3. Creating Filtered Indexes
With the introduction of
filtered indexes in SQL Server 2008, you can create indexes for subsets
of data. The data stored within a filtered index is restricted only to
rows meeting the WHERE clause
that you specify. Consider filtered indexes as nonclustered indexes
optimized for performance. With a smaller subset of data, retrievals
from a filtered index will be faster, storage of the index on disk will
be smaller, and maintenance of the index will cost less and happen less
frequently because writes only occur when data meeting the filter
specification is modified. The following list describes some things that
you should consider before creating filtered indexes.
Data accessibility:
When creating filtered indexes, understanding your data is even more
important. Make sure that your filtered indexes will be for subsets of
data that are meaningful for your application. If you frequently query
only Ford automobiles by the number of seating positions, then a
filtered index on number_of_seats specifying where make="Ford" might make sense. But specifying where make="GM" in that case would be silly.
Choose subsets wisely:
When deciding to create a filtered index on a subset of data, make sure
the query optimizer will find the filtered index useful. Think about
using filtered indexes to help queries that filter through unpopulated
key values or useless values that the application does not care about.
Have you ever supported an application that stopped using a particular
value in a field? The primary type of data queried used to be 1-3, but
now the new version of the application only populates and retrieves
values 5-7. Filtered indexes are useful in such scenarios because they
keep currently unused key values out of your nonclustered indexes.
Cover your queries:
Make sure the query optimizer utilizes your filtered indexes by
ensuring that they cover the intended queries. Limit the number of
includes and key columns that exist in the filtered indexes. If the
performance of your queries is fast enough just from creating filtered
indexes alone, then you may not even have to add any include columns to
those indexes. The bottom line: Make sure unused columns are not added
to your indexes.
To create a filtered index, write a WHERE clause into your creation statement. The following syntax shows how and where to do that:
CREATE [CLUSTERED | NONCLUSTERED] INDEX index_name
ON <object>(column [ASC | DESC], [,...])
[INCLUDE ( column_name [,...n])
WHERE <filter_predicate>
[WITH (relational_index_options [,...n])
One example to
demonstrate the usefulness of filtered indexes comes from an invoice
system. Companies often provide goods and services for their customers
and bill them later. These companies keep track of the invoices that
they mail their customers and often generate reports or retrieve
information pertaining to the unpaid invoices. With filtered indexes,
you can create an index that only contains unpaid invoices. Such an
index might be very useful when created on a table containing all
invoices. Imagine a collection group that queries the table a number of
times to contact customers for payment. Having a small index
specifically covering customers with amounts due will tend to make the
collection's groups queries run faster than they would if they each had
to slog through an index including all of the older, paid-for orders.
The following code is an
example of a script that creates a table and the appropriate indexes for
the scenario we've just described:
USE AdventureWorks2008
CREATE TABLE dbo.Invoice
(
InvoiceId INT IDENTITY(1,1),
CompanyName VARCHAR(200),
isPaid smallint
)
GO
CREATE CLUSTERED INDEX ix_Invoice
ON dbo.Invoice(InvoiceId)
GO
CREATE NONCLUSTERED INDEX ix_FilterUnPaid
ON dbo.Invoice(inVoiceStatus) include(companyName)
WHERE isPaid = 0
Reviewing this code, you can
see that it creates an invoice table, a clustered index, and a
nonclustered index. The nonclustered index is the filtered index that
restricts data to rows where isPaid = 0. If you want to see the indexes work, use the following code to add data to the table:
INSERT INTO dbo.Invoice
(CompanyName,isPaid)
VALUES('Apress',0),
('Apress1',0),
('Sylvester123',1)
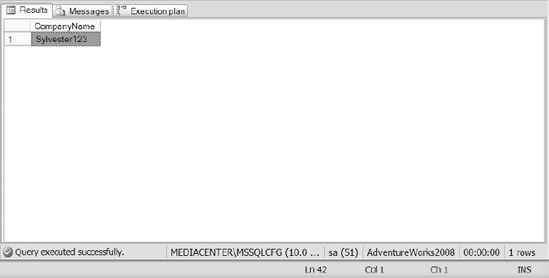
Once you have inserted the data, execute the query in Listing 1. Results of the query are shown in Figure 1.
Example 1. SQL Query Used to Retrieve Information from the Invoice Table with isPaid = 1.
SELECT CompanyName
FROM dbo.Invoice
WHERE isPaid = 1
|
To view the indexes utilized during execution of the query, turn on the option to Include the Actual Execution Plan and re-run the preceding query. Figure 2 shows the execution plan used for the query.
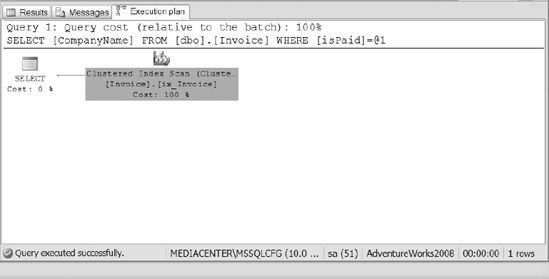
The plan in Figure 2
shows that the query executed using the clustered index on the invoice
table. The filtered index was not used because it only covers the case
where isPaid=0, not where isPaid=1.
So the index scan has to be
performed on the clustered index. Now let's see what happens when you
modify the query to retrieve data that has not been paid. Execute the
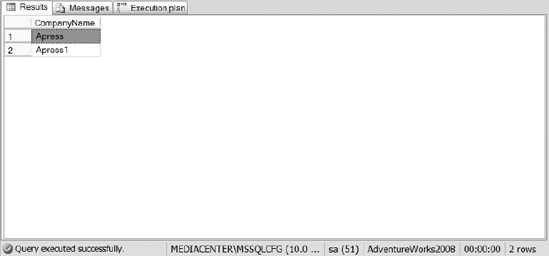
query in Listing 2 and see the results in Figure 3.
Example 2. SQL Statement to Retrieve the Invoices from the Invoice Table Where isPaid = 0
SELECT CompanyName
FROM dbo.Invoice
WHERE isPaid= 0
|
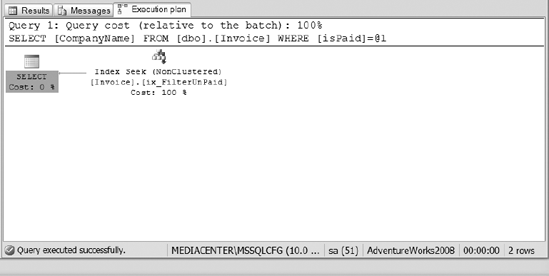
Now, review the execution plan of Listing 2, as shown in Figure 4. This time it shows that the optimizer was able to use the filtered index.
Filtered indexes can be very
powerful. Don't go crazy with them, but it's worth researching to see
whether you have opportunity to use them in your own environment.
4. Creating XML Indexes
SQL Server 2008 allows you to
create two types of indexes on your XML data types: a primary XML index
and a secondary XML index. Combined, the two index types cover the
paths, values, properties, and tags within your XML column. Before
creating XML indexes on a table, you must first create a clustered
index. The clustered index is required in XML indexes to make sure that
XML indexes can fit into existing partition schemas. Keep in mind that
XML columns are large, as large as 2 GB, and that they are stored in
binary large objects (BLOBs). If your application is utilizing XML
columns frequently, you may want to spend some time understanding how
XML indexes can benefit your system. The syntax for creating a primary
and secondary index is straightforward:
CREATE [PRIMARY] XML INDEX index_name
ON <object> (xml_column_name)
[USING XML INDEX xml_index_name
[ FOR { VALUE| PATH | PROPERTY} ] ]
[ WITH ( <xml_index_option> [ ,...n] ]
You will notice that an
option exists to specify whether you are creating a primary XML index.
When creating a secondary XML index, you simply employ the USING XML INDEX option to identify which primary XML index you are associating the index to. Then specify the FOR option to say whether your secondary index will be a value, path, or property index.
Let's create a table that
stores XML execution plans. We'll use that table as the basis for
creating primary and secondary XML indexes. Remember, we need a
clustered, primary key on the table in order to create a primary XML
index. Here's the table creation statement:
CREATE TABLE execPlans
( execPlanId INT IDENTITY(1,1),
executionPlan XML
CONSTRAINT [PK_execPlans] PRIMARY KEY CLUSTERED
(
[execPlanId] ASC
))
GO
4.1. Primary XML Indexes
You must create a primary XML
index before creating any secondary indexes. A primary XML index
arranges all tags, paths, and values of the data stored in the XML
column. A primary XML index breaks an XML string down into multiple rows
that represent the nodes of the XML BLOB. The values of the tags are
returned when the XML column is queried. Because primary XML indexes
contain the values of the tags, using primary XML indexes increases the
performance of your queries when looking for values within the XML
column.
The following example shows you how to create a primary XML index on the recently created table:
CREATE PRIMARY XML INDEX pindexExecPlan
ON execPlans(executionPlan)
GO
4.2. Secondary XML Indexes
After you have created a
primary XML index on a column, you have the option of creating one or
more secondary XML indexes on the same column. There are three types of
secondary XML indexes that you can create: path, value, and property.
The type of queries executed against the column should drive the
secondary index types that you create. For example:
Creating a path index may increase the performance of application queries searching for paths within an XML document.
A secondary index on a specific property can help queries that look at specific property values within one or more XML tags.
Create value indexes to support queries that look at specific values enclosed by XML tags.
Now, let's create a secondary
index that is a path index because we frequently look for missing index
tags within the XML string. Here is our secondary index creation
statement:
CREATE XML INDEX sindexExecPlan
ON execPlans(executionPlan)
USING XML INDEX pindexExecPlan
FOR PATH
