1. Crawling File Shares
SharePoint 2010 Search is
truly designed as an enterprise search tool. Many do not appreciate the
extensive search capabilities of SharePoint because of all its other
enterprise functionality. SharePoint 2010 has extensive indexing
capabilities, and one of the most useful is the indexing of file shares.
We have yet to encounter an organization without hoards of data stored
away on file shares. Some or all of this data may not be interesting,
and care should be taken as to what is included in an index. However, the ability to index and expose the potential treasure troves
of information locked away in these data graveyards is vast. This
section will outline how to quickly and easily set up the SharePoint
crawler to index file shares.
Like adding SharePoint
sites, setting the crawler to index file shares is done in the Add
Content Sources page in the Search service application (see Figure 1).
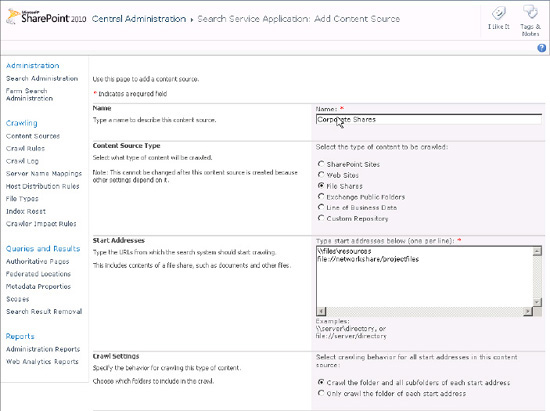
Defined paths in the Start Addresses section must be either UNC paths or paths using the file protocol (file://fileshare).
Testing the paths by mapping the drives on the server is advisable
before adding them as content sources. Make sure the crawl user has read
access to the file shares.
Crawled files may also contain
metadata that can be used by the search refiners in SharePoint 2010 or
in scopes. This metadata is usually not made available by default in
SharePoint, unlike many of the document properties in documents managed
by SharePoint in document libraries. Making sure this metadata is
crawled and mapped to managed properties in SharePoint can allow for
this metadata to be used in refiners and scopes.
NOTE
File shares are often
filled with document types that are not indexed by default by
SharePoint's crawler. Luckily, SharePoint has the ability, via the
Windows operating system, to convert and crawl text from other file
types using iFilters. iFilters can be programmed for custom file types
or purchased from third-party vendors.
2. Crawling Web Sites
SharePoint 2010 can also
crawl web sites and has a unique crawling mechanism for indexing web
content. Although SharePoint itself is essentially a very powerful web
site for portal usage, the crawling mechanism differs insomuch as the
web crawling mechanism of SharePoint 2010 has special capabilities for
parsing HyperText Markup Language (HTML) and extracting content from
HTML tags. When crawling SharePoint sites, the crawler uses a different
application programming interface (API) to collect documents and a rich
amount of associated information such as custom properties.
It is generally
recommended that SharePoint sites, even those that are used as external
web sites, should be indexed as SharePoint sites. If indexing a web site
built on some other content management system or indexing all or part
of an external web site, the web site definition should be used.
Crawling sites as web sites will limit the crawler to indexing content
retrievable on the presentation tier of the web site—that is, the web
sites as anonymous visitors will see them.
There are times when it may be
necessary or desirable to index SharePoint sites as web sites, and this
is also possible—for example, if the SharePoint site is for a public
site not owned or operated by the organization, if the site is behind a
firewall, or if the SharePoint site is based on a different version of
SharePoint and it is not possible to index it as a SharePoint site.
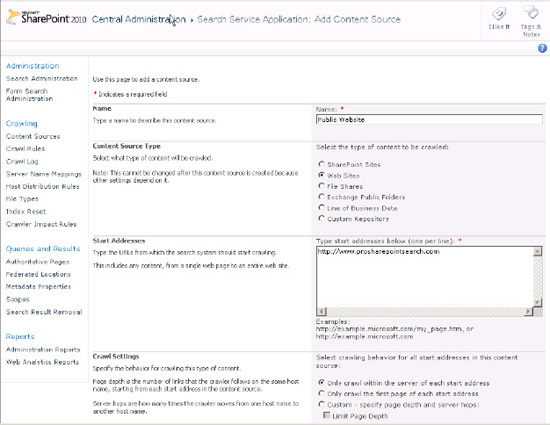
Web sites should be added by
adding the entire HypterText Transfer Protocol (HTTP) or HTTP with
Secure Socket Layers (SSL) path (HTTPS). See Figure 2.
Web sites are anything but a
standard group of items. There are nearly as many variations of how web
sites are built as web sites themselves. Even though standards exist for
HTML and web content, it is very difficult to find a site that follows
these standards. Respect should be given to browser developers for
giving end users such a rich experience, given the state of most web
sites. With that said, the argument exists that if browsers were not as
forgiving, web developers would be more careful. Most crawlers are
usually not as forgiving. This is usually due to the fact that a crawler
needs to make sense of the content it is getting in the HTML, not just
display it.
Many factors make crawling web pages tricky, including
JavaScript: Crawlers generally cannot understand JavaScript and will ignore it.
Flash: Crawlers will not index the content of Flash objects in most cases.
Images:
Web crawlers do not make sense of images outside of their metatags or
alt tags. Scanned text is a special problem—although users see text,
crawlers see only an image.
Broken HTML: Although browsers will display poorly formatted HTML, crawlers can often stumble on it.
Poor or missing metadata:
Web pages can hold metadata, and this can improve the richness of the
content. However, most content management systems do a poor job of
managing and publishing metadata. Custom sites are even worse.
Page or site-based crawl rules: Robots metatags or robots.txt files
These issues make crawling
web sites difficult and the content collected from them often not as
good as that from a SharePoint site. If the administrator has control of
the web site, correcting these issues can make the web content more
accessible to SharePoint Search as well as to global search if the site
is exposed to the World Wide Web.
