in on Monday to find that you have 1,500 instances running in the
cloud.
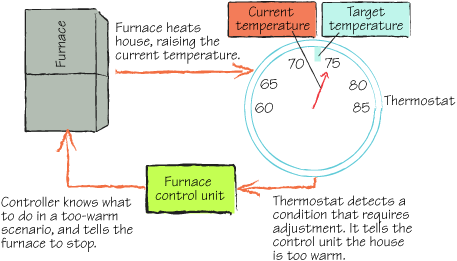
In keeping with our heating and cooling metaphor, let’s start with the thermostat.
1. The thermostat
The thermostat in your home is a
simple component of a common control system. Other examples include the
cruise control in your car, the autopilot in a plane, and many
manufacturing systems. Each of these systems has three components.
The first component is the
system itself: the car, the plane, the furnace in the house. In Azure,
the system is the service you’re running. The system needs to have
inputs to be able to control important aspects of itself. In the furnace
example, you can send it a turn-on signal or a turn-off signal. These
signals cause it to generate more heat or to stop generating heat.
The second component is the
measurement or input device. This device measures the control aspects of
the system. In our house example, it’s the thermometer in the
thermostat. In Azure, the measurement might be any number of things. A
thermostat uses a simple dial to determine what the desired temperature
is, as shown in figure 1.
The hard part for systems in Azure is deciding what busy
is for the system. There’s not a simple dial, but likely an amalgam of
several inputs; perhaps the depth of a messaging queue, the number of
pending requests in the IIS queue, and the running average of response
time for each web request. Every measurement point you want to monitor
to help decide what busy means needs to be something you can measure across all your instances.
Busy is sometimes
represented as an absolute measure. For example, you could define a
concrete amount of time a response is allowed to take under normal
conditions. The system is either beneath or above that allotted time.
Some definitions for a busy state are relative in nature. Saying that
your system is busy whenever there are more than 50 messages in the
queue won’t work very long. You might instead want to measure
50 messages per instance. Then, if you have five instances, a scenario
that has 200 messages in the queue is OK. In this way, you can scale up
the definition of busy as you scale up the amount of available resources.
The last component is the
control logic itself. This is the piece that determines whether anything
needs to be done, and how it should be done.
2. The control system
Your control system has only a
few things that it can do with regard to managing performance or scale.
In general, the only things the control system can do is add or remove
instances of roles. That’s about it.
Of course, there are
plenty of scale patterns you can implement, and some will help prevent a
dramatic scale failure from happening. You’ll want to look into
shunting, bulkheads, and partitioning. Just look in one of those
enterprise patterns books on your bookshelf.
You need to instrument
your control system yourself so you know what decisions it’s making and
how. You want to be able to figure out what went wrong when your service
lumbers out of control and eats a village.
The control system can run as a
simple role in Azure or as an on-premises application. You might assume
an on-premise is a better solution, but remember that you’ll need the
input of the diagnostic logs; you’ll have to download them all the time
to make decisions. Having the control for the system running in the
cloud puts the code near the data, which makes it both faster and
cheaper.
3. Risks and managing them
A lot of risk is
associated with implementing an auto-scaling component for your service;
it’s not trivial. You’ll have to take into consideration a lot of
issues and complexities. If things go haywire, they can go haywire
badly.
On one hand, you could end up
with a large Azure bill if your code goes crazy and spins up 400
instances. On the other hand, if it fails to work properly, you’ll end
up not responding to a busy state at all, leading to lost orders and
unhappy users. Scaling requires a fine balance, and you’ll want some
protective measures in place.
In your logic, make sure you
have an absolute upper boundary in place. No matter what’s happening in
the feedback system, the scaler won’t go above this boundary. If the
scaler reaches its ceiling, it should call a human and ask for help (by
sending an email or a text message). You should set this boundary to
something that’s high enough to handle expected spikes (the big spike at
the end of month), plus 15 percent for a buffer. In addition to this
ceiling, set a floor to the scale value. You might want to make sure you
always have two instances for reliability. Of course, some applications
are OK with just a single instance, and others are OK to be completely
shut down if there isn’t any load.
At some point, the spike
that caused the controller to create all these instances will pass.
After it does, be sure that your controller starts shedding instances to
bring the amount of resources deployed back into an acceptable range
for the current load.
Pick
an algorithm that matches how your load tends to fall off. If it tends
to fall very quickly in a steep spike, then you should use an aggressive
backoff strategy. In this case, you could use a halving technique in
which for each polling cycle that the controller deems is excessive, it
cuts the amount of resources by half (going from 32 instances to 16, for
example).
In other services,
you’ll need a slower backoff process, dropping only one instance every
time the measure drops by a certain percentage. Do extensive testing on
the behavior of your controller to make sure it’s working under
stressful situations the way you want it to.
Another risk is that the
controller might flood the channel with conflicting messages. If the
polling cycle is too fast and the traffic too unpredictable, you might
end up sending conflicting messages through the channel to the service.
If you send a message to add an instance and then immediately follow it
with a message to shed an instance, you’ll end up thrashing your
infrastructure. You also don’t want to accidentally send a message to
add an instance several times when you want only one net new instance
started. To avoid this problem, make sure your controller is stateful,
tracking the commands it has sent and whether those commands have been
executed yet. You might even want to suspend all polling until the
chosen action is completed.
No matter how clever you get
with your controlling logic, make sure that you always include wetware
somehow. The controller should always have a way to notify a human as to
its behavior. If you run into the “we accidentally started up 400
instances last night” problem, you’ll likely have a “don’t have a job on
Monday” problem.
We strongly recommend that you
initially build tools that help you watch performance and easily
maintain it. Keep the decision to add or remove instances in the control
of humans, at least until you have an absolute understanding of how the
system responds to stress, and how it responds to increases and
decreases in resources.
The cloud does a great job of abstracting away the need to manage the platform, but you still need to manage the application.
4. Managing service health
Managing service health is
critical to your system. Just because the system is running in the
cloud doesn’t mean there aren’t failures and that your system doesn’t
need to be managed. You still need to manage a system in the cloud, and
you need to take into consideration all the aspects that you consider
when the system is running on-premises. The cloud doesn’t fix problems
in a bad system; it makes those problems more obvious.
As you’re building your system,
think about how you’re going to manage disaster recovery, backups, and
the ongoing health of the system. The system will be reliable within the
Azure data center where the FC can monitor it, but that doesn’t protect
you against the worst scenario: that data center gets wiped out. In
some scenarios, it might be OK to not manage the slight risk of a whole
data center disappearing. On the other hand, many companies spend a lot
of money running duplicate data centers that aren’t near one another,
just in case. You need to think about this. If you need to reduce the
risk of depending on one data center, then you have a few options. Just
to be clear: the FC
will manage the state of your system in a data center, but it won’t, at
this time, manage it across data centers. We think that in the fullness
of time, the fabric will be that powerful, but at that time it’s likely
to be renamed to Microsoft SkyNet.
If the loss to your business
isn’t likely to be great, and you can deal with a few hours downtime,
you can simply plan on redeploying to another data center in the event
of a catastrophe. You need to keep a copy of the production bits and
service configuration handy. You also need a backup of any data in the
cloud. With these in hand, you could completely redeploy to another
Azure data center in a matter of minutes to hours (depending on the
amount of data that needs to be uploaded).
If you need to
minimize downtime, you can run two copies of your service in Azure. Set
each copy with a different geographic affinity in the portal. Azure is
then forced to run each copy in a different data center. Perhaps the
first copy is running in the Chicago data center, and the second is
running in the Southwest data center. You could then use a DNS server
that is geo-aware, and have it route users to each system, based on
their location. In this situation, you’d have to replicate your data
across the two systems. One way to do so would be to run them in
complete separation, if your business processes can handle that. Then,
once a night, you could merge the data sets with a background operation.
In all of these situations,
you need to be able to understand the health of your system. One way to
do that is to use the management APIs to understand the load on your
system, and report the status in a recurring manner.
